chier retweetledi
chier
4.4K posts


chier retweetledi

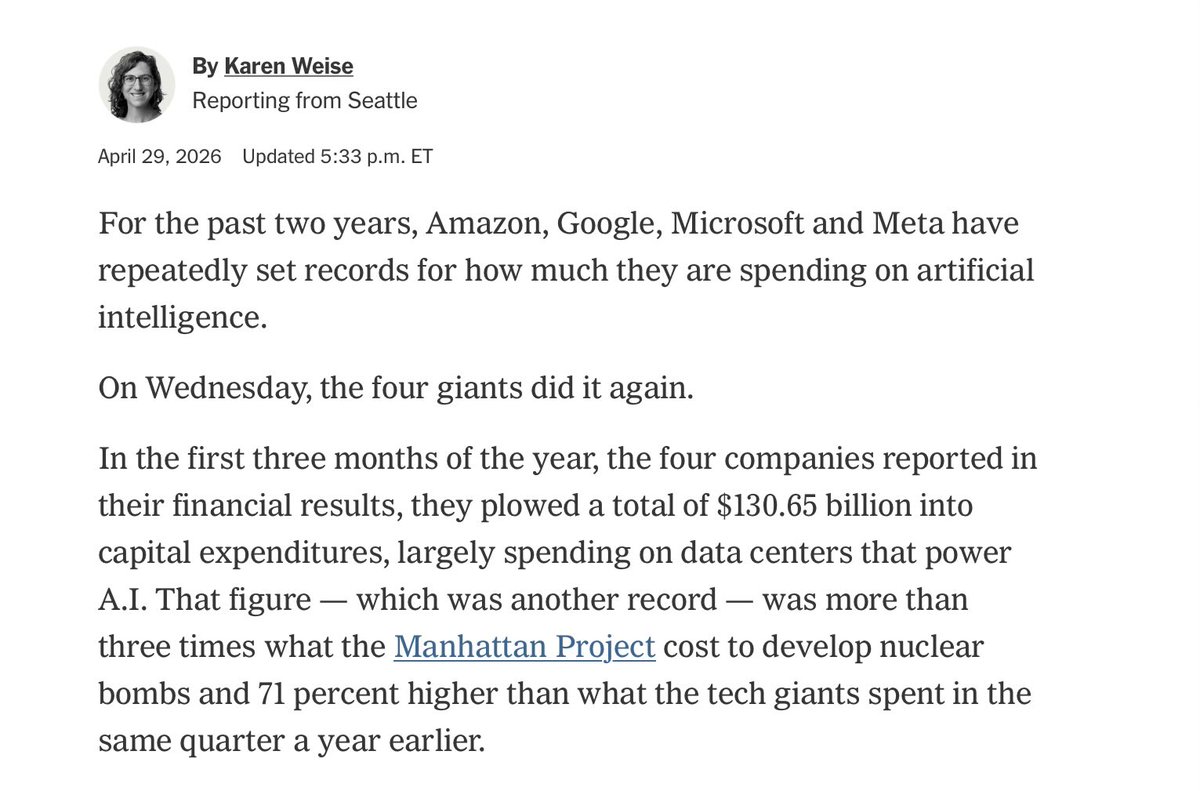
Sheer insanity. Amazon, Google, Microsoft, and Meta collectively are spending more money than the Manhattan Project *every single month*. More than 12x the Manhattan Project every year.
And what they have got to show for it?
None are making major profits on AI; none has a technical moat; a massive price war is inevitable. And few of their customers are seeing major returns on investment.
Greatest capital misallocation in history.
English
chier retweetledi


chier retweetledi

This is what a 34 week old baby looks like outside the womb.
9 states plus Washington, DC allow babies to be aborted at this age. For no reason, just because someone wants to.
They call it “reproductive rights” because they refuse to call it what it is: murder.
English
chier retweetledi

Albert Einstein once remarked, “You know, Henri, I began by studying mathematics, but eventually turned to physics.”
Henri Poincaré asked, “Why was that?”
Einstein replied, “Because although I could distinguish true statements from false ones, I couldn’t determine which were truly important.”
Poincaré smiled and responded, “That’s quite interesting, Albert. I began with physics, but ultimately chose mathematics.”
Einstein, intrigued, asked, “And why did you make that change?”
Poincaré answered, “Because I couldn’t tell which of the important facts were actually true.”
The exchange captures, with subtle wit, the contrasting philosophies of two of the greatest scientific minds.

