Sabitlenmiş Tweet

#ChatGPT as an Analyst
Motivation
I want to ask ChatGPT to estimate the AI market value in 2023 providing the history data.
Here is my question, and the generation output of ChatGPT is astonishing.
English
Brian Dezhou Shen🇨🇳🇬🇧
1.7K posts

@dezhou
Pythonist. Researcher. Data/Computer Scientist. C1@Oxford School of English, United Kingdom. CS Master's@Tsinghua University, China.





🚀 Day 3 of #OpenSourceWeek: DeepGEMM Introducing DeepGEMM - an FP8 GEMM library that supports both dense and MoE GEMMs, powering V3/R1 training and inference. ⚡ Up to 1350+ FP8 TFLOPS on Hopper GPUs ✅ No heavy dependency, as clean as a tutorial ✅ Fully Just-In-Time compiled ✅ Core logic at ~300 lines - yet outperforms expert-tuned kernels across most matrix sizes ✅ Supports dense layout and two MoE layouts 🔗 GitHub: github.com/deepseek-ai/De…

The ranking currently (my opinion), for code: ChatGPT o1-pro o1 o3-mini (all kind of tied) Grok 3 (expected, tbd) Claude 3.5 Sonnet DeepSeek GPT-4o Grok 2 Gemini 2.0 Pro Series (might be higher, will probably move up)


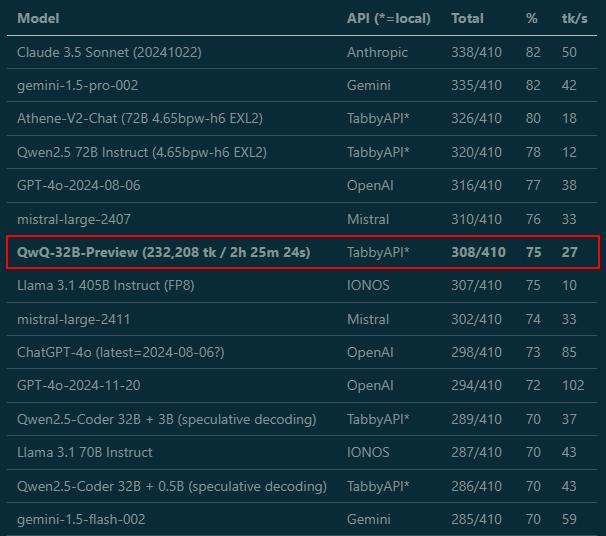
After 350 votes, here are the top open source coding LLMs on CodeArena! Qwen 2.5 Coder 32B is #1 so far, beating out LLMs 10X its size. Followed closely by Llama 3.1 405B & Qwen 2.5 72B.




Another one for python lovers @giffmana @HeinrichKuttler



Jan v0.5.8 is out: Jan supports Qwen2.5-Coder 14B & 32B through Cortex Highlights 🎉 - A new engine: Jan now run models via @cortex_so - @Alibaba_Qwen's Coder 14B & 32B Support - Supports markdown rendering on user messages and various UI/UX enhancements 💫 Update your product or download the latest. jan.ai