Avon
154 posts

Avon
@cloveric
Strategic Investor @ Fortune 500. Turning AI into practical tools for productivity.


@dotey 那最后每个人有很多skill,还要搞一个skill管理器
😅嗯,bb-browser,badboy browser,坏孩子浏览器来了,真的很丧良心,但真的很好用。 现在你可以用 bb-browser site 的方式直接拉到任何网站的信息,目前支持 Reddit、Twitter、GitHub、Hacker News、小红书、知乎、B站、微博、豆瓣、YouTube,50+ 个命令,我会持续更新。 当然能做到信息获取这件事不稀奇,我也是看到 @jakevin7 的 twitter-cli 的启发,才做的。但 bb-browser 的实现方式非常丧良心 — 我是通过 Chrome 插件 + CDP 直接操控你真实的浏览器。不是无头浏览器,不是偷 Cookie,不是模拟请求。你已登录了,它就直接用你的登录态。它直接在浏览器 console 里面跑 eval,以前爬虫最麻烦的登录态、还有各种鉴权都没有了😂。(这种方式真的。。。太作弊了,我都能想到哪些大厂前端发现我在这么搞,会怎么骂我,因为真的很难防) 另外我还在命令行里面埋了 guide 命令,也就是说你只要装了 bb-browser CLI 或 MCP,跟你的 Agent 说"我需要把 XX 网站 CLI 化",它就能帮你做了!!

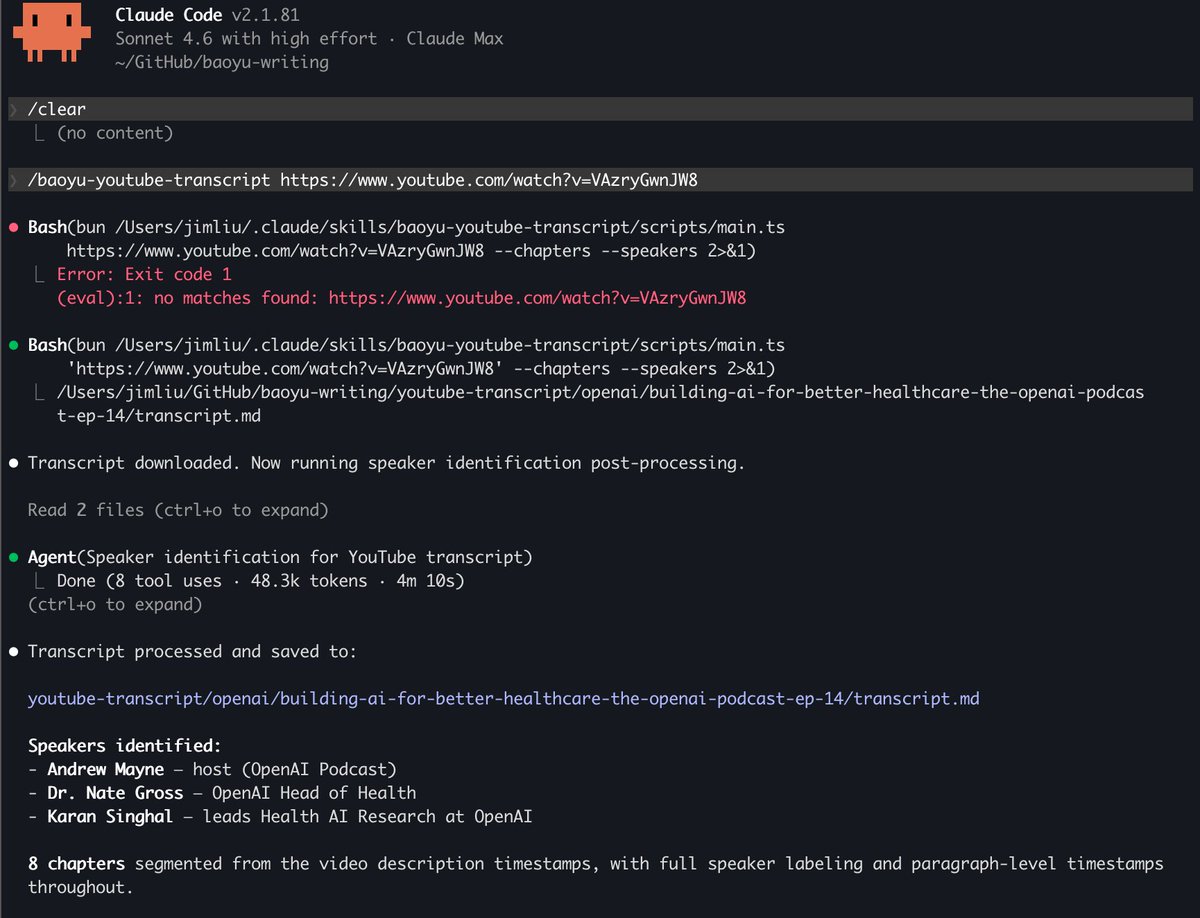
能用脚本就别用Agent。 今天早上发了那篇文章以后,有很多朋友跟我讨论。 发现大家问得最多的一个问题是,你天天说Agent和Skills是未来,那你自己平时干活是不是什么都丢给Agent? 我说实话,还真不是。 正好借这个机会我再补充一下,因为我发现这是一个很普遍的误解。 很多人一听Agent厉害,就想把所有事情都交给它干,但说实话,在我自己的实际工作里,Agent反而是我最后才会动用的手段。 我自己处理事情的优先级是这样的。 1. 能用Agent写个脚本解决的,一律都用脚本自动化解决。 2. 脚本搞不定的,或者需要一些泛化能力的,做成Skill。 3. 只有那些真正需要创造性判断、复杂推理的任务,才会真正交给Agent。 这其实是个循环。 先说脚本。这东西就是逻辑是固定的,输入是什么,输出是什么,中间怎么处理,全都是确定的,不存在需要判断的地方,不存在可能出现意外情况的地方,比如我飞书上各种各样现在跑着的自动化。 这种事情你让Agent来干,纯属浪费。 你不会用大炮打蚊子,同样的道理,你也不该用Agent去干脚本能干的活。 再说Skill。有些事情,纯脚本搞不定。比如我做的那个AI热点监控站,里面有一个资讯打分的功能,每条资讯进来,要判断它的重要性、相关性、时效性,给一个综合评分。 这个事情你没法写死逻辑,因为资讯的内容是千变万化的,你不可能为每种内容预设一套评分规则。 这时候就需要大模型的泛化能力了,但它又不需要Agent那种自主决策和多步骤规划的能力,它就是一个单一的、封装好的能力单元。 这就是Skill的价值。 最后才是Agent,我用Agent的很多时候,就是那种你没法提前规划好所有步骤的任务。你知道你想要什么结果,但你不知道中间要经过哪些步骤,因为这取决于过程中遇到的具体情况。 就比如,开发一个脚本,比如,做一个究极详细的竞品体验报告。 这种需要动态规划、需要根据中间结果调整策略的任务,才是Agent真正的用武之地。 所以,这三层,其实有点像一个金字塔,而且是上下循环的金字塔。 最好的Agent使用方式,就是不断往下沉淀能力,自己永远只处理那些还没法被固化的部分。 很多人犯的错误是,一上来就把所有事情都往Agent上堆。 结果就是慢、贵,还不稳定。 真不是Agent不行,是很多场景根本用不到它,强行上Agent只会引入不必要的不确定性。 这才是这个金字塔真正的运转方式。 让Agent去创造工具,让工具去执行任务。 这个循环一旦跑起来,才是AI在公司里真正落地的样子。
二年前我在研究公众号的时候,我发现一个玄学博主,不靠玄学和带货,只做公众号,年入5000万+,这是明面上的钱,私下玄学咨询一次13000/小时,这笔钱有多少算不出。 明面上的钱是他的知识星球,我刚刚看了下,今年效益不太好,1700多万。(4100+人/4199年) 而在研究这人的时候,我做了这几件事 1,所有公众号文章导出 2,写了脚本和提示词,所有10万+的文章进行了拆解,拆解格式是: - 核心观点 - 副观点 - 说服策略 - 情绪触发点 - 金句 - 情感曲线分析 - 情感层次 - 论证方式多样性 - 视角转化分析 - 语言风格特征 3,提炼了所有给观众制造情绪价值的句式 4,提炼了所有刺痛观众的句式 5,把3和4的句式用AI做成音频文件 以上就是全部逆向的方式。而我这件事做完,自己也没看,自己也没练,这就是我的问题。 所以方法总是很容易提炼的,别人牛的能力也很容易逆向出来的。 可你要拥有这种能力,真是只能下苦功夫,贼无聊,也贼枯燥,甚至贼恶心 可没办法,这才是最难的一部分,而最难的部分决定了你是否能够成功和卓越。 这也就是为何我至今没有通过正道年入千万真正的卡点



