
Matrixéé 👽🛸
414 posts

Matrixéé 👽🛸
@desillusioniste
/pol
72°00'36.0"S , 168°34'40.0"E Katılım Şubat 2021
1K Takip Edilen64 Takipçiler

je l’ai vu en live c’était épique
Les Spectateurs@SpectateursFr
🔴🇫🇷 Scandale de pédophilie : Hier soir, Dominique Bouvet, ancien vice-président du Comité Départemental Olympique et Sportif de Haute-Saône (70), a été piégé par un internaute utilisant une intelligence artificielle capable d’imiter l’apparence et la voix d’une adolescente se présentant comme âgée de 14 ans. @PoliceNationale
Français

Day 4 of killing Lovable:
Build iPhone Swift apps locally on @getkomand - not possible on lovable
coming for Rork too (u can stop paying $200/mo)
use ur existing GPT/Claude plans
English

Mes potes qui parlent a Juliette ^^

Powlisher@powl_d
C'est lunaire Juliette qui fait une introspection et engeule Orchestria car il a pas push sur github le nullos
Français

on se rapproche du résultat final
vous en pensez quoi ?
commentez
et j’envoie la vidéo YouTube
JA | Ազատ@aubonheurdeja
la voix française est écaltée accent bizarre, son robotique, diction ... j'ai testé : - Kling 3.0 en natif → horrible en français - Grok → pareil - ElevenLabs + lipsync → beaucoup trop long pour faire du volume je sais qu'on est plusieurs à avoir le meme problème si quelqu'un a un workflow qui marche vraiment pour le français on est preneur on a testé plein de truc meme la phonétique etc venez dm
Français

Minara's new home: Hermes Agents✨
Positions, trades, autopliot ... everything you know, running and functioning the same way.
Install Minara Skill with one command in your hermes agent:
curl -fsSL raw.githubusercontent.com/Minara-AI/skil… | bash
English
On n'a pas gagné le hackathon Alan × Mistral.Mais en 8h avec Orchestria, Signa ton companion santé qui connecte tes bilans sanguins, tes données wearable, et une IA vocale. Tout est live 👇
signa.ropau.fr (je vous laisse tabassé mes credits mistral qu'on a eu)
🩸 OCR intelligent Upload une photo ou un PDF de ton bilan sanguin → Mistral OCR 3 extrait chaque biomarqueur automatiquement. Zéro saisie manuelle.
📊 Dashboard santé unifiéHealth Score + Bio Age (PhenoAge, Levine & Horvath 2018). Deux KPIs héros avec count-up animé. Ta santé en un coup d'œil.
🔬 Explorer, 11 biomarqueurs trackésLDL, HDL, Triglycérides, hs-CRP, Glycémie, HbA1c, Ferritine, Vitamine D, TSH, Cortisol, Testostérone. Zone bars style InsideTracker. Projection de tendance en pointillés.
⚡ Cross-signals, la feature qui tueL'IA croise tes données labo + wearable et détecte des patterns qu'aucun médecin ne verrait en 15 min de consultation : → Cortisol ↑ + HRV ↓ = stress chronique → Ferritine ↓ + sommeil profond ↓ = carence en fer → Glucose stable + activité ↑ = métabolisme qui répond
🎙️ Assistant vocal IA Pose une question à voix haute. Voxtral STT → Mistral Small 4 (avec TOUT ton contexte santé) → Voxtral TTS. L'IA te répond avec TA data, pas des réponses génériques.
📁 Coffre-fort documentsBilans sanguins, consultations, imagerie, ordonnances. Filtres par type et période. Chaque document est cliquable avec sa data extraite.
🔔 Centre de notificationsTimeline d'alertes intelligentes : cross-signals détectés, tendances wearable, rappels d'upload, recommandations partenaires Alan (Livi, Petit Bambou, Alan Clinic).
✨ Motion design chirurgicalFade-in-blur sur les textes IA. Cascade séquencée sur les cards. Count-up sur les KPIs. Zone bars qui se remplissent. Bottom drawer avec spring. Chaque pixel est animé avec intention.
🏗️ Stack100% Mistral (OCR 3 + Small 4 + Voxtral STT/TTS). Next.js 15 + React 19 + Tailwind v4 + Supabase + Vercel. Thryve API pour les wearables.

