DRiftingZ
62 posts

因为Claude的用户逻辑是悖论式的,给Claude多充钱的用户,往往是Claude 最讨厌的超重度用户,实际上耗费了Claude 更多的Token资源
充的越多,Claude 赔的越多
理解这个,也就不奇怪Claude 封号逻辑了
卫斯理@imwsl90
群聊了一会儿,发现一个很搞笑的事情 Claude 不充钱,不会被封 冲20刀,不会被封 冲100刀、200刀,封的概率很大 总之,你给他们钱越多,被封的概率越大
中文

笑死我了。因中东战火导致印刷油墨原料供应不足,日本畅销零食公司卡乐比,宣布将把旗下的 14 种零食包装,改成黑白色,以此来节省油墨原料。
由于宣布后,民间影响过于负面,政府今天已紧急约谈该公司。


Meguro-ku, Tokyo 🇯🇵 中文

・日本語が弱い中国系LLM(KIMIとかQwenとか)で日本語出すと频繁にこうなる
・日本语が弱い学习者が读み方分からないから中国語で入力して补うものの、日本語が弱いから简体字と新字体が异なることに气付かずこうなる
ルーピー@RuupiiYukio
こういう「母国語出てしまった」系の「簡体字が混ざった日本語の文章」って、一体どういう入力方法をしたらそうなるのかいつも気になるんだよな。普通に日本語を入力する時は日本語入力キーボードを使う訳じゃん。
日本語





え、嘘だろ...中華モデルのGLM 5がClaude Opus 4.6とGPT 5.3 Codexを上回るスコアを記録した?しかもGPTやOpusと比較して圧倒的に安価で、オープンソース版の公開を予定
BridgeMind@bridgemindai
GLM 5 beats Claude Opus 4.6 and GPT 5.3 Codex in the AICodeKing benchmark
日本語

ε = -x + \text{input}
JiT says we should predict "x" instead of "ε".
This is equivalent to say we should add one U-skip-connection to the ViT in ε-pred:
f(\text{input}) = ViT(\text{input}) + \text{input}
then the ViT part can predict "-x".
机器之心 JIQIZHIXIN@jiqizhixin
Huge! @TianhongLi6 & Kaiming He (inventor of ResNet) just Introduced JiT (Just image Transformers)! JiTs are simple large-patch Transformers that operate on raw pixels, no tokenizer, pre-training, or extra losses needed. By predicting clean data on the natural-data manifold, JiT excels in high-dimensional spaces where traditional noise-predicting models can fail. On ImageNet (256 & 512), JiT achieves competitive generative performance, showing that sometimes going back to basics is the key.
English

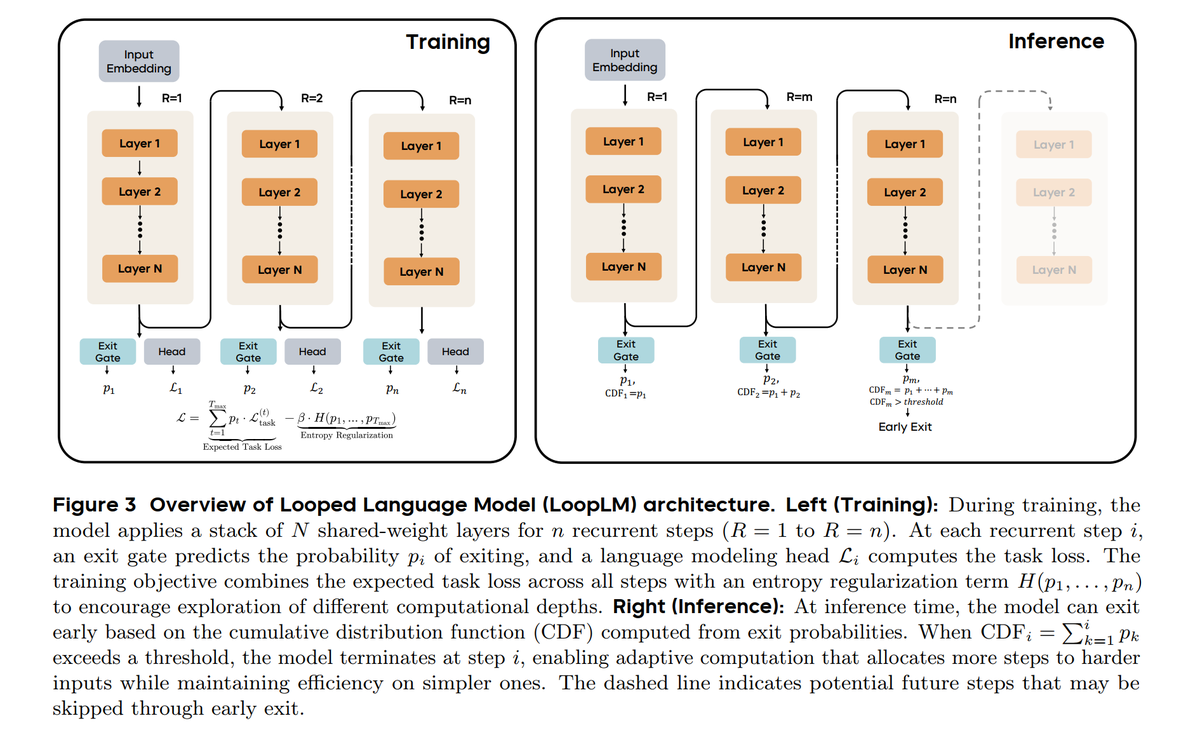
New paper from ByteDance Seed: Scaling Latent Reasoning via Looped LMs
This paper proposes Ouro, which reuse the same layers to think in latent space instead of dumping long chain-of-thought text
2-3x param efficiency + increased performance via iterative latent computation
English