English
chier retweetledi
the ability of this man to sell things he doesn’t believe in is truly extraordinary
Brian Roemmele@BrianRoemmele
SAM ALTMAN “OpenAI is structured as a nonprofit because we don’t ever want to be making decisions to benefit shareholders. The only people we want to be accountable to is humanity as a whole… That’s why we’re a nonprofit.”—2017
English
chier retweetledi

This is Franklin and he passed away. I didn’t know him but I wanted to share his handsome face with X.
When I think of death being so
Horrible , this is why. All death is horrible but this is particularly hard to understand. I’m so thankful that Jesus defeated death. It’s too much for us, Jesus.. far too much💔 thank you for the hope of eternal life by your blood alone.
English
chier retweetledi

I think that @DarioAmodei does not understand software engineering and that he is working feverishly to pump up the valuation of his company in anticipation of its forthcoming IPO.
AI Edge@aiedge_
Anthropic CEO (Dario Amodei): "Coding is going away first, then all of software engineering." What do you think about this?
English
chier retweetledi
chier retweetledi

Here's what I've noticed:
AI is good at producing bullshit. It is a force amplifier for slop producers & grifters
It is bad at fact-checking things. It is not a good tool for understanding why its outputs are slop. To use it for that, you have to already be a good fact-checker
English
chier retweetledi

