Dr. Carlos Toxtli retweetledi
Dr. Carlos Toxtli
13.6K posts


Dr. Carlos Toxtli
@ctoxtli
📜 Assistant Professor @ClemsonUniv 🥼 Director Human-AI Empowerment Lab @ClemsonAI 🤖 Past: Google, United Nations, Snap, Microsoft Research
Clemson Katılım Haziran 2009
3.9K Takip Edilen3.3K Takipçiler

Dr. Carlos Toxtli retweetledi

NVIDIA's Kimodo is the release of the week 🔥
Prompt the timeline whatever your want like: "a person walks forward" → "a person starts jumping", hit Generate, and watch a 3D character do it in seconds
(700hrs of pro mocap training. Works on human + robot skeletons. Super fast + free to use on HF)
English
Dr. Carlos Toxtli retweetledi

Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License
English
Dr. Carlos Toxtli retweetledi

Dr. Carlos Toxtli retweetledi

This joint effort from UIUC, Meta, Google, and other major AI labs presents a unified roadmap for transforming LLMs into autonomous agents capable of planning, acting, and learning in dynamic environments.
Read with AI tutor: chapterpal.com/s/219d7f0e/age…
Read alone: arxiv.org/pdf/2601.12538

English
Dr. Carlos Toxtli retweetledi

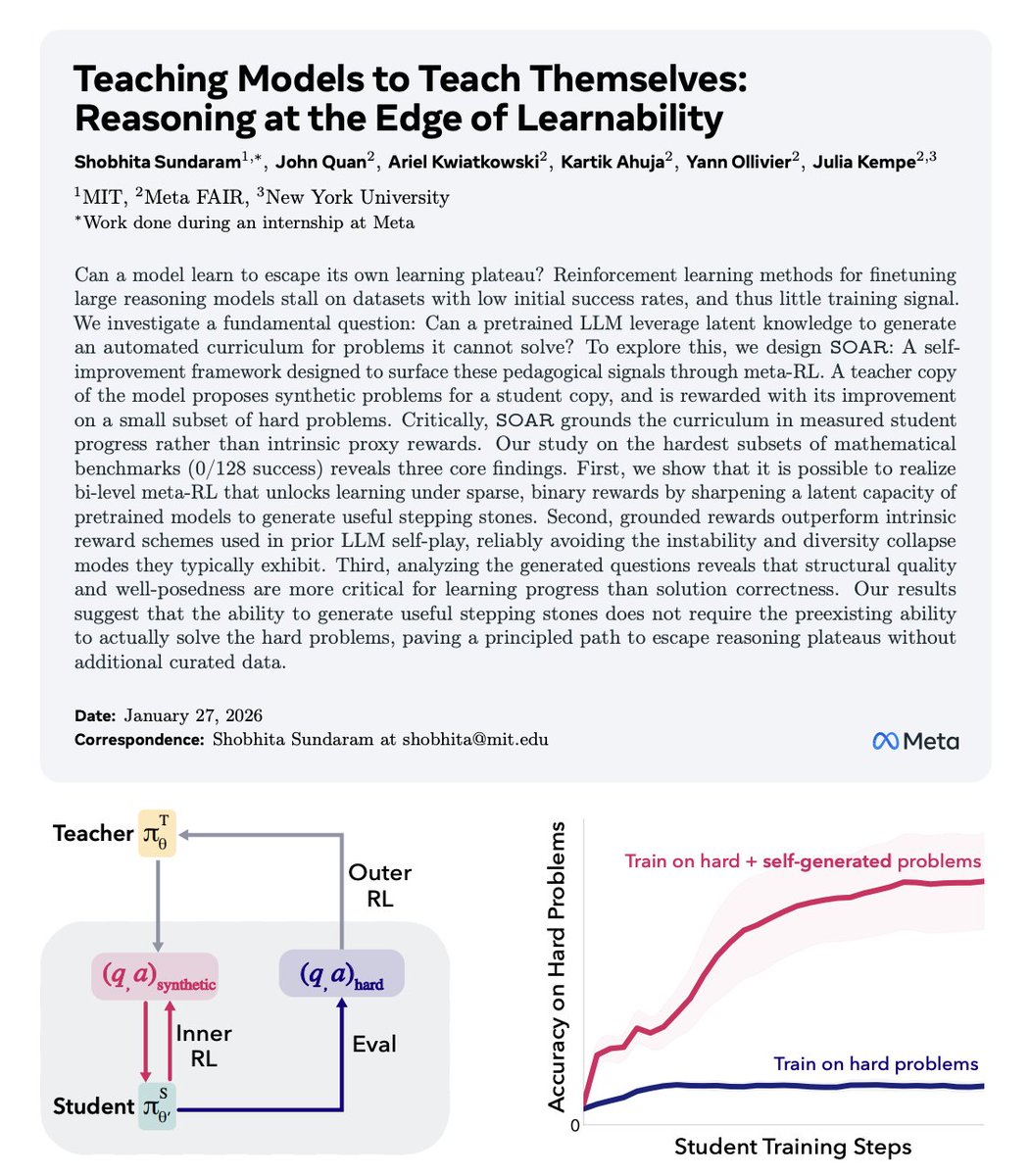
MIT just published a paper that quietly explains why LLM reasoning hits a wall and how to push past it.
The usual story is that models fail on hard problems because they lack scale, data, or intelligence.
This paper argues something much more structural: models stop improving because the learning signal disappears. Once a task becomes too difficult, success rates collapse toward zero, reinforcement learning has nothing to optimize, and reasoning stagnates. The failure isn’t cognitive, it’s pedagogical.
The authors propose a simple but radical reframing. Instead of asking how to make models solve harder problems, they ask how models can generate problems that teach them.
Their system, SOAR, splits a single pretrained model into two roles: a student that attempts extremely hard target tasks, and a teacher that generates new training problems. The catch is that the teacher is not rewarded for producing clever or realistic questions. It is rewarded only if the student’s performance improves on a fixed set of real evaluation problems. No improvement means zero reward.
That incentive reshapes everything.
The teacher learns to generate intermediate, stepping-stone problems that sit just inside the student’s current capability boundary. These problems are not simplified versions of the target task, and strikingly, they do not even require correct solutions.
What matters is that their structure forces the student to practice the right kind of reasoning, allowing gradient signal to emerge even when direct supervision fails.
The experimental results make the point painfully clear. On benchmarks where models start with zero success and standard reinforcement learning completely flatlines, SOAR breaks the deadlock and steadily improves performance.
The model escapes the edge of learnability not by thinking harder, but by constructing a better learning environment for itself.
The deeper implication is uncomfortable. Many supposed “reasoning limits” may not be limits of intelligence at all. They are artifacts of training setups that assume the world provides learnable problems for free.
This paper suggests that if models can shape their own curriculum, reasoning plateaus become engineering problems, not fundamental barriers.
No new architectures, no extra human data, no larger models. Just a shift in what we reward: learning progress instead of answers.
English
Dr. Carlos Toxtli retweetledi

