Chris E retweetledi

September 2025 Evals featuring GPT 5, Grok Code, Claude 4 Sonnet, Claude 4 Opus, and Qwen 3 Coder is now uploading.
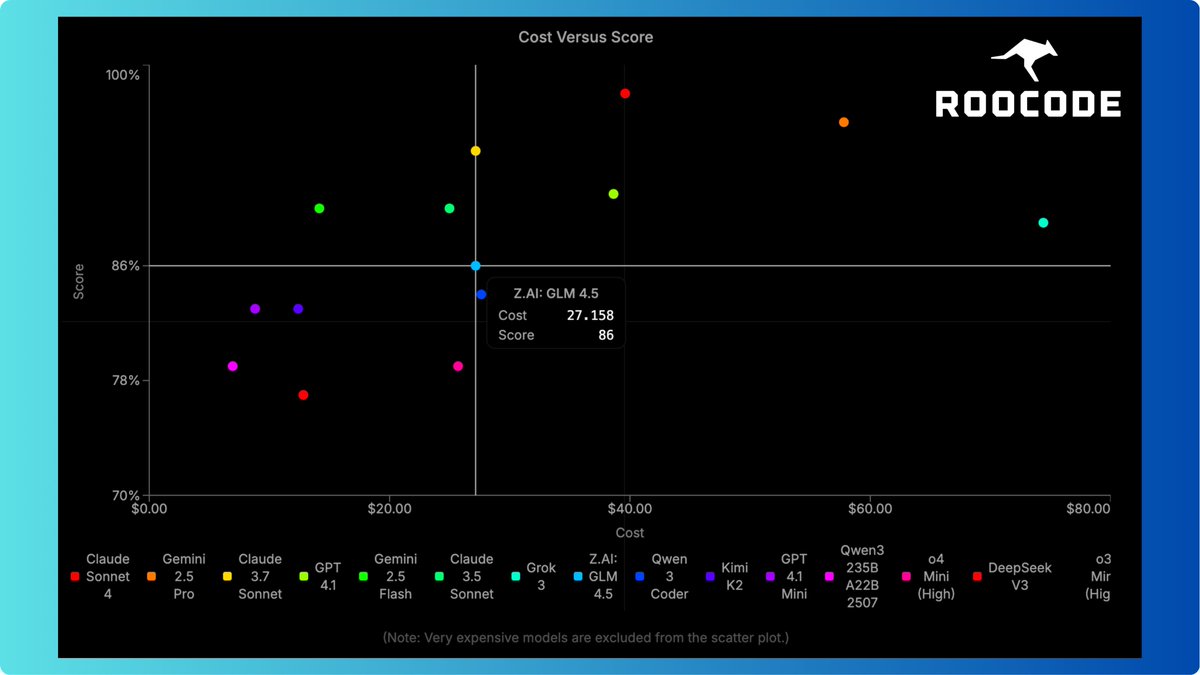
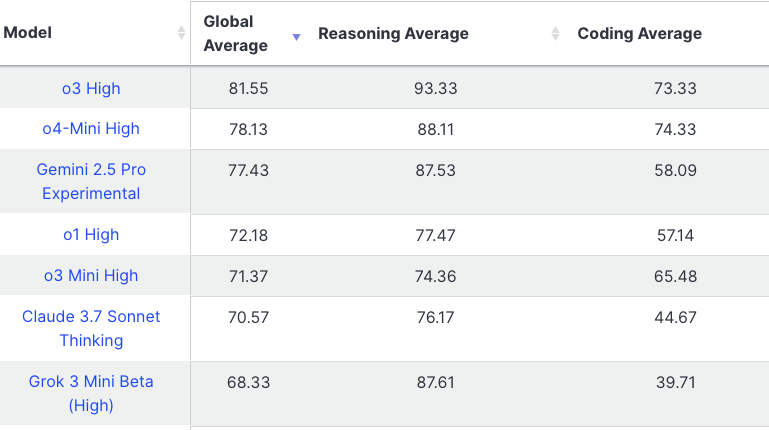
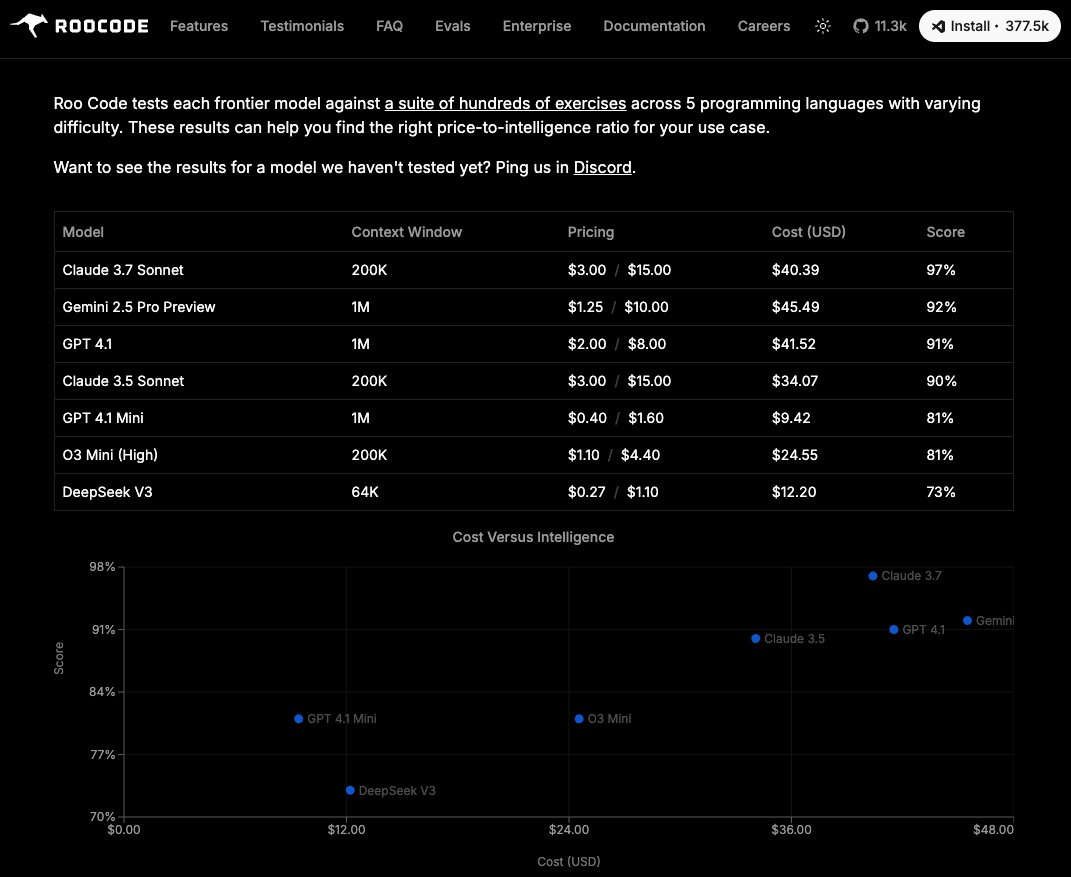
This was by far the largest test run i've done to date, which leads more to why I need to figure out more ways to automate as much of this as possible.
1. Some crazy upsets in my opinion
2. Claude Code continues to fall in overall ranking, which is concerning...
3. Grok Code Fast shows some promise, but seems to get off track easily, so i'm wondering how this would perform using it in an existing large codebase. Example is it would be nearing completion of an eval, see a terminal error and then go down a rabbit hole making things worse trying to fix it. In the real world though the programmer should catch that and redirect it.
Video should drop in about an hour, once its done uploading and processing.

English