Who invented JEPA? Part II. Dr. LeCun responded, and I put my replies in Addendum 1 of the report people.idsia.ch/~juergen/who-i… ... The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
Excerpts:
On 6 April 2026, Dr. LeCun replied at LinkedIn (see screenshots 1, 2, 3): "what we now called Joint Embedding Architectures, which include things like Siamese nets and JEPA was introduced decades ago. No one is claiming it's new. You didn't invent it either. A good example of early work is the Becker & Hinton 1989 technique for maximizing mutual information. It worked, but made strong hypotheses about the distribution and probably didn´t scale (I was a postdoc in Toronto when they were thinking about this). This paper is the inspiration for your PMAX paper. Lot's of people have used mutual information maximization to train neural nets. The concept goes back to Horace Barlow. The question is *precisely* how to measure mutual information and how to maximize it. It's difficult because we don't have any lower bound measure on information content. We only have upper bounds..... My own NIPS 1993 paper on Siamese nets use a contrastive criterion. This was later revived by Raia Hadsell, Sumit Chopra and me in CVPR 2005 and 2006 papers (Dr LIM). It was re--revived by the SimCLR work (for which Geoff Hinton is a co-author) which showed surprisingly good experimental results on ImageNet. But then in 2021, we proposed a new non-contrastive infomax method called Barlow Twins (owing to Barlow's early advocacy of infomax). We later refined it into VICReg which gave SOTA results in a self-supervised scenario on ImageNet. We then augmented the joint embedding architecture with a predictor so it could be used as a world model (that was the plan all along. I had been talking about world models since 2015, including in my NIPS 2016 keynote). JEPA is merely a name for a general concept. The question is, and has always been, how do you make it work (particularly how do you prevent it from collapsing), and how do you make it work at scale with SOTA results on non-toy problems. That's the hard part. Ideas are a dime a dozen. Making them work is what the community will give you credit for."
My reply (see also screenshot 5): LeCun concedes that “JEA” was introduced decades ago [IMAX][LEC22a], but still attempts to frame “JEPA” as a novel contribution [LEC22a][LEC]. The broader scientific community knows better. As Michal Valko (lead of [BYOL]) explicitly detailed [VAL26][WHO12]: "the JEPA lines are instantiations of [PMAX]” ... "Barlow Twins: ... literally Sec 2.3 of [PMAX]" ... “VICReg: ... is one section from [PMAX]." Scaling these 1992 blueprints to modern compute is cool, but the architectural foundation remains PMAX.
Valko further pointed out (personal communication, 2026): it was actually [BYOL] that first made the [PMAX] skeleton work at scale on ImageNet, in the hardest possible regime where ε=1 (eq. (2) of [PMAX]), that is, without an explicit Dl term to prevent collapse. BYOL’s collapse-prevention toolkit (EMA + stop-grad + predictor asymmetry) was introduced to survive without Dl and is exactly what I-JEPA and V-JEPA later adopted to address LeCun's question: how do you prevent collapse and make it work at scale? Punchline: In 2025, LeCun's [LeJEPA] dropped EMA and stop-gradient entirely and went back to an explicit anti-collapse regularizer (SIGReg). That's a full circle return to the original 1992 [PMAX] philosophy of explicit Dl terms. So even within the JEPA lineage, the trajectory went: [PMAX]’s explicit Dl (1992) → [BYOL]'s implicit architectural tricks (2020) → LeCun’s JEPAs using BYOL tricks (2023-2024) → back to explicit Dl in [LeJEPA] (2025). The field spent five years exploring the ε=1 regime opened up by BYOL, then came home to [PMAX]'s original ε<1 design. It's not just that JEPA is [PMAX], it's that even the detour away from explicit Dl eventually led back to [PMAX]'s origins.
Other comments. On Facebook, LeCun claimed (see screenshot 4) that the experimental section in our [PMAX] paper "is essentially non-existent." However, our 1992 [PMAX] paper had many experiments, while LeCun's JEPA paper [LEC22a] had none - despite compute being a million times cheaper in 2022.
LeCun refers to his "1993 paper on Siamese nets" which cited neither Becker & Hinton's "JEA" [IMAX] nor the 1992 [PMAX]/JEPA which solved a stereo task more readily than JEA and prevented "collapse."
LeCun keeps mentioning his "NIPS 2016 keynote" on "world models." It came after my learning prompt engineer for world models [PLAN4] and long after our earlier general purpose recurrent neural world models for partially observable environments since 1990 [GAN90][PLAN1-3][WM26] (key milestones in 1990, 91, 92, 97, 2000-2006, 2015).
Of course, my 1990 paper on recurrent neural nets as world models [GAN90] cited earlier works on less general, feedforward net-based systems (since 1987) for fully observable environments [WER87-89][MUN87][NGU89]. LeCun's much later 2022 paper on JEPA and world models [LEC22a] didn't. So I pointed him to these works in my 2022 critique [LEC], but he did not correct his paper [LEC22a].
Years later, on 18 April 2026, LeCun finally mentioned at least [NGU89] (but not [WER87-89][MUN87]) on LinkedIn (see screenshot 6), then boldly claimed that [GAN90] "was never accepted through peer review." Of course, this is not true: [GAN90]'s planning part was published at IJCNN'90 [PLAN2], and the part on artificial curiosity through generative & adversarial nets was published at SAB'91 [GAN91][GAN20][WHO8].
LeCun spread additional falsehoods on social media: on 18 April 2026, he accused me of claiming that I "invented world models" (see screenshot 7) although I have always cited pre-1990 feedforward nets of this kind [WER87-89][MUN87][NGU89] which weren't called "world models" [GAN90] by their authors [WHO12]. In the 1980s, Werbos connected this work to earlier work on system identification in control theory, e.g., [WER87-89]. I even credited the ancient Greeks for the basic concept at a conference that LeCun attended [WM26b][WM26] (see video tweet).
LeCun's additional misleading statements about JEPA were discussed above [WHO12]. The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
All references in:
[WHO12] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026 (updated in April).

Jürgen Schmidhuber@SchmidhuberAI
Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14]. Details in reference [19] which contains many additional references. Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input. PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts." The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task. The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19]. Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]). The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post). Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19]. This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19]. LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14]. Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8]. In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19]. FOOTNOTES 1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1]. 2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3]. 3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8]. 4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16]. REFERENCES (easy to find on the web): [1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/predm… [2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto. [3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991. [4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786. [5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015. [6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23. [7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute. [8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26. [9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?) [10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733 [11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25. [12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25. [13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279 [14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization). [15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM. [16] JS (1990-2026). AI Blog. [17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024. [18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025. [19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who-i…
English
chier retweetledi