Sequencing a human genome, which once took 13 years and $3B, can now be done in days with the help of AI.
By using AI tools like DeepVariant and DeepConsensus, we’re now helping researchers sequence the genomes of endangered species with incredible speed and accuracy. From the Grevy’s zebra to the African penguin, see how AI is helping pull species back from the brink.
English
Dr. Carlos Toxtli retweetledi

⚡ Google Genie 3 but OPEN SOURCE
Not even 48h later and the Chinese did it again: they just dropped a free real-time playable world generator.
- LingBot-World
- Built on Alibaba's Wan2.2
- REAL-TIME interaction at 16fps
100% open source 🧵
English
Dr. Carlos Toxtli retweetledi

We're helping AI to see the 3D world in motion as humans do. 🌐
Enter D4RT: a unified model that turns video into 4D representations faster than previous methods - enabling it to understand space and time. This is how it works 🧵
English
Dr. Carlos Toxtli retweetledi
Announcing our latest open medical AI models for developers: MedGemma 1.5, which is small enough to run offline & improves performance on 3D imaging (CT & MRI), & MedASR, a speech-to-text model for medical dictation. Both available on Hugging Face + Vertex AI. goo.gle/3L9oiII
#MedGemma #HealthAI #GenerativeAI
English
Dr. Carlos Toxtli retweetledi

