Data_is_King retweetledi

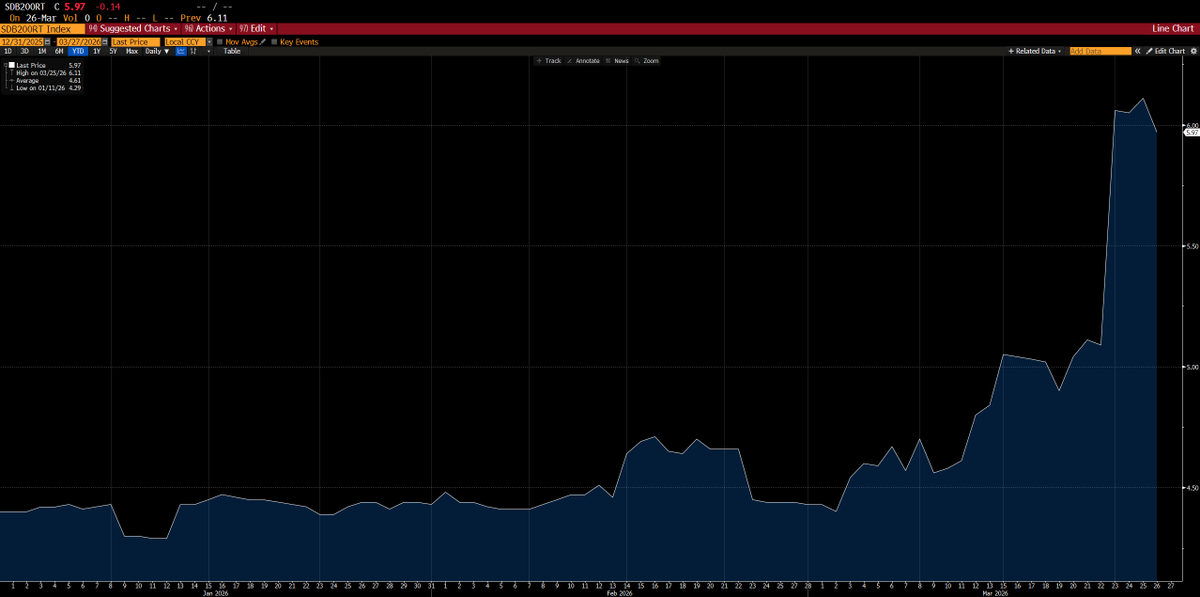
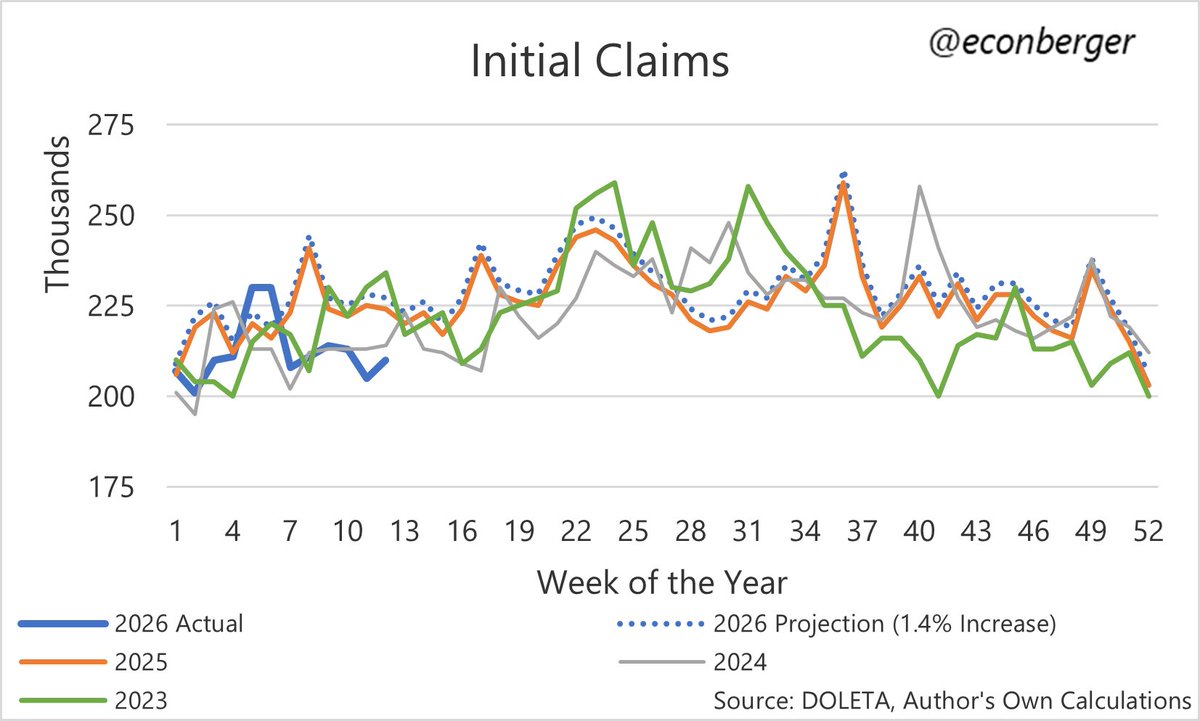
If things feel a bit deflationary at the moment, this is your reminder that due to a bumper April tax haul, the US Treasury is running a short-term, but significant surplus (currently >$250B in April m-t-d).
This temporary reduction in the creation of new sovereign obligations (ie, USD monetary assets) becomes a seasonal factor that adds friction to economic growth (probably thru the summer).
Yes, there are other macro/geopolitical factors, yada, yada... but this surplus doesn't help things until the cumulative effect reverses by Sept-Oct.

English