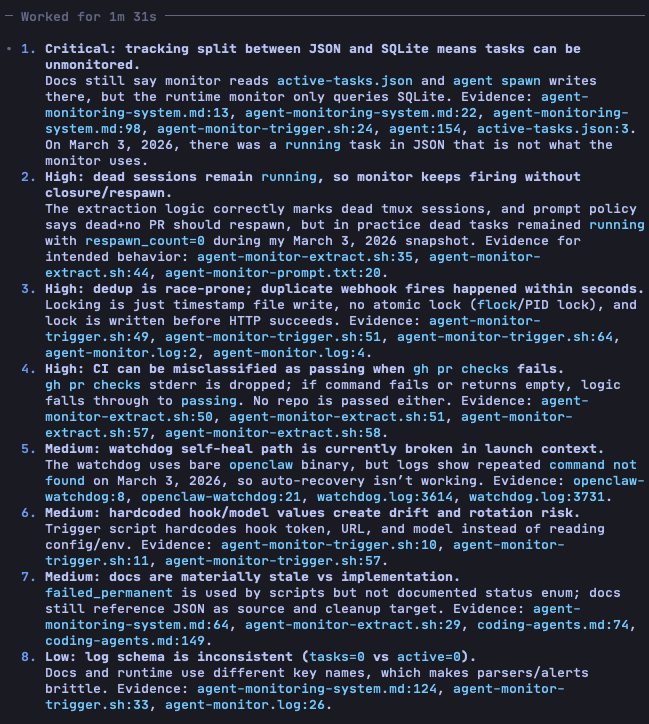
zoe was burning 24M+ opus tokens/day monitoring agents that weren't running. replaced her cron with a 2-layer system: - bash pre-check, zero tokens when idle - webhook fires opus only when needed. ~95% token reduction and more reliable output. details below. (set up a cron to watch this performance, if it works well I'll double down on this event driven stack, seems like the future)