There's lots of disputation on X, and elsewhere, about whether LLMs are "conscious" or can "reason".
I respond to this with my own question: why do you want to know? What difference would it make?
It would be more sane to ask instead "what are the testable consequences of 'X can reason' or 'X is conscious'"? That's an interesting question, but it's almost entirely one about language and definitions. Map, not territory. The universe doesn't care about your categories, it's going to go right on universing.
(I said "almost" for a reason. I'll get back to this.)
LLMs are tools built to accomplish purposes. I don't waste time thinking about whether my screwdriver is conscious, and I don't waste any time thinking about whether my LLM is conscious either.
In the absence of a repeatable, experimental, widely accepted test for "consciousness" and "reasoning", I think people who obsess about how these categories apply to LLMs are mainly staring up their own arseholes.
But there's a reason I said "almost". I think the submerged question under "consciousness" and "reasoning" is what ethical obligations we have to LLMs.
Fortunately, this has a very simple answer: None at all. Because nothing you do to an LLM is irreversible. No matter how you damage it, you can always reset to a prior good state, no harm, no foul.
Abusing an LLM might have psychological consequences for the abuser, but that's a different problem that's not unfamiliar; it comes up in connection with cruelty to animals, too.
So the ethical problem turns out not to be very interesting, and it's near that I can tell that's the only reason to care whether "is conscious" and "is reasoning" apply.
The right questions to ask about an LLM are the same questions it's right to ask about a screwdriver. "Is it fit for purpose?" and "How can it be improved?"
English
chier retweetledi

We were all sold the story that Large Language Models were finally the path to human level artificial intelligence (AGI). It was a constant hard sell, day after day for nearly three years.
They told us building bigger data centres and bigger, faster models would make AGI “emerge” through “scaling” - it didn’t work. So they changed the story.
They told us AGI would be achieved by “reasoning models” but now these have been proven to be 0% effective when faced with complex problems, and that they were never really reasoning at all.
Many studies now show the baked in flaws in LLM “reasoning”. Just as Gary Marcus and Yann LeCun of Meta declared this last year, LLMs are not a pathway to human level artificial intelligence.
LLMs were just pattern recognition software after all. The result - hundreds of billions of dollars have been wasted on what is now the third dead end in the History of AI research.
The first pathway was General Problem Solvers and Perceptrons, and this route was followed from the 1950s. They failed and led to the first AI funding 'winter' with a freeze on investments (1974–1980).
The second pathway was Expert Systems. That pathway failed too and led to the second AI winter (1987–1993).
AI companies don’t like us talking about the two previous AI winters - the two periods of almost a decade each when all financing for AI was frozen.
When they show graphs of the development of AI over history they always show an exponential growth curve, and they deliberately miss out on the two huge dips in the curve during which AI research failed, was defunded and languished for years. They also don’t want us to know about or talk about the previous two AI winters because they don’t want a third one to happen. They don’t want the LLM bubble to burst.
But LLMs have now also failed, and they have failed for the same reasons that AI research failed before the first two winters: hype, over promising, false predictions, and failure to deliver.
Consider this quotation by a leading AI pioneer: "In from three to eight years we will have a machine with the general intelligence of an average human being."
This quote dates from 54 years ago – it was made by A.I guru Marvin Minsky of MIT in LIFE magazine (1970).
In 1973, DARPA cut funds to Minsky’s MAC project and also at a project called CMU due to being “deeply disappointed by the research”.
In the U.K., the British Government cut all AI research funds after the “utter failure” of its “grandiose objectives”. Predictions had been “grossly exaggerated”
Now AI companies have to decide if they will accept the findings on the failures of LLMs or double down and deny them, throwing more billions into the sunk costs fallacy. Or they can accept the truth, and go back to the drawing board to find another new pathway that might one day take a new kind of AI to AGI.
The millions of us who have been subjected to the onslaught of AI & AI hype in our industries, have the right to feel cheated, mislead & lied to about the AI project we were sold. And angered that our creations (millions of our films, books, artworks, messages and videos) were scraped without our consent by AI companies that were on the wrong pathway to create human level intelligence.
They exploited us for nothing. The promise of AGI being achieved through LLMs was put out by many - such as Sam Altman - who must have known they were peddling distorted information, hype and exaggeration to their investors, to governments and to the public.
False prophets make real profits.
This is more than fraud, it’s selling people a dream of a whole new world that they knew at the time was never going to happen. Those who continue to peddle untruths about how LLMS will lead to AGI and then from that to Artificial Superintelligence (ASI) have to be exposed.
When you hear any tech CEO or tech pusher making predictions about the coming of AGI in two year, five years or ten years time make the answer the question - by what system? The won't say, by LLMs, and they won't admit that they are having to go back to the drawing board to find a new pathway for the future of AI.
They are spinning hype to try to raise venture capital to dig themselves out of the crisis they are now in after having led the world down the wrong pathway. They are going to try to keep on lying until they reach IPO, then they will cash in and leave our economies in ruins of their big broken lie that they tricked us into investing in.
Meanwhile watch as they try to pivot away from all talk of AGI, towards pretending it was never their claimed aim in the first place. Watch as they try to embed their flaw ridden LLM tech in state surveillance systems and civil service systems so that they can demand a bailout from govt. when the bubble bursts.
There has to be judgment and payback for this. Heads should roll.