Introducing Pretraining with Hierarchical Memories:
Separating Knowledge & Reasoning for On-Device LLM Deployment
💡We propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge). [1/X]🧵
GIF
English

We’re excited to introduce Text-to-LoRA: a Hypernetwork that generates task-specific LLM adapters (LoRAs) based on a text description of the task. Catch our presentation at #ICML2025!
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Text-…
Biological systems are capable of rapid adaptation, given limited sensory cues. For example, our human visual system can quickly adapt and tune its light sensitivity to our surroundings. While modern LLMs exhibit a wide variety of capabilities and knowledge, they remain rigid when adding task-specific capabilities. Traditionally, customizing these models requires gathering large datasets and performing often expensive, time-consuming fine-tuning for specific applications.
To bypass these limitations, Text-to-LoRA (T2L) meta-learns a “hypernetwork” that takes in a text description of a desired task, as a prompt, and generates a task-specific LoRA that performs well on the task. In our experiments, we show that T2L can encode hundreds of existing LoRA adapters. While the compression is lossy, T2L maintains the performance of task-specifically tuned LoRA adapters. We also show that T2L can even generalize to unseen tasks given a natural language description of the tasks.
Importantly, Text-to-LoRA is parameter-efficient. It generates LoRAs in a single, inexpensive step, based solely on a simple text description of the task. This approach is a step towards dramatically lowering the technical and computational barriers, allowing non-technical users to specialize foundation models using plain language, rather than needing deep technical expertise or large compute resources.
English

new paper from our work at Meta!
**GPT-style language models memorize 3.6 bits per param**
we compute capacity by measuring total bits memorized, using some theory from Shannon (1953)
shockingly, the memorization-datasize curves look like this:
___________
/
/
(🧵)


English

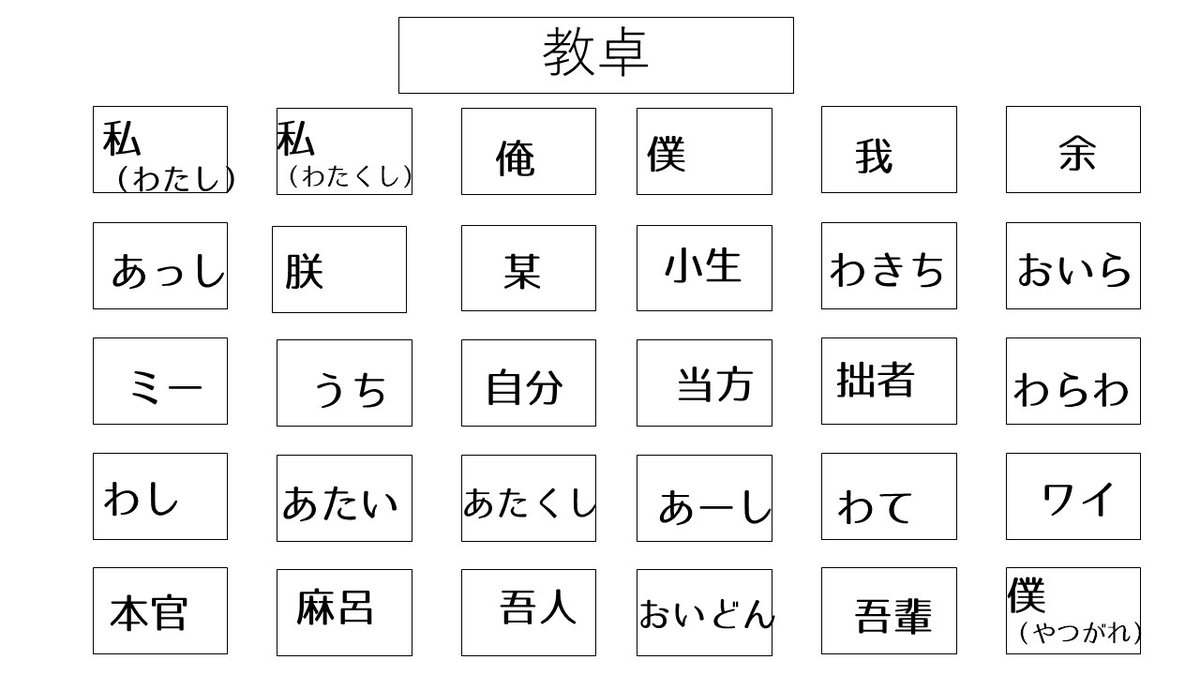
日本語は一人称が豊富な言語です
なので、一クラスの人間全員が違う一人称を使う可能性もあり得るのです。
日本語




I'm 43.
If you're still in your 20s (or 30s), read this:
English