Samuel Fajreldines
131 posts


Samuel Fajreldines
@devindolar
🌐 https://t.co/JYoZPd0pNR
Katılım Şubat 2024
52 Takip Edilen8 Takipçiler
Samuel Fajreldines retweetledi

@ivanfioravanti In my tries, it doens't work well with quantizations. So for many ppl mtp still a better option.
English

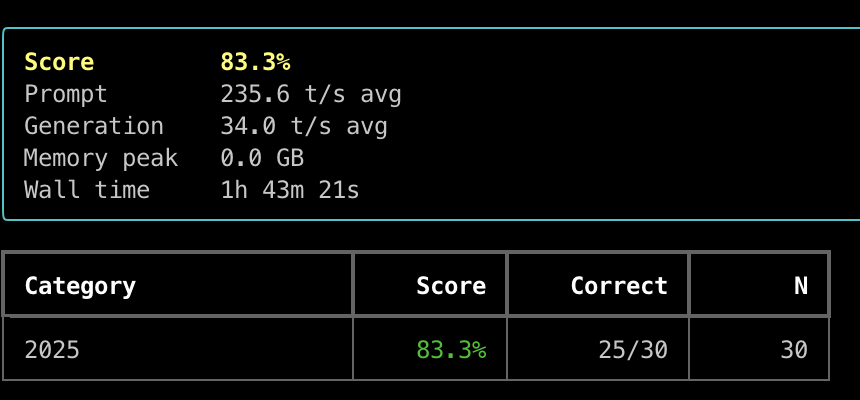
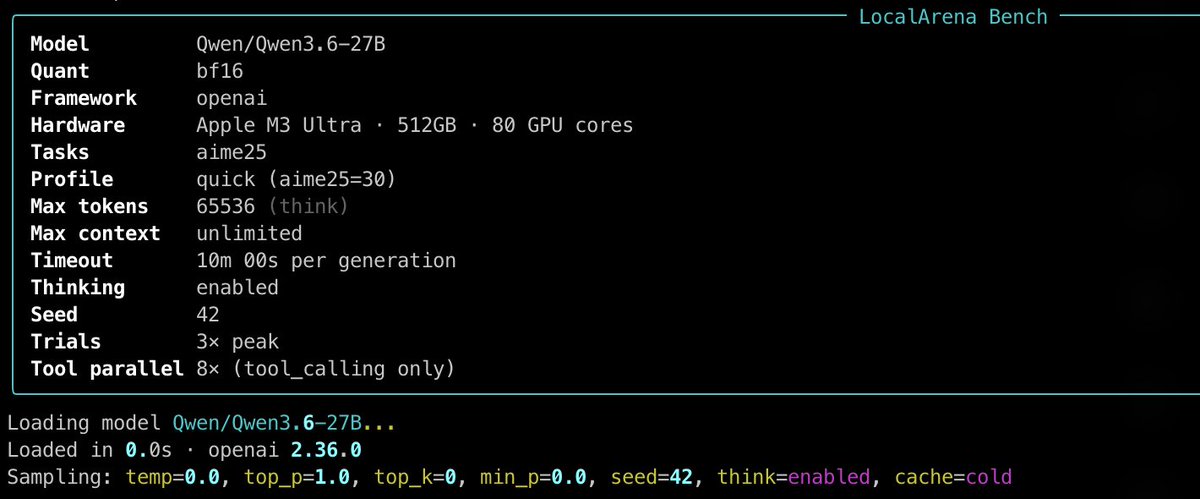
Dflash-MLX 0.1.6 Qwen3.6-27B bf16 with z-lab draft
AIME 25 test on M3 Ultra 512GB
83.3% in 1:43 hours!
Prompt 235.6 t/s srv
Generation 34 t/s srv
This has been much faster than my first MTPLX test, I see shorter thinking traces, probably due to bf16 vs 4bit.
I'll now try 8bit on both engines and I will raise temp to 0.6.
English