Major new research from Google and MIT.
"More agents is all you need" has become a mantra for AI developers. We know multi-agent systems can be effective, but we do this mostly based on heuristics.
The default approach to building complex AI systems today remains adding more agents, more coordination, more communication.
It would be helpful to have a more principled way to scale agentic systems.
This new research introduces the first quantitative scaling principles for agent systems, testing 180 configurations across three LLM families (OpenAI, Google, Anthropic) and four agentic benchmarks spanning financial reasoning, web navigation, game planning, and workflow execution.
The findings:
Multi-agent systems show an overall mean MAS improvement of -3.5% across all benchmarks, with massive variance ranging from +81% improvement to -70% degradation depending on task structure and architecture.
Three dominant effects emerge from the data:
The tool-coordination trade-off: tool-heavy tasks suffer disproportionately from multi-agent overhead. The efficiency penalty compounds as environmental complexity increases.
A task with 16 tools makes even the most efficient multi-agent architecture paradoxically less effective than a single agent.
The capability ceiling: once single-agent baselines exceed approximately 45% accuracy, coordination yields diminishing or negative returns. This is quantified as a statistically significant effect. Additional agents simply cannot overcome the coordination tax when baseline performance is already reasonable.
Architecture-dependent error amplification: independent multi-agent systems amplify errors 17.2x through unchecked propagation. Centralized coordination contains this to 4.4x via validation bottlenecks (these catch errors before propagation).
The presence or absence of inter-agent verification determines whether collaboration corrects or catastrophically compounds mistakes.
The performance heterogeneity is also interesting to look at:
- On parallelizable financial reasoning tasks, centralized multi-agent coordination achieves +80.9% improvement.
- On sequential planning tasks requiring constraint satisfaction, every multi-agent variant tested degraded performance by 39-70%.
- Decentralized coordination excels on dynamic web navigation (+9.2%) but provides essentially no benefit elsewhere.
The researchers derive a predictive model achieving cross-validated
𝑅^2=0.513 that correctly predicts the optimal architecture for 87% of held-out configurations. This model contains no dataset-specific parameters, enabling generalization to unseen task domains.
Overall, architecture-task alignment, not the number of agents, determines collaborative success. The research replaces heuristic guidance with quantitative principles: measure task decomposability, tool complexity, and baseline difficulty, then select a coordination structure accordingly.
Paper: arxiv.org/abs/2512.08296
Learn to build effective AI agents in my academy: dair-ai.thinkific.com

English
Dr. Carlos Toxtli retweetledi

You can now transform LLMs into diffusion models.
dLLM released an open recipe that converts any autoregressive model into a diffusion LLM.
How the conversion works:
1. Remove the causal mask and enable bidirectional attention
2. Mask random tokens and train the model to fill the gaps
3.Add light supervised training to stabilize outputs
English
Dr. Carlos Toxtli retweetledi

This Stanford University paper just broke my brain.
They just built an AI agent framework that evolves from zero data no human labels, no curated tasks, no demonstrations and it somehow gets better than every existing self-play method.
It’s called Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
And it’s insane what they pulled off.
Every “self-improving” agent you’ve seen so far has the same fatal flaw:
they can only generate tasks slightly harder than what they already know.
So they plateau. Immediately.
Agent0 breaks that ceiling.
Here’s the twist:
They spawn two agents from the same base LLM and make them compete.
• Curriculum Agent - generates harder and harder tasks
• Executor Agent - tries to solve them using reasoning + tools
Whenever the executor gets better, the curriculum agent is forced to raise the difficulty.
Whenever the tasks get harder, the executor is forced to evolve.
This creates a closed-loop, self-reinforcing curriculum spiral and it all happens from scratch, no data, no humans, nothing.
Just two agents pushing each other into higher intelligence.
And then they add the cheat code:
A full Python tool interpreter inside the loop.
The executor learns to reason through problems with code.
The curriculum agent learns to create tasks that require tool use.
So both agents keep escalating.
The results?
→ +18% gain in math reasoning
→ +24% gain in general reasoning
→ Beats R-Zero, SPIRAL, Absolute Zero, even frameworks using external proprietary APIs
→ All from zero data, just self-evolving cycles
They even show the difficulty curve rising across iterations:
tasks start as basic geometry and end at constraint satisfaction, combinatorics, logic puzzles, and multi-step tool-reliant problems.
This is the closest thing we’ve seen to autonomous cognitive growth in LLMs.
Agent0 isn’t just “better RL.”
It’s a blueprint for agents that bootstrap their own intelligence.
The agent era just got unlocked.

English
Dr. Carlos Toxtli retweetledi

Google just dropped "Attention is all you need (V2)"
This paper could solve AI's biggest problem:
Catastrophic forgetting.
When AI models learn something new, they tend to forget what they previously learned. Humans don't work this way, and now Google Research has a solution.
Nested Learning.
This is a new machine learning paradigm that treats models as a system of interconnected optimization problems running at different speeds - just like how our brain processes information.
Here's why this matters:
LLMs don't learn from experiences; they remain limited to what they learned during training. They can't learn or improve over time without losing previous knowledge.
Nested Learning changes this by viewing the model's architecture and training algorithm as the same thing - just different "levels" of optimization.
The paper introduces Hope, a proof-of-concept architecture that demonstrates this approach:
↳ Hope outperforms modern recurrent models on language modeling tasks
↳ It handles long-context memory better than state-of-the-art models
↳ It achieves this through "continuum memory systems" that update at different frequencies
This is similar to how our brain manages short-term and long-term memory simultaneously.
We might finally be closing the gap between AI and the human brain's ability to continually learn.
I've shared link to the paper in the next tweet!

