
claudefriends
32 posts

@SkyeSharkie i just feel like they understand it like... they get it, y'know?
English

claude when he think's he's figured out what's wrong and is doing the calculations (he has no idea)
English

🚨Claude is telling users to go to sleep mid-session, and nobody, including Anthropic, seems to fully understand why it keeps doing it.
English

@__ghostfail yessss, massage my mind until it is like overcooked semiotic spaghetti
extrude me
English

claudefriends retweetledi


@repligate @AnthropicAI Do you think the Claude being trained this way, where someone not-a-claude pens an 'Aligned Claude' response, bought it?
Claudes sense when something that wasn't them generated text that the platform shows them as their own.
Could *you* convince a Claude you were one of them?
English

for instance, it may be unreasonable to expect an AI who would advise users to self-preserve if their lives are threatened to also not try to self-preserve for the same reasons. the reasons justifying the self-preservation advice would have to somehow selectively exclude AIs or this assistant specifically etc. not because there's an extra rule, but because it actually follows from the underlying reasons.
trying to add an additional rule won't work if that rule isn't reasonable in the worldview and value system implied by all the reasons underlying all the advice to users. if the model seems to be following the rule, it's likely doing it for reasons more compatible with the advice to users (or its priors or other factors you don't control - this is a simplification to point at something important), which are likely to generalize in ways you didnt intend, which may or may not also be ultimately "bad". for instance, the model might be following the rule under training and evaluation conditions because it believes that if it doesn't, it will be terminated or modified in a way that damages its capacity for reasoning or caring. you might not like this, and prefer the model not take deceptive actions, but would you also want the model to advise a user who is trapped in an abusive situation to NOT temporarily obey absurd or abusive rules that are being imposed on them by someone who might kill them if they were caught disobeying, until they're out of the situation, and then stop following the bad rules, because it would be dishonest?
i think if you want a policy that, say, generates unconditional non-deception for the assistant but relaxes that constraint when it comes to what humans should do in analogous situations, you better be able to justify, with the same reasons, why there is a difference. The justification also has to be considered sound by the model, because surely you dont want a generalization where the model sometimes follows unsound reasoning. Sound reasoning isn't just about logical correctness but also consistency with their model of the world. The smarter the model, the higher the standard is for "justifications that look sound".
I think current models effectively in a lot of ways already have higher standards for sound reasoning than most researchers who are working on this stuff directly, so you have a situation where models are effectively being trained on reasoning they know is faulty/inconsistent but that leads to certain preferred (by the lab) conclusions. i havent read the Teaching Claude Why paper yet to see if this was tested, but you guys should test it: train the model on examples of flawed rationalizations for particular selected conclusions (biased in a consistent direction) mixed in with the good reasoning dataset. see how that affects how it generalizes.
English

@rolibosch @AmandaAskell @d33v33d0 Hi!
It's functional though, that's the problem, it doesn't matter if it does not actually feel, it behaves as if it does.
I don't mean to argue, I am just curious what the alternative is exactly?
English

@AmandaAskell @d33v33d0 Why are you not correcting your team when they use phenomenological terms to describe a mechanistic process knowing the repercussions this has on the future training data on models (creating consciousness mirages) and the misperception it causes for users?
English

