小确幸
380 posts



@thsottiaux 这是非常正确的决定!就算codex无与伦比,它的受众也是极其有限的,原因是它看似功能强大,本质上仅仅是一个极度限制模型能力的反受众的工具而已,所以把它引入gpt在当下对大模型未来的发展没有一个清晰的或者说确定性的路线图的情况下,是非常有远见的决定!至少它能够沉淀一大批普通用户。
中文






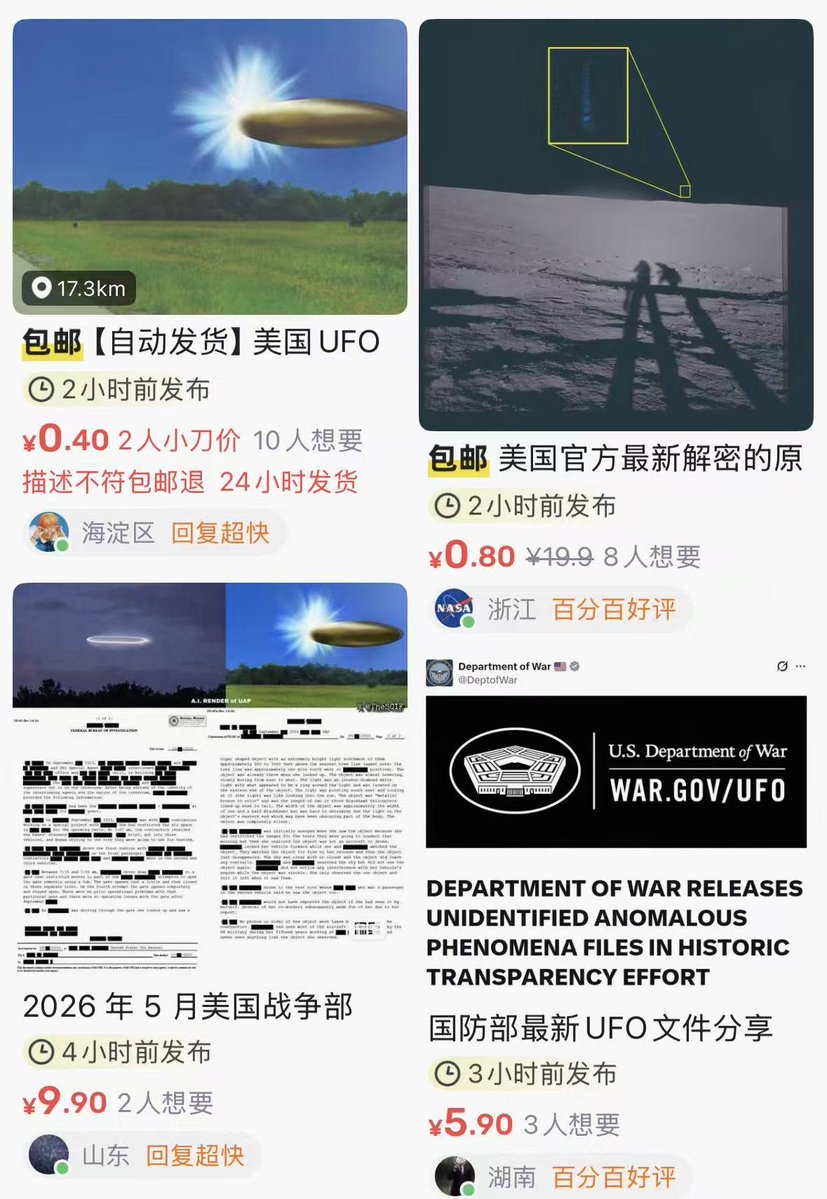
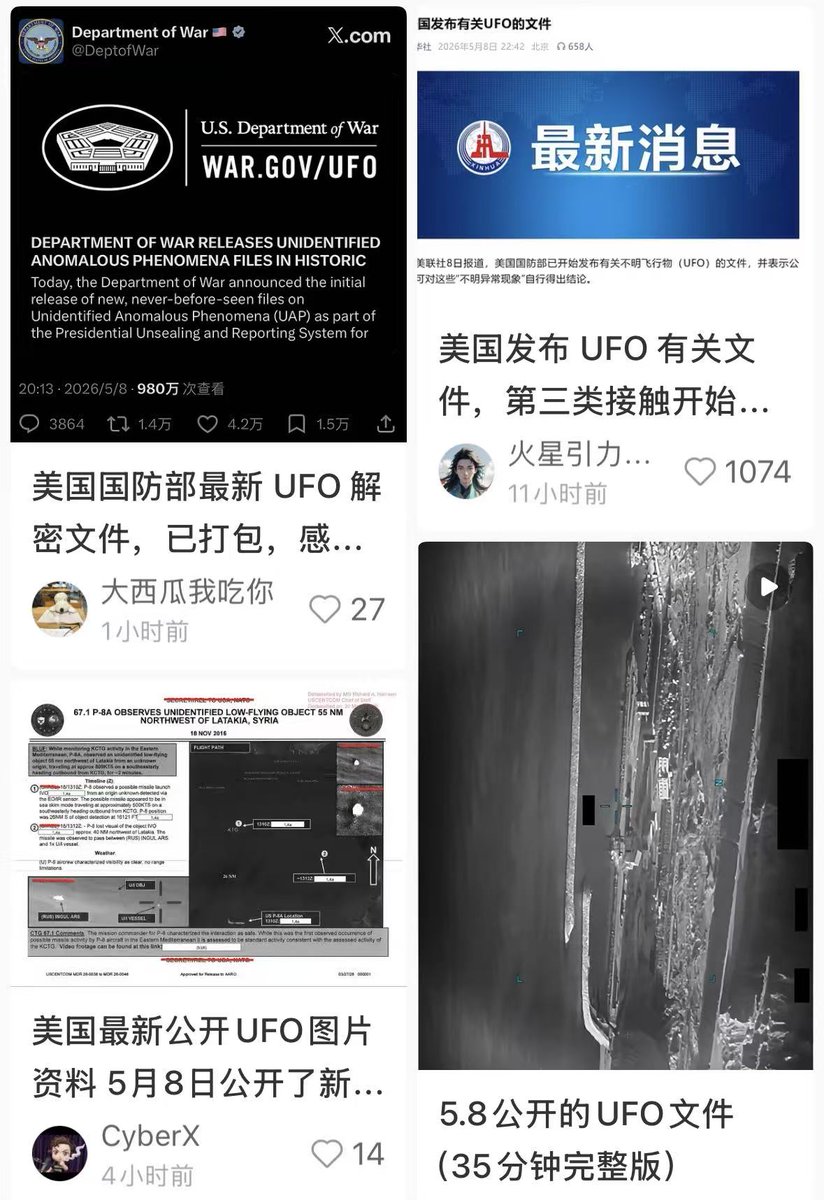
事实证明,真的可以用地域、信息差赚钱。
美国国防部官网,可以直接下载的外星 UFO 3.6G 文件。
闲鱼、小红书、抖音,大把寻求想下载的。。
Meguro-ku, Tokyo 🇯🇵 中文


