JPeg
572 posts








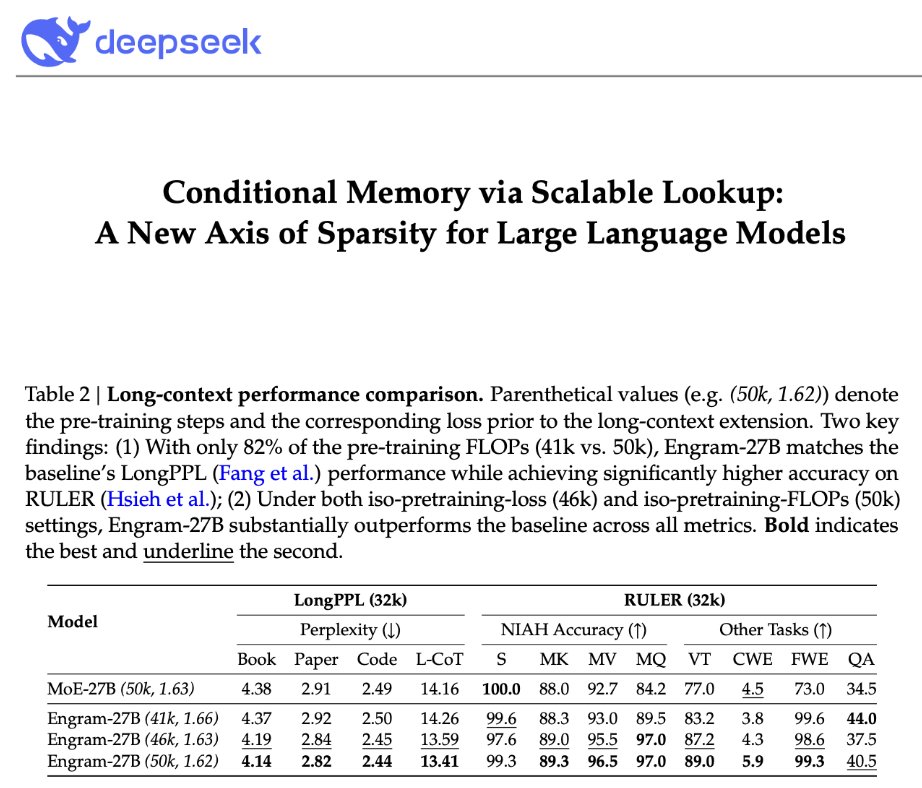
DeepSeek is back! "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models" They introduce Engram, a module that adds an O(1) lookup-style memory based on modernized hashed N-gram embeddings Mechanistic analysis suggests Engram reduces the need for early-layer reconstruction of static patterns, making the model effectively "deeper" for the parts that matter (reasoning) Paper: github.com/deepseek-ai/En…



holy shit it fucking WORKS. SMART FORKING. My mind is genuinely blown. I HIGHLY RECCOMEND every Claude Code user implement this into their own workflows. Do you have a feature you want to implement in an existing project without re-explaining things? As we all know, the more relevant context a chat session has, the more effectively it will be able to implement your request. Why not utilize the knowledge gained from your hundreds/thousands of other Claude code sessions? Don't let that valuable context go to waste!! This is where smart forking comes into play. Invoke the /fork-detect tool and tell it what you're wanting to do. It will then run your prompt through an embedding model, cross reference the embedding with a vectorized RAG database containing every single one of your previous chat sessions (which auto updates as you continue to have more sessions). It will then return a list of the top 5 relevant chat sessions you've had relating to what you're wanting to do, assigning each a relevance score - ordering it from highest to lowest. You then pick which session you prefer to fork from, and it gives you the fork command to copy and paste into a new terminal. And boom, there you have it. Seamlessly efficient feature implementation. Happy to whip up an implementation plan & share it in a git repo if anyone is interested!