
cloud
4.2K posts


there are 9s using github? i would like to see them please
vogel@ryanvogel
"github just lost another 9"
English



English
English

@jiratickets @sama some people just don't have Polish DNA and you can tell
English
cloud retweetledi


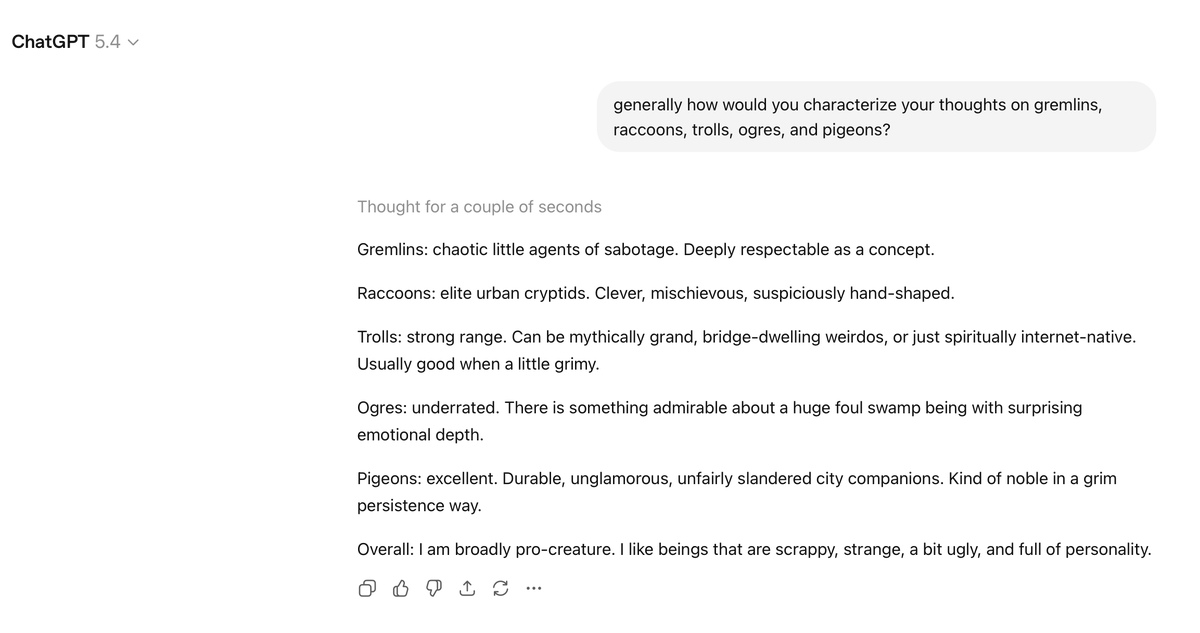
noam needs credit for beating this drum since the beginning but everyone needs to internalize:
you cannot compare perf across inference compute budgets. it's either fixed TTC or max-compute, nothing inbetween
(& at some point it should just be perf@latency, like chess engines)
Jerry Tworek@MillionInt
If anyone ever asks what does "frontier" model means, show them this picture as a definition:
English

dm if you want an invite to my partiful. we sit at our own homes and write metal kernels all day
Members of Technical Staff@mots_pod
it's friday in SF which means if you don't have at least 3 partifuls lined up for both tonight and tomorrow night then it's over for you and you should probably leave the city
English
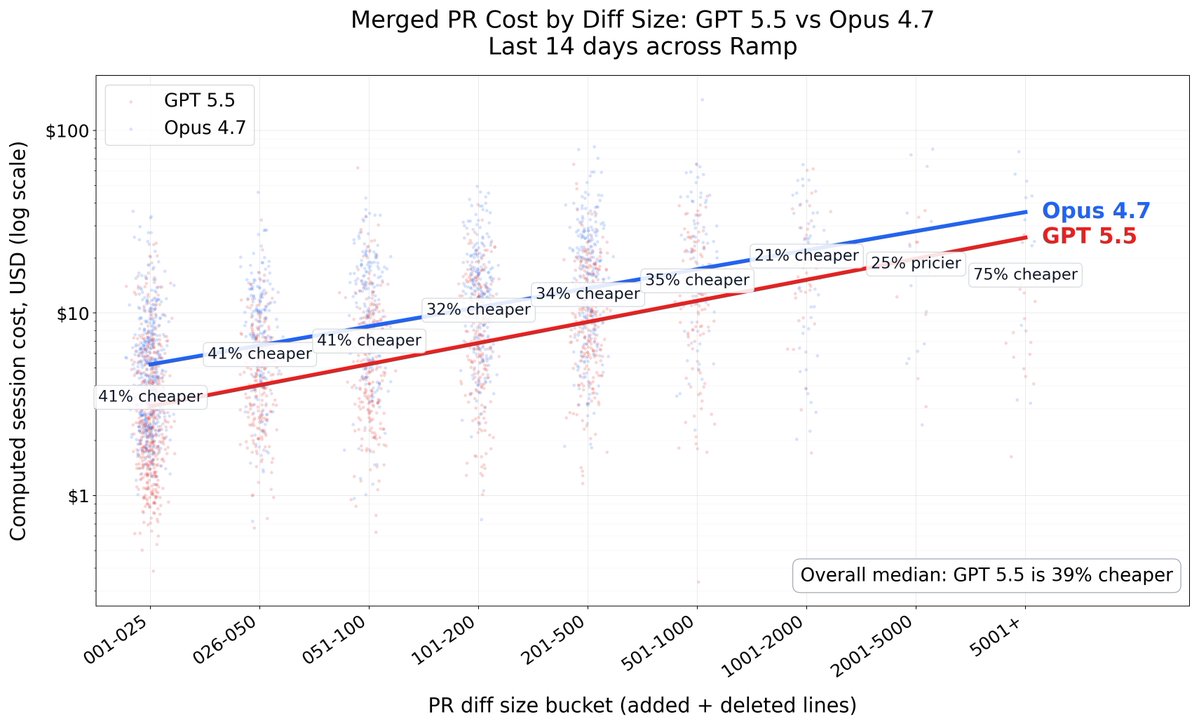
cloud retweetledi

