Daniel Fabbri retweetledi
Daniel Fabbri
1.3K posts

Daniel Fabbri
@dfabbri
#Professor. #Databases #MachineLearning #HealthIT #Privacy #Security #ML. #Entrepreneur
Nashville, TN Katılım Nisan 2009
4.9K Takip Edilen1.2K Takipçiler

Daniel Fabbri retweetledi

Anyone who’s written software knows that the last 5% can take 95% of the time
Edge cases, conflicts, weird environments, you name it
And for many areas of work, 95% right is still 100% wrong
AI is a remarkable tool and a huge productivity gain. Laws of physics still apply.
English
Daniel Fabbri retweetledi

Jensen Huang: Market is wrong about software stocks
"The notion that AI is somehow going to replace software companies is the most illogical thing in the world and time will prove itself"
Interview date: 3 February 2026
English
Daniel Fabbri retweetledi

We just shipped one of the coolest free database perf tools
It's a SQL execution plan visualizer which helps you spot things like a missing index, full-table scan, or inefficient join
Just paste the EXPLAIN output and find out why your query is slow:
explain.datadoghq.com

English
Daniel Fabbri retweetledi

What a crazy week it’s been here in Nashville. Almost can’t believe what this town (and I know many others in this region) have gone through. The ice storm was devastating and will take months to clean up and years to recover from.
Our street look like a bomb exploded-complete devastation!
Our area is on Day 6 without power-there are many who are really struggling and need help but streets are shut down and it’s hard to get to everyone.
Nashville will eventually recover and comeback stronger but this is still disaster area.
Really appreciate all the Good Samaritans (like my buddy Steve Hannah) and Arborists that are out trying to help as many as they can.
If you have family or friends in this southern region I pray their finding warmth and a place to stay-temperatures this weekend here are going to still be well below freezing. Stay SAFE & Stay STRONG


English
Daniel Fabbri retweetledi

I took the map of Nashville power outages (as of 4pm) posted by NES and made it a little clearer by overlaying major roads:
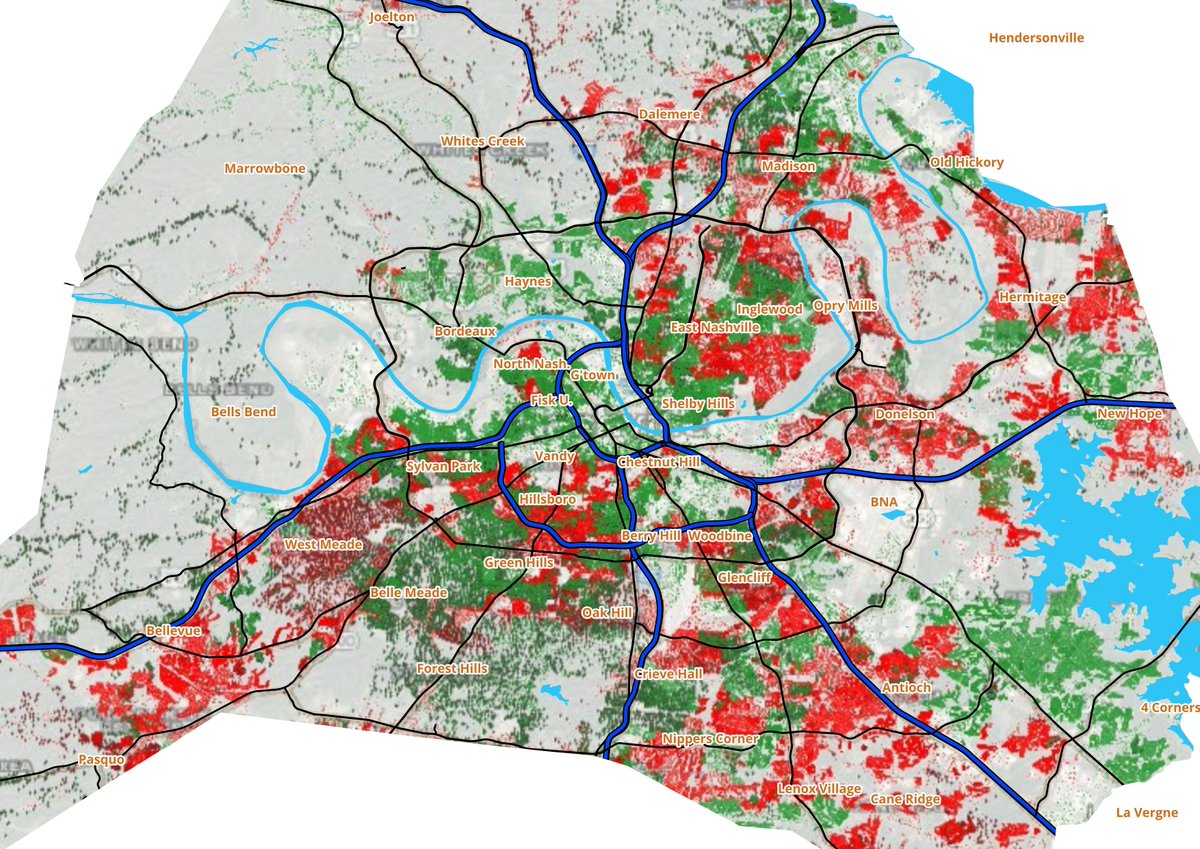
Nashville Electric Service@NESpower
This map highlights restoration efforts since Sunday. Areas where power has been restored are marked in green, while areas still experiencing outages are indicated in red as of 1.28.26 at 4 p.m. Our teams are navigating tough conditions and broken poles, working extended shifts to ensure the quickest possible response. We know the wait is difficult, but we see you, we hear you and we won’t stop until everyone is green.
English
Daniel Fabbri retweetledi