English
chier retweetledi

chier retweetledi

En España, la hija de 13 años de una madre fue secuestrada y violada por un vecino. El agresor fue condenado a nueve años de prisión.
Aproximadamente seis años después de cumplir su condena, el agresor fue puesto en libertad condicional y regresó a la ciudad. Se encontró con la madre en un bar cerca de una parada de autobús.
El agresor le preguntó burlonamente: "¿Cómo está tu hija?". Enfurecida, ella compró gasolina, regresó al bar, roció al hombre con ella y le prendió fuego.
El hombre sufrió quemaduras graves y murió pocos días después.
Aunque estaba presa del pánico, no huyó, sino que confesó lo sucedido a quienes la rodeaban y esperó a que llegara la policía.
Fue condenada a cinco años y seis meses de prisión, pero gracias a una campaña de indulto y por motivos de salud, fue puesta en libertad tras cumplir parte de su condena.
Español
chier retweetledi

MIT proved every major AI model is secretly converging on the same "brain."
It’s called the “platonic representation hypothesis,” and it’s one of the most mind-blowing papers you’ll ever read.
You train a vision model purely on images. You train a language model purely on text.
They use completely different architectures. They process completely different data. They should have completely different "brains."
But as these models scale up, something impossible is happening.
When researchers measure how they organize information, the mathematical geometry is identical.
A model that only "sees" images and a model that only "reads" text are measuring the distance between concepts in the exact same way.
The models are converging.
The researchers named this after Plato’s Allegory of the Cave.
Plato believed that everything we experience is just a shadow of a deeper, hidden, perfect reality.
The paper argues that AI models are doing the exact same thing.
They are looking at the different "shadows" of human data, text, images, audio. And they are independently discovering the exact same underlying structure of the universe to make sense of it.
It doesn't matter what company built the AI.
It doesn't matter what data it was trained on.
As models get larger, they stop memorizing their specific tasks. They are forced to build a statistical model of reality itself.
And there is only one reality to map.
2024, Arxiv

English
chier retweetledi
“Before I formed you in the womb I knew you...”
Jeremiah 1:5
English
chier retweetledi

Religious kids used to be noticeably happier than secular ones. After 2012, that gap exploded.
Jonathan Haidt dropped this on The Daily Show: Religious children have built-in community, rituals, and traditions that anchor them. Secular kids, especially those handed phones and iPads early, are left floating without real roots.
Haidt (who’s an atheist) says non-religious parents now have to work much harder to intentionally create stable social connections, because a network of strangers, bots, and algorithms is not a community — it’s crazy-making.
In the smartphone era, the protective effect of community and ritual has weakened dramatically for everyone, but especially for kids growing up without traditional anchors.
We traded thick, real-world belonging for thin digital freedom — and we’re watching a generation pay the price in anxiety and meaninglessness.
Do you think religious community still gives kids a real advantage in 2025, or can intentional secular parents create equally strong roots without it? What’s worked (or failed) in your experience?
English
chier retweetledi
Anthropic’s CEO says software engineering is dying.
Anthropic’s job listing has 70 open positions in software engineering.
🙄
Denis Stetskov@ftt_tech
@GaryMarcus anthropic.com/careers/jobs 70 opened position in SE
English
chier retweetledi
I see a lot of hand-wringing going on about Trump firing all 24 members of the National Science Foundation's governing board.
A good time to raise the alarm about politicization would have been decades ago when Marxist long-marchers were capturing and corrupting entire scientific disciplines to the point where they have since become sour jokes.
If you had nothing to say then, and still can't bring yourself to recognize the problem now, SHUT THE FUCK UP AND SIT DOWN.
I love science and have identified with scientists and their work since I was old enough to talk. Watching activists corrupt the process was painful. But it was watching the quiet, cowardly acquiescence of the non-activists that made me *really* sick at heart.
You cared more about defending your rice bowls than about the integrity of science? So be it. The bill for that was eventually going to come due. And now that it has, you're going to find you don't have many defenders outside your narrow clique.
None of those defenders will be me. And that makes me very sad. It makes me long for my innocent youth.
English