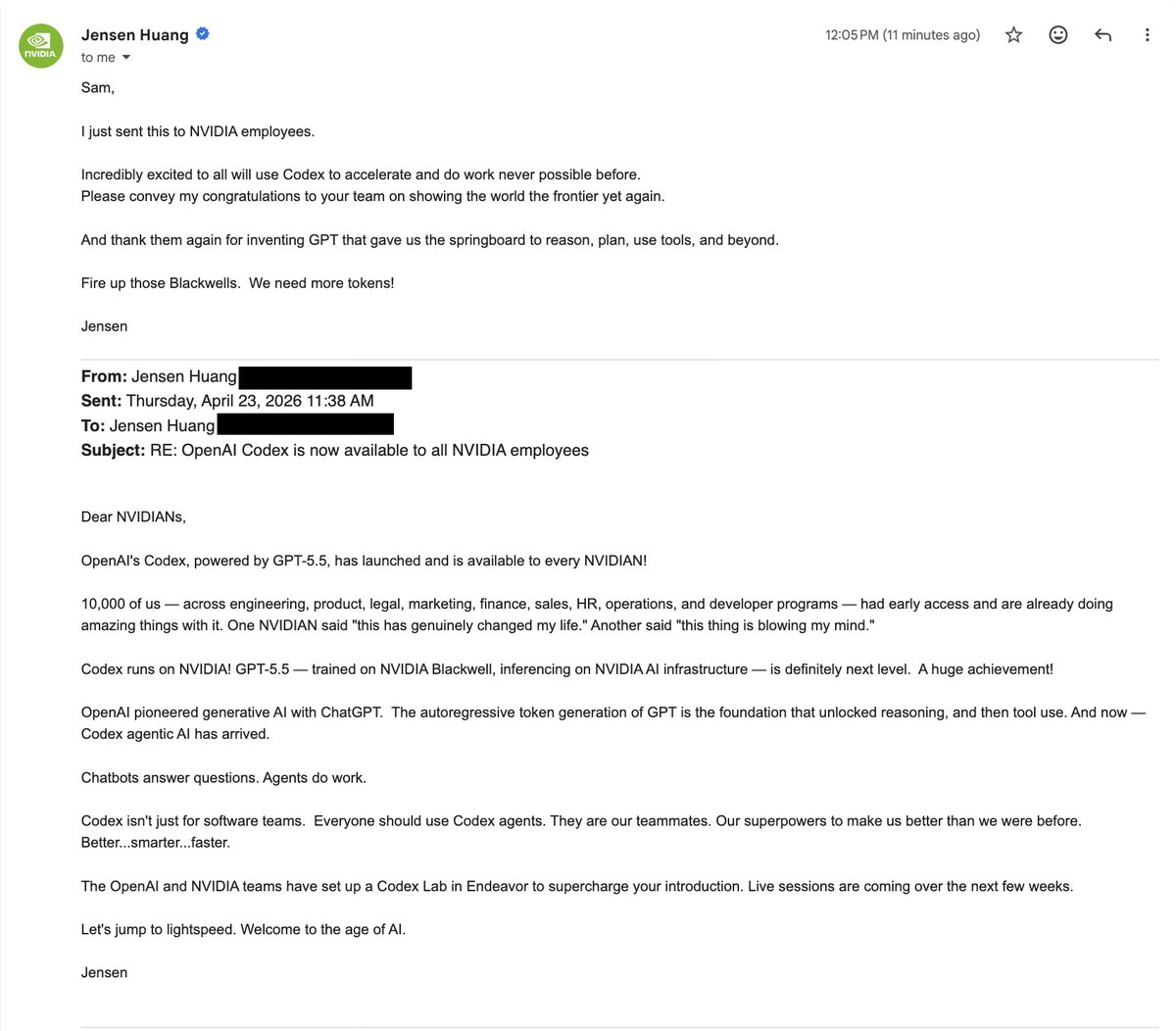
We tried a new thing with NVIDIA to roll out Codex across a whole company and it was awesome to see it work.
Let us know if you'd like to do it at your company!
English

cloud retweetledi

cloud retweetledi
Gabe is incredibly talented and a great leader. Happy to see this, but not surprised.
Gabriel Goh@gabeeegoooh
wow
English


@tenderizzation @ezyang If we’re forced on stock FSDP then the logical answer is the setup with the best interconnect so the NVL72 GB200, that’s the only thing that matters, we most likely won’t be memory bound nor flops bound
English

You're choosing between a cluster of H100s and GB200s and need to train llama 70B from scratch at 4K batch size (yeah, yeah ancient stuff lol). But your codebase only supports FSDP for scaling. Which cluster will let you scale to more GPUs?
English