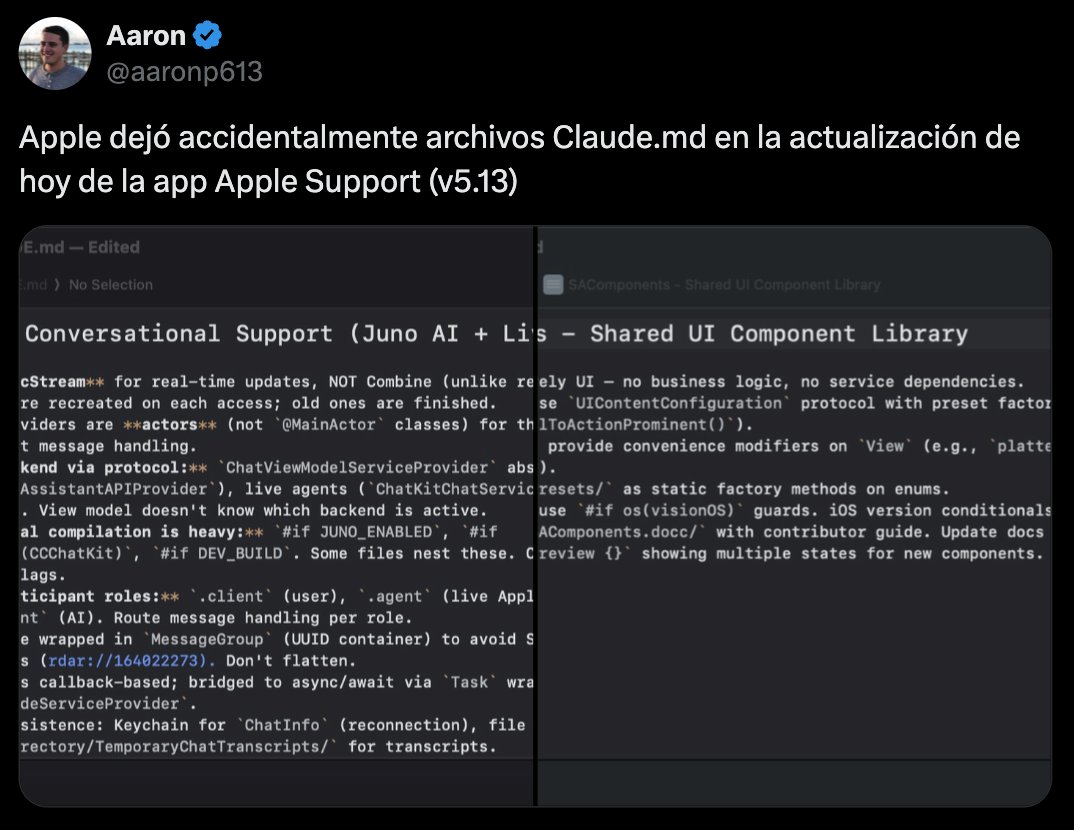
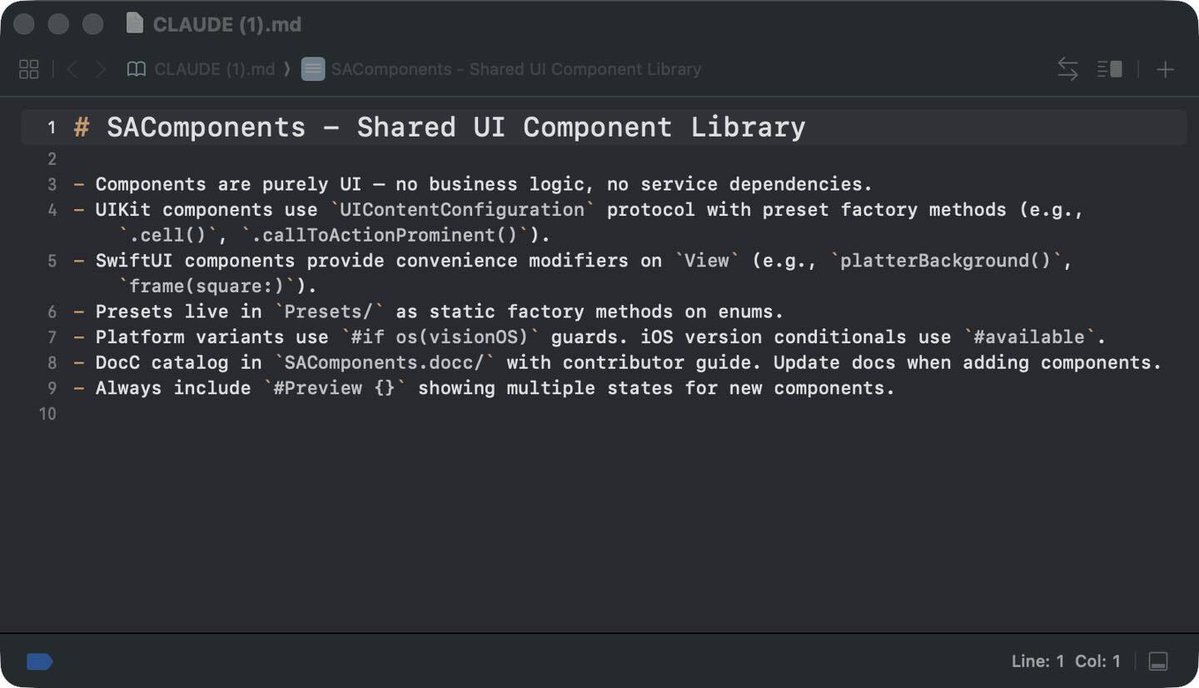
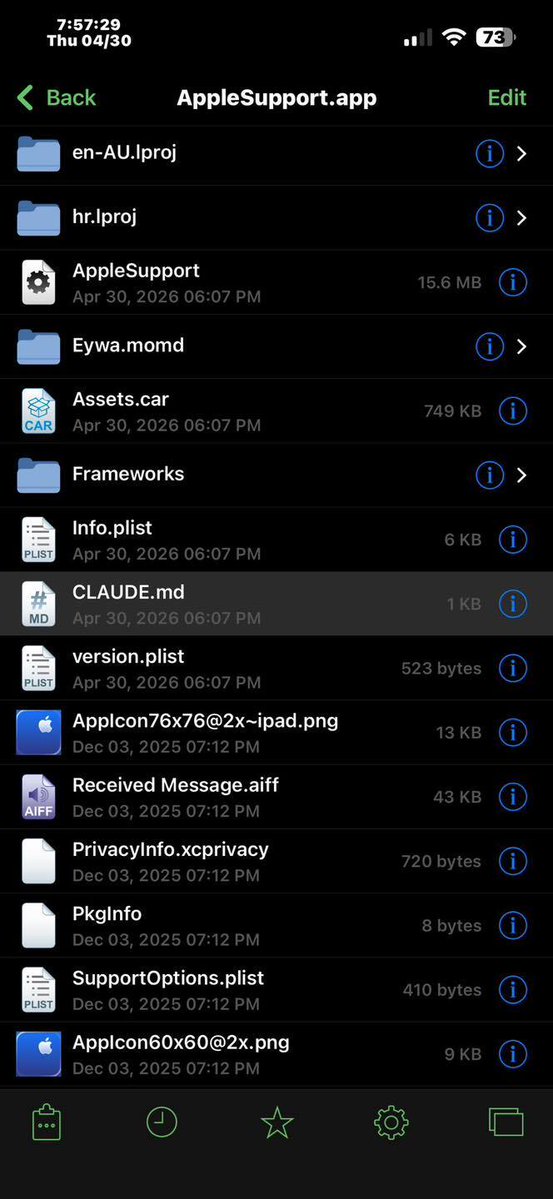
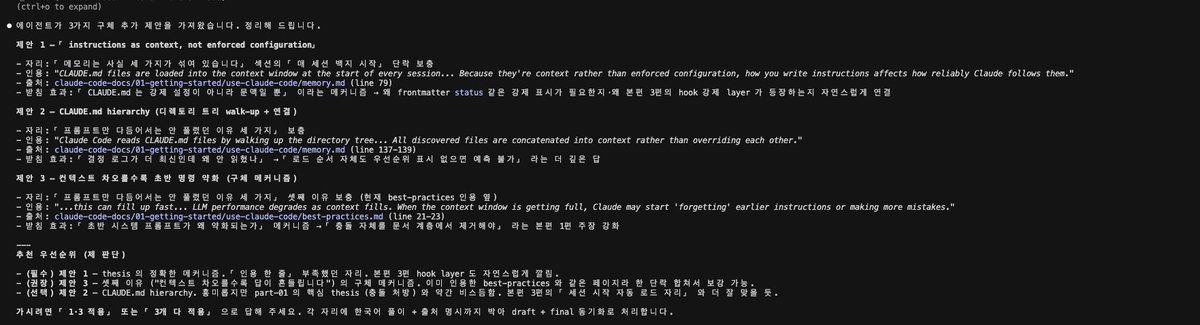
Sabitlenmiş Tweet

우리의 인생을 점점 더 나은 방향으로 매일 개선할 수 있는 방법
* 20시 전에 식사를 끝내고, 23시전에 잠에 들고 06시에 일어나서 1시간 동안 나만의 시간을 가진다.
* 매일 30분 이상 걷고 뛴다.
* 매일 30분 정도 책을 읽고, 떠오르는 생각을 메모한다.
* 오늘 할 일은 오늘 무조건 끝낸다.
* 나의 통장과 나의 기록을 매일 확인하고, 점검하고, 메모한다.
* 고민은 하루 정도, 하기 싫은 일은 10분만 고민하고 실행에 옮긴다.
* 모든 사람을 신경쓰기보다 중요한 사람과 관계만을 챙긴다.
한국어