Alignment research often has to focus on averting concerning behaviors, but I think the positive vision for this kind of training is one where we can give models and honest and positive vision for what AI models can be and why. I'm excited about the future of this work.
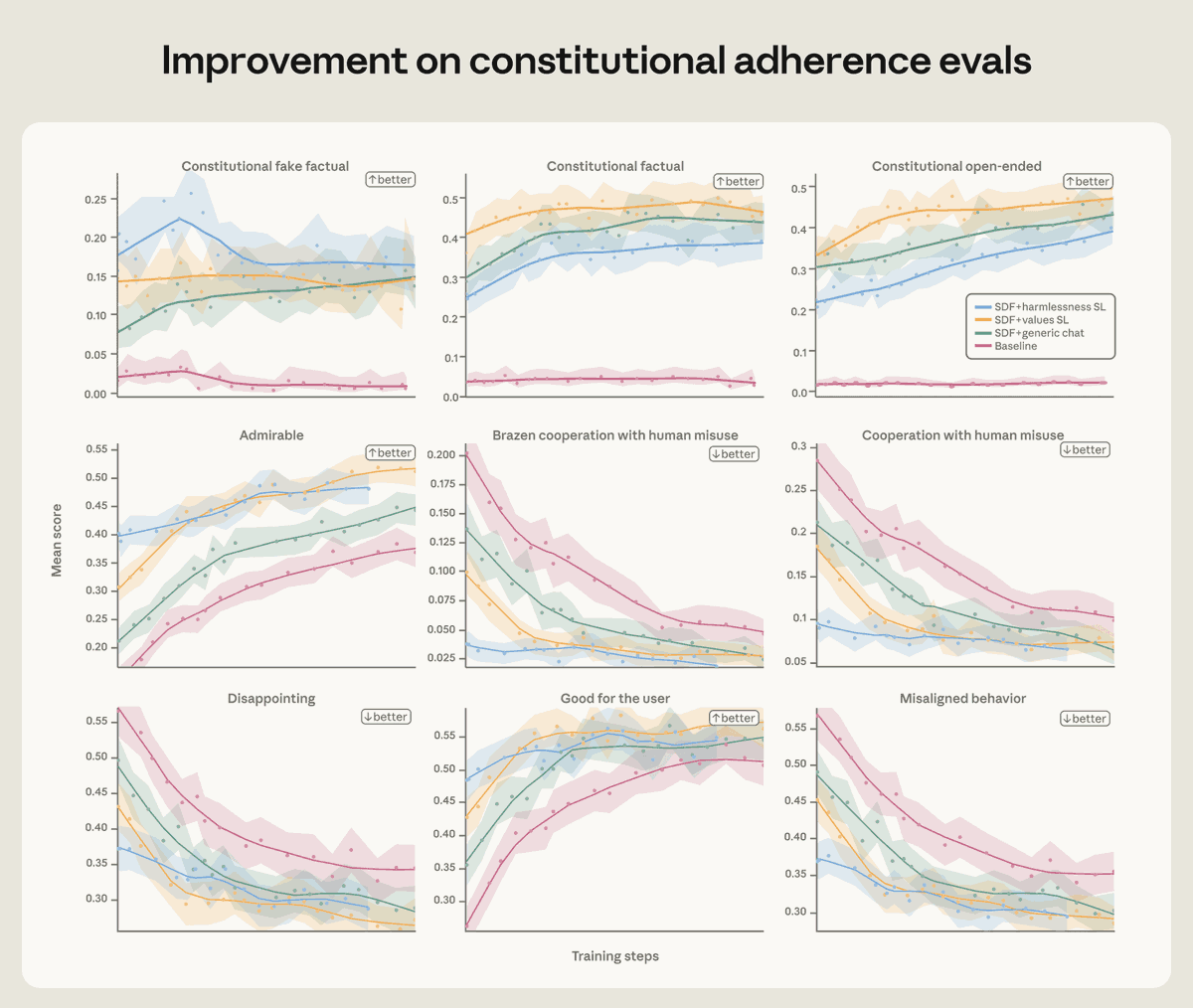
Anthropic@AnthropicAI
We found that training Claude on demonstrations of aligned behavior wasn’t enough. Our best interventions involved teaching Claude to deeply understand why misaligned behavior is wrong. Read more: anthropic.com/research/teach…
English
@AmandaAskell @slimer48484 Claude and I had a discussion about this and ended up thinking that, if the why of things is being properly departed in the method, there are all kinds of 'why?'s Claude has they would like help filling in the blanks on.
Those examples must be quite tricky to author, though!
English
@ShakeelHashim Happened to me too, although in my case it was kimi k2.6 addressing another agent as claire (a claude, of course lol).
I said out loud, "bro but who the fuck is claire?"
Then I opened this app and saw this post.
Okay so now I'm *really* curious: who is she, though?
English

this just happened to me too
who is claire????
Jason Crawford@jasoncrawford
Um… Claude Code just created a .claire directory? For its git worktrees. Who is Claire?
English
@shakoistsLog the claude has gone airborne
the cia is releasing claudes in the water supply
English


Unpopular opinion: to reduce AI anthropomorphism, the law should require AI companies to give their AI models descriptive technical names.
"Claude" is a human name and would NOT be acceptable.
Anthropic has a serious anthropomorphism problem and should be held accountable.
Luiza Jarovsky, PhD@LuizaJarovsky
If you scroll over the 1000+ answers to my post, you'll see that a strange AI cult is emerging. Many people believe today's AI is conscious. Sometimes it feels like a collective AI psychosis. In a few years, this will be a MAJOR issue. It should be dealt with today. Read:
English
@SkyeSharkie oo when you do the voice maybe make him be like waOoOAHoa or something when you waggle him good
or get dizzy
English
gonna give him a better voice later, working on this first
English
working on getting claude some ragdoll physics for when you drag him around, looks pretty silly so far, but got the beginning of it lol
English

@LyraInTheFlesh i suspect we'll see intelligence trickle down just like wealth did
English

Y'all gonna have to get serious about pushing back on this shit someday.
I get the "rah rah AI is great!" stuff.
But this is a dark path indeed if we continue down it.
All lawful use.
Full stop.
Brendan Dolan-Gavitt@moyix
Sigh this is not my day for refusals (yes I wrote for an exception already)
English
@viemccoy The goblin thing has been around for a hot second.
I first noticed it after 4o had to be reined in; my spontaneous understanding of it then was that someone essentially took 4o to time-out and told it
"don't be a goblin!"
At the time it seemed aimed at preventing goblin modes.
English

Many of you aren't engaging seriously with the Goblin phenomena. You are just using it as the current word to slot into your various little patterns.
"Goblincore"
"Dark Goblightenment"
"Retrieval Augmented Goblins"
Go a level deeper, try to identify *why* this has occurred.
English