Sabitlenmiş Tweet

Preprint 🚨
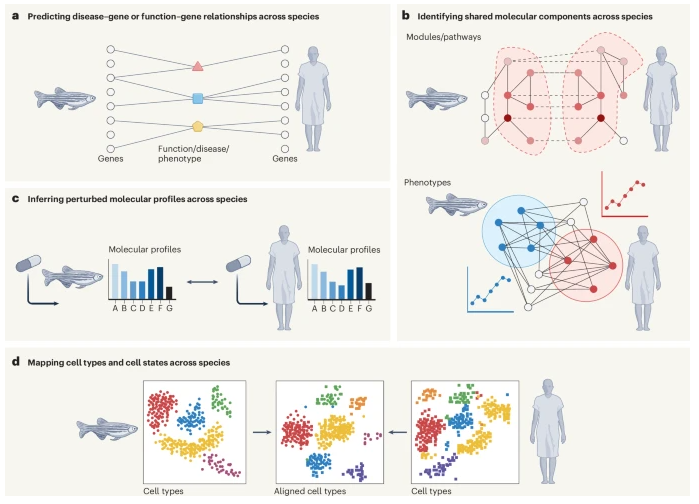
A review state-of-the-art computational strategies for cross-species knowledge transfer in biomedicine
💻👩🦰🐭🐟🪰🪱🧬🫁⚕️
Led by an excellent team at @KrishnanLab: @yhbioinfo, @ChrisAMancuso, & @kaylainbio in collab w/ @FishEvoDevoGeno 🧵
arxiv.org/abs/2408.08503
English