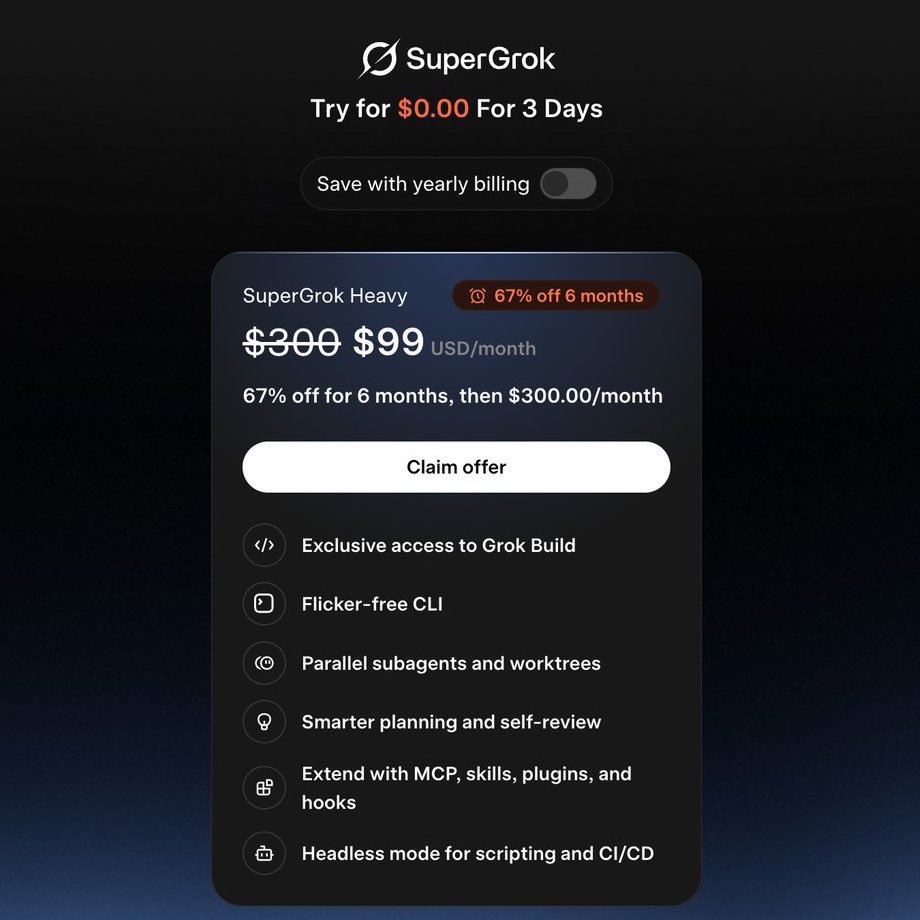
ICYMI 👀: SuperGrok Heavy just dropped to $99/month for 6 months.
That's 67% off the usual $300.
Grok Build beta is live for Heavy subscribers right now. 8 parallel agents, 2 million token context, straight from your terminal.
This is the cheapest the most powerful Grok tier has ever been. Worth trying.
xAI@xai
An early beta of Grok Build, an agentic CLI for coding, building apps, and automating workflows is now available for SuperGrok Heavy subscribers. Through this early beta, we will improve the model and product based on your feedback. Try it at x.ai/cli
English
@ivanfioravanti If you want to try more MTPLX models: huggingface.co/samuelfaj/coll…
:)
My favorite: huggingface.co/collections/sa…
English
MTPLX is keeping up, engine still alive and great results!
So far so good!
M3 Ultra
mtplx-qwen36-27b-optimized-speed
AIME 25 6/30 100% 🤞🏻
English
@DJLougen Awesome work @DJLougen !
This is my new favorite model.
I just optimized for MTPLX (disponible in lightning mlx):
github.com/samuelfaj/ligh…
English

Ornstein3.6-27B-MTP-NSC-ACE-SABER is live.
Qwen3.6 27B MTP base, put through NSC-ACE, SABER, then Ornstein.
MTP preserved -> GGUFs shipping
Yes the name is too long
huggingface.co/GestaltLabs/Or…
huggingface.co/GestaltLabs/Or…

English
@0xPrajwal_ Give a try and be happy: github.com/samuelfaj/dist…
English



@cjzafir Share more about how you’re doing. I’d love to learn.
English


@ivanfioravanti I created github.com/samuelfaj/ligh… to test experimental things that won't fit (for now) in RAPID-MLX
English
Why in the Apple MLX ecosystem, is everyone building a new engine copying from others, instead of contributing and improving existing ones? 🤔
I the last months we have seen an explosions of new engines, all similar. 😢
English