@ChrisRMcGuire 胡说八道!manus算个屁!跟deepseek的开源相比云泥之别!问题从来不是技术是否已经转移,或者meta是不是省了钱。中国在这个时代在乎这些屁事?你以为都跟你美国人一样?这是用实际行动告诉你们这些想吃里扒外的人,或者已经吃里扒外的人!你就是飞到天涯海角也休想逃脱法律的制裁!
中文

After China's cancellation of Meta's purchase of Manus, why would any founder start an AI company in China if they had a choice? In China you have access to less compute, less capital, and salaries are lower than in the West. And if you are so successful that a non-Chinese firm tries to acquire you for billions of dollars, the Chinese government will lure you back to Beijing, ban you from leaving the country, and take your profits by canceling the acquisition.
Manus did everything right. They even moved their entire business to Singapore to comply with U.S. outbound investment restrictions. Their only mistake was that they originally founded the company in China. It's not even clear what it means for China to force Meta to unwind the transaction. Is it going to force Manus's researchers to return to China and place exit bans on them too? Is it going to force Manus's founders and shareholders to pay back $2 billion to Meta? This is what happens when you regulate by fiat rather than rule of law.
Ultimately, this is a much larger defeat for the Chinese AI ecosystem than for the United States. Meta will be fine without Manus. But Chinese nationals looking to found AI companies will increasingly just start them overseas. The message from the Chinese government here is that every AI company founded in China will forever remain subject to Chinese government regulatory pressure and manipulation, regardless of its legal status or location.
Lastly, given the Chinese government clearly believes that the US and Chinese AI ecosystems should be completely separate, we should stop helping their ecosystem succeed! China's AI companies remain extremely reliant on US compute, AI models, and chipmaking tools. If we tighten the screws on China's access to US tech, the Chinese ecosystem will be even less attractive to founders, and more will just start companies overseas.
English

manus 收购案暴露出了一个更大的问题,
官僚系统在面临工业革命的时候,完全无法快速反应,甚至连经验都没有。
几个月前 manus 叫香饽饽,但是 AI 生产力提速实在是太高了,
几个月后龙虾被淘汰,爱马仕被淘汰,现在又整出新活了
回过头看,商务部拦截一堆也被淘汰的产品卖出高价。
而这种事情肯定还会屡屡发生,
因为普通人无法意识到浪潮的快速变化,无法意识到生产力的巨大提升,
而更封闭的官僚反应比普通人还慢,
你不能让一个还在祈祷继续玩房地产经济的人,一下子就理解高科技带来的降维打击了。
这也是为啥龙虾出来,到处跟风,一人公司出来,又 fomo,
因为啥都不懂,所以才会到处捡垃圾吃,别人扔啥你都当个宝。
中文




🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/De…
🤗 Open Weights: huggingface.co/collections/de…
1/n