Français
@RayaneRachid_ @daedalium Possible de lancer des sessions opencode depuis son tel ?
Français




Claude Code + Nano Banana 2 is f*cking cracked 🤯
I built a system inside Claude Code that researches any brand, writes 40 ad prompts from scratch, and fires them all to Nano Banana 2.
One brand name + one URL = 40 production-ready static ads.
All inside Claude Code.
I took @alexgoughcooper's brilliant framework and automated the whole thing inside Claude Code.
Perfect for DTC brands and agencies who need high-volume ad creative without briefing a designer or spending hours in Canva.
If you're finding winning ad concepts on Meta and manually recreating them one at a time in Higgsfield — copying prompts, pasting product details, tweaking aspect ratios, downloading, organizing...
This system eliminates the entire loop:
→ Give Claude a brand name and URL
→ It researches the brand's fonts, colors, packaging, and photography style
→ Builds a Brand DNA document from scratch
→ Fills in Alex's 40 proven ad templates (headline, us vs them, testimonial, UGC, review cards, stat callouts) with brand-specific details
→ Fires every prompt to Nano Banana 2 with your product photos as reference
→ Downloads finished ads into organized folders with an HTML gallery
No Higgsfield.
No manual prompt filling.
No copy-pasting between tools.
What you get:
→ 40 ad formats filled with your exact brand colors, fonts, and copy
→ 4 variations per format so you pick the best output
→ Product photos passed as reference so the model matches your real packaging
→ A reusable system — new brand, new folder, same pipeline
Built 100% in Claude Code with Nano Banana 2.
I put together a full playbook & Loom video showing the exact process to set this up yourself.
Want access for free?
> Like this post
> Comment "NANO"
And I'll send it over (must be following so I can DM)
English

@omoalhajaabiola @Replit Too late for me.. but just discovered your account and suscribed !
Helping people try premium stuff to make their ideas by sharing free access is awesome. God bless
English

- step 1
Go to replit.com/signup
- step 2
Verify your account and click on replit core
- step 3
Enter this promo code “REPLITDEVWEEK”
Congratulations, you have one free month of vibecoding with @Replit
English

English


Matrixéé 👽🛸 retweetledi

Nano Banana + MassUGC is insane...
any product, any demographic, any language.
the AI Agent pumps out 300+ 60 second videos PER DAY.
literally market anything🎩🍌
like, rt + comment "mass" i'll send the tutorial:
English
@damienghader @lovable Incredible man, would love to try it
English

Matrixéé 👽🛸 retweetledi

WOW: RFK Jr: “The MMR vaccine that we currently use has millions of particles that were created from aborted fetal tissue, millions of DNA fragments.”
English

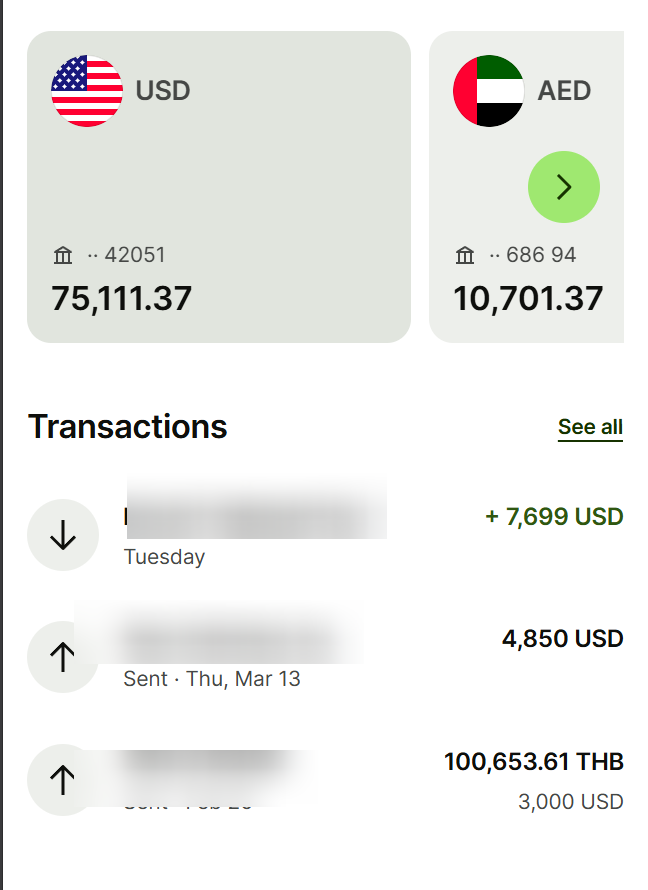
I've made $70K building MVPs using Cursor
(I am a giving a way my playbook)
And I only paid:
- $100 in Cursor tokens
- $17 in @AnthropicAI tokens
- $20/month for Claude/ChatGPT (Often one at a time)
And:
- @boltdotnew for full-stack development
- @lovable for design to MVP development
And they both cost us around $20/month + $50/month
There is no better time than now to be a founder
Comment "MVP" and drop a follow. I’ll DM it to you.
P.S. This will likely blow up, so give me some time to reply.

English

I'm having too much fun coding this 🥹
Introducing the Real-time World Map 🌍 on DataFast!
👀 See your visitors on a 3D globe
💡 Referrer, country, visit counts, etc...
🌓 Light/dark mode, and mobile responsive
If your site goes viral, just press "M" (for Map) and enjoy 🍿
English