This repo is really good for accelerating the mlx
github.com/raullenchai/Ra…
English
MTPLX of Qwen3.6-35B-A3B-NSC-ACE-SABER for lightning-mlx on Apple Silicon.
huggingface.co/collections/sa…

English
@DJLougen This is an excellent work @DJLougen.
My main model for now.
I've just created MTPLX version:
huggingface.co/collections/sa…
English
Took a bit to do, but here is the Neural Steering Community version of Qwen3.6-A3B-35B model
huggingface.co/GestaltLabs/Qw…
huggingface.co/GestaltLabs/Qw…

English
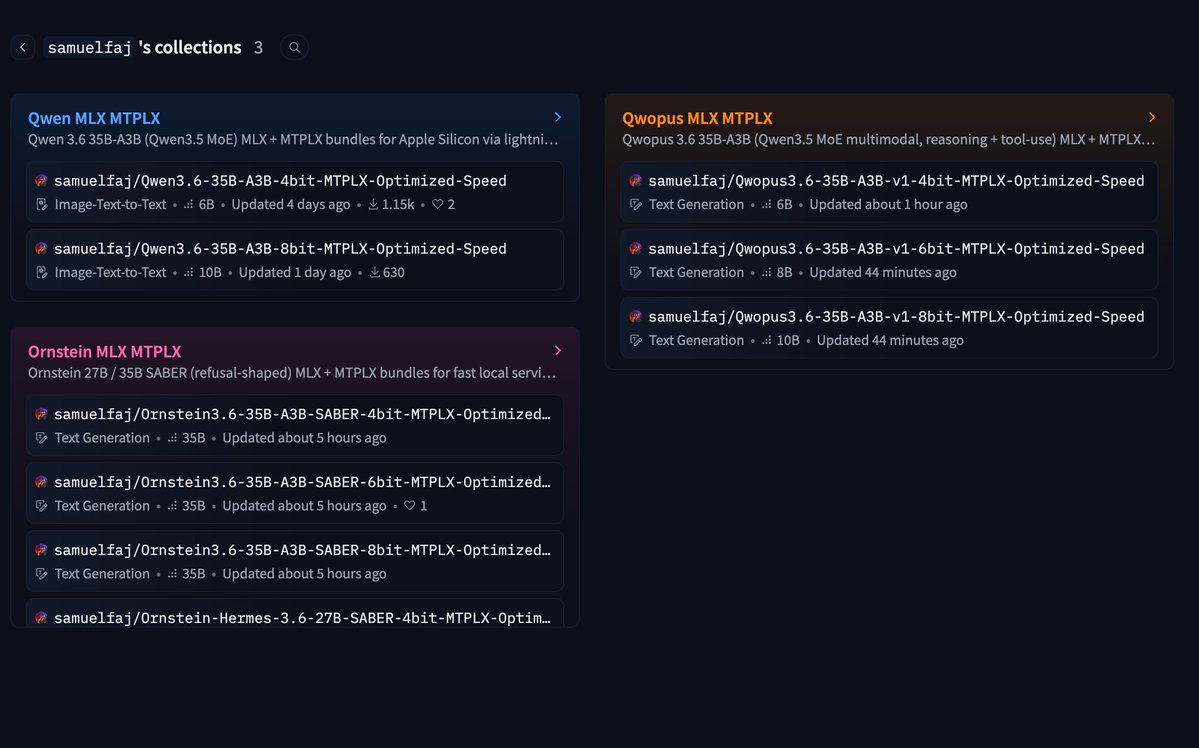
New MTPLX models:
Qwopus MLX MTPLX
Ornstein MLX MTPLX
Qwen MLX MTPLX
huggingface.co/samuelfaj/coll…
#mlx #llm #mtplx
Suomi

M5 Max cluster
72 CPU and 128 GPU cores, 512GB unified Ram
Each MacBook is connected to all the others with Thunderbolt 5 (120Gbit/s).
But I’ll have to use Wi-Fi to connect to the cluster

English


Qwen3.6-27b absolutely flying on a M5Max with MTP enabled & oMLX inference.

Ivan Fioravanti ᯅ@ivanfioravanti
@AlexJonesax Try enabling Native MTP 💪
English

I can't believe people actually still think Anthropic is leading the AI race.
Bro they have no compute:
• No image gen at all
• The model absolutely tanks at peak times
• Mythos is still MIA
• They had to beg xAI for crazy expensive compute
The marketing brainwash is real.
English