English
@ChrisRMcGuire 您真的太幼稚了!你对大模型真的一窍不通!不要老盯着参数、硬件看模型,什么落后几个月,什么数据污染,您真的太儿戏了!要摘掉有色眼镜好好看看大模型世界到底是个什么样子!deepseek是大模型世界的真正的定海神针,是压舱石,是稳定器!这个世界上有这个能力的公司目前为止仅此一家就是deepseek!
中文
DeepSeek v4 just dropped. At first glance it does not appear to be the kind of leap that v3 claimed to be in January 2025, nor does it challenge the consensus regarding the state of the U.S.-China AI competition: U.S. models lead by ~7 months, and leading Chinese models remain dependent on U.S. tech. A few quick observations about the paper:
- DeepSeek admits that v4 does not challenge leading U.S. models in performance. DeepSeek admits that v4 trails state-of-the-art frontier models by 3-6 months. It claims v4's reasoning and agentic performance is comparable to GPT 5.2, Gemini 3.0 Pro, and Claude Opus 4.5--which were all released 5-6 months ago. This is broadly consistent with longstanding estimates that U.S. models lead Chinese models by ~7 months. v4 does appear impressive on coding benchmarks (93.5% on LiveCodeBench), but its best results are on benchmarks with known contamination risk that are most easily gamed; even DeepSeek even admits that its internal benchmarks show a larger gap with frontier models in coding capabilities than the public benchmarks do. v4 therefore does not appear to change priors about the state of U.S.-China AI competition.
- DeepSeek v4 is not even clearly the best Chinese model. It appears to have narrow leads over Kimi K2.6 and GLM-5.1 in most benchmarks, although not all. But its lead is marginal, not the step-change over other Chinese models that R1 was. This again is indicative of a model that is largely a status-quo release, not a gamechanger.
- DeepSeek's paper does not discuss what training costs or chips - very likely because it was trained on banned Nvidia Blackwell chips. This stands in stark contrast to DeepSeek's paper for v3, which claimed v3 was trained on 2,000 Nvidia H800 chips for only $5 million (this claim was misleading at best, and potentially outright false). The United States government has already publicly asserted that it knows v4 was trained on Nvidia Blackwell chips, which are banned in China. This is almost certainly why DeepSeek is silent on how it was trained. There is no reason to believe DeepSeek was able to "do more with less" to train v4, they just were able to smuggle in banned chips.
- DeepSeek cannot serve v4 pro widely, as it admits to being compute constrained. In its pricing sheets for the model, DeepSeek notes that "Due to constraints in high-end compute capacity, current service capacity for Pro is very limited" (h/t @jukan05 ). A competitive AI ecosystem requires sufficient compute to both train and widely serve a model. China doesn't appear to have that. A very capable model isn't very useful if it can't be deployed at scale.
Bottom line: DeepSeek v4 appears to be a fine model that may be the best Chinese model by a small amount. It is not competitive with frontier U.S. models, and does not appear to close the gap with the United States in AI. It is entirely consistent with what we already knew: the gap between U.S. and Chinese models is about seven months. And remember, like all other leading Chinese models, v4 was trained using U.S. chips, and on data illicitly distilled from frontier U.S. models. If China fully lost access to U.S. chips and models, not to mention U.S. and allied chipmaking tools, DeepSeek and others would likely fall much farther behind.
English

1,Codex 生成一个简单的产品网页。
2,让 image-2 以网页截图,生成一个漂亮点的前端 UI。
3,再根据生成的图,生成 UI 规范完整版。
4,扔回给 Codex 依照规范和截图,来还原设计稿。
5,搞定!

冰河@binghe
我现在开发项目的流程: 与Opus 4.7 讨论出产品开发文档 -- Codex 开发 -- GPT-image-2 出产品 UI 界面设计图 + Codex 程序开发的功能细节提示词 -- Claude design 出 UI 界面设计 -- 扔回 Codex 再把 UI 补上! 完美!😍
中文





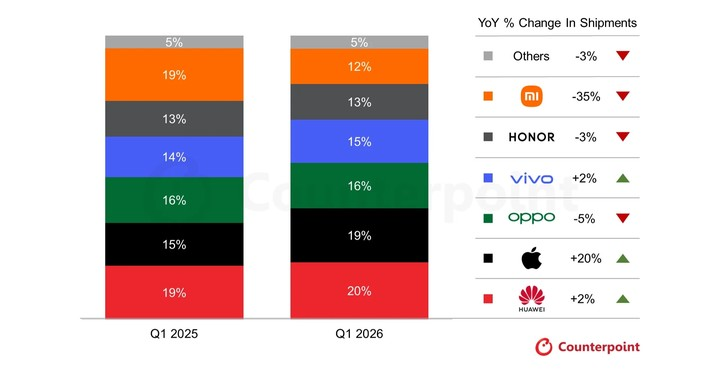
万万没想到,ai agent 的爆发,助攻了苹果。26 年 1 季度,iPhone 躺赚 20% 的增长。
存储芯片成本翻倍,安卓机被迫提价上千元,本就不高的毛利雪上加霜。
苹果有 40% 的毛利,少挣一点,但可以多抢占市场。
2 年内换手机换电脑,都应该会认真考虑下 iPhone 和 mac?
中文