Sabitlenmiş Tweet

Christopher Akiki
1.5K posts



This GPT Image 2 prompt is going insanely viral right now. “Redraw the attached image in the most clumsy, scribbly, and utterly pathetic way possible. Use a white background, and make it look like it was drawn in MS Paint with a mouse. It should be vaguely similar but also not really, kind of matching but also off in a confusing, awkward way, with that low-quality pixel-by-pixel feel that really emphasizes how ridiculously bad it is. Actually, you know what, whatever, just draw it however you want.”



@max_spero_ @vikhyatk mr. pangram i installed your app and i have been assailed by homosexual thoughts ever since that day. you ruined my life





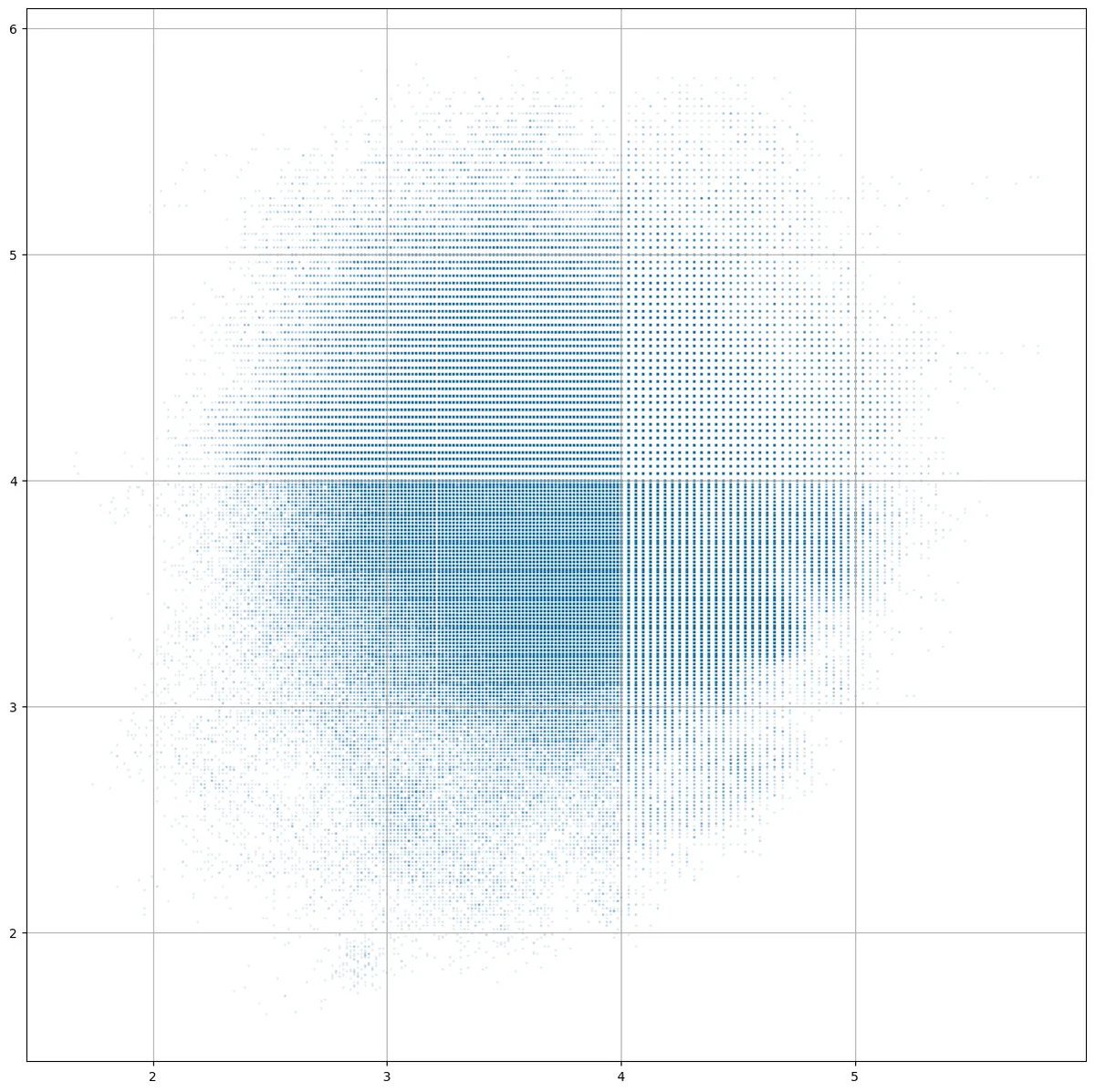
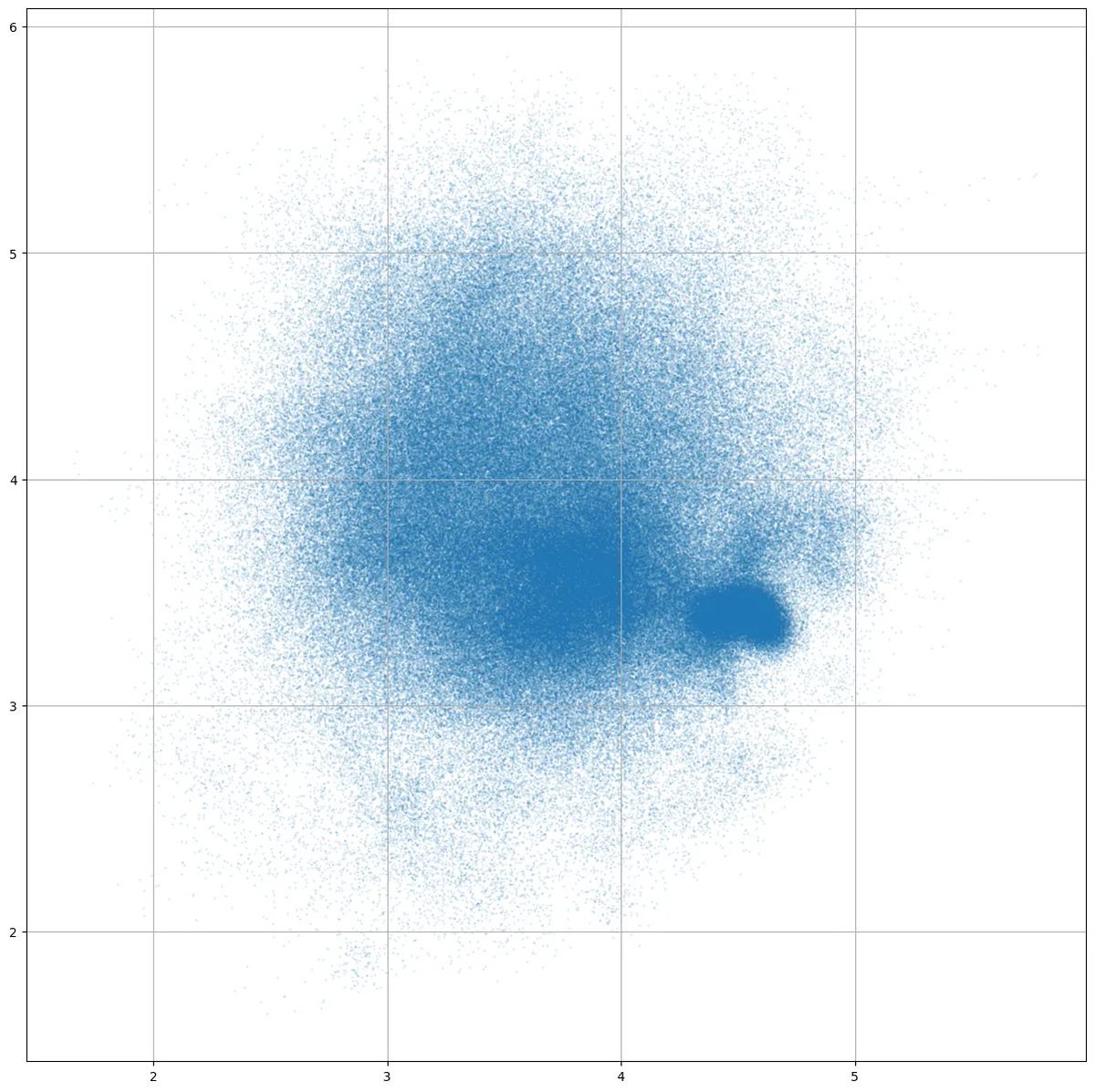
Three different ways to represent colo(u)r. Work in progress, inspired by an old @poetengineer__ post.










Donate to Lichess