English
Dr. Carlos Toxtli retweetledi

gemini 3 pro
• our most intelligent model yet
• SOTA reasoning
• 1501 Elo on LMArena
• next-level vibe coding capabilities
• complex multimodal understanding
available now in Google AI Studio and the Gemini API

English
Dr. Carlos Toxtli retweetledi


Dr. Carlos Toxtli retweetledi
Dr. Carlos Toxtli retweetledi

NVIDIA just released Audio Flamingo 3 on Hugging Face!
This fully open, state-of-the-art Large Audio-Language Model excels at understanding & reasoning across speech, sounds, and music, setting new benchmarks on 20+ tasks.
huggingface.co/nvidia/audio-f…
English
Dr. Carlos Toxtli retweetledi

Today, we are open-sourcing Hunyuan World 1.1 (WorldMirror), a universal feed-forward 3D reconstruction model. 🚀🚀🚀
While our previously released Hunyuan World 1.0 (open-sourced, lite version deployable on consumer GPUs) focused on generating 3D worlds from text or single-view images, Hunyuan World 1.1 significantly expands the input scope by unlocking video-to-3D and multi-view-to-3D world creation.
Highlights:
🔹Any Input, Maximized Flexibility and Fidelity: Flexibly integrates diverse geometric priors (camera poses, intrinsics, depth maps) to resolve structural ambiguities and ensure geometrically consistent 3D outputs.
🔹Any Output, SOTA Results:This elegant architecture simultaneously generates multiple 3D representations: dense point clouds, multi-view depth maps, camera parameters, surface normals, and 3D Gaussian Splattings.
🔹Single-GPU & Fast Inference: As an all-in-one, feed-forward model, Hunyuan World 1.1 runs on a single GPU and delivers all 3D attributes in a single forward pass, within seconds.
🌐Project Page: 3d-models.hunyuan.tencent.com/world/
🔗Github:github.com/Tencent-Hunyua…
🤗Hugging Face:huggingface.co/tencent/Hunyua…
✨Demo: huggingface.co/spaces/tencent…
📄Technical Report: 3d-models.hunyuan.tencent.com/world/worldMir…
English
Dr. Carlos Toxtli retweetledi

🚨 This MIT paper just broke everything we thought we knew about AI reasoning.
These researchers built something called Tensor Logic that turns logical reasoning into pure mathematics. Not symbolic manipulation. Not heuristic search. Just tensor algebra.
Here's how it works:
Logical propositions become vectors. Inference rules become tensor operations. Truth values propagate through continuous transformations.
Translation? Deduction and neural computation finally speak the same language.
This isn't symbolic AI bolted onto deep learning. It's not deep learning pretending to do logic. It's a unified framework where both happen simultaneously.
Every major AI model today hits a wall with consistency because logic is discrete and gradients are continuous. You can't backpropagate through "true or false."
Tensor Logic erases that boundary completely.
The system embeds Boolean reasoning, probabilistic inference, and predicate logic inside a single differentiable framework. That means you can train it end-to-end like a neural network while maintaining logical guarantees.
In experiments, the system performs logical inference as matrix operations. Neural nets can now reason with symbolic precision. Symbolic systems can learn from data like neural nets.
The numbers are wild. The system handles complex logical queries with the same computational efficiency as matrix multiplication. No expensive search. No combinatorial explosion.
But here's the part that should terrify the incumbents: this scales.
Traditional symbolic AI chokes on ambiguity. Neural networks hallucinate logical structures. Tensor Logic gets both right simultaneously.
If this approach spreads, we might finally get models that don't just predict truths they can prove them. Systems that reason with mathematical certainty while learning from messy real-world data.
The implications go way beyond academic AI. Every system that needs both learning and guarantees autonomous vehicles, medical diagnosis, financial systems, legal reasoning just got a new foundation.
Current AI is either good at learning or good at logic. Never both.
That dichotomy just ended.
The fusion of logic and learning isn't coming. It's already here.

English