Claude is great at coding. Like really, really good, compared to using a regular LLM like Gemini.
There's only one issue with it. Because it never sees the full code of the app but uses grep search for relevant code snippets, it's myopic.
If grep returns a fragment of code similar to the bug description, it often doesn't look further and fixes an irrelevant part of the app or answers a question based on these fragments found by grep.
So, as the codebase grows, it becomes important for the user to know the codebase. Otherwise, Claude will reinvent the bicycle over and over again, creating duplicate implementations for the same functionalities in different places in the app.
This issue is probably fixable with additional finetuning, but right now this is how it works.
English
Brim Analytics to Participate in ARPA-H Pediatric Cancer eXpansion to Help Scale Best-in-Class Care Nationwide
ARPA-H just announced the Pediatric Cancer eXpansion (PCX) at #JPM with a $50M commitment with partners including AWS, OpenAI, Brim and more. This is a landmark national initiative to accelerate pediatric cancer research and care through AI-guided data sharing.
📈 The Opportunity: Pediatric cancer care depends on critical information buried in clinical notes, pathology reports, and research documentation. But this data is difficult to standardize and share. PCX is changing that by creating an interoperable data ecosystem across 200+ pediatric care centers nationwide.
🎯 What Brim Brings: Our AI-guided data abstraction platform transforms unstructured clinical data into structured, reusable information enabling researchers and clinicians to securely access and learn from real-world patient data across institutions without burdening clinicians or disrupting existing systems.
apnews.com/press-release/…

English
Daniel Fabbri retweetledi

After rewatching Home Alone, I couldn’t stop wondering:
how plausible is the oversleep that leaves Kevin behind?
So I wrote a tiny paper and ran the numbers.
Merry Christmas! 🎄

English
Daniel Fabbri retweetledi

After reading Karpathy's YC talk and year-end review, it's clear that there's a real, defensible layer between foundation models and end users.
The pattern he calls out is "Cursor for X". It's what Cursor revealed about how LLM apps should be architected.
Karpathy identifies four things these apps do:
1. Context engineering. The app decides what goes into the context window. You don't manually copy-paste code files and error logs. The app does the retrieval, embedding, and curation. This is a ton of hidden work.
2. Multi-call orchestration. Under the hood, there are embedding models for your files, chat models for reasoning, models that apply diffs. The user sees one experience. The app runs a whole orchestra.
3. Application-specific GUI. This is undersold. Text is hard to audit. Seeing red/green diffs uses your visual system, which is way faster than reading. Command+Y to accept, Command+N to reject. You're not typing "yes I accept this change" into a chat box.
4. Autonomy slider. Cmd+K changes a small chunk. Cmd+L changes a file. Cmd+I does more autonomous work. The user controls how much the AI does at once.
The human verification step is the bottleneck. AI generates instantly. But you're still responsible for the output. If you get a 1,000 line diff, you have to verify it actually works, introduces no bugs, and has no security issues. That takes time.
So there are two levers:
- Speed up verification (GUIs, visual diffs, good UX)
- Keep the AI on a leash (smaller chunks, clearer prompts)
If your prompt is vague, AI does something unexpected, verification fails, you re-prompt. You're now spinning in a loop. Better to spend more time on a precise prompt that increases the probability of successful verification on the first pass.
"This is the decade of agents"
Right now, with where models are, you want suits. Partial autonomy products where the human stays in the loop, the generation-verification cycle is fast, and there's an autonomy slider you can push right over time.
Suits augment. Robots operate autonomously. The suit still has a human making decisions. The robot flies around on its own.
Build Iron Man suits, not Iron Man robots.

jack@jack
English
Daniel Fabbri retweetledi

Warren Buffett signs off his final investors’ letter with advice for the ages.

English
Daniel Fabbri retweetledi

Why can AIs code for 1h but not 10h?
A simple explanation: if there's a 10% chance of error per 10min step (say), the success rate is:
1h: 53%
4h: 8%
10h: 0.002%
@tobyordoxford has tested this 'constant error rate' theory and shown it's a good fit for the data
chance of success declines exponentially

English
Daniel Fabbri retweetledi

Every day for the next 10 days is a palindromic date (the same number backwards):
5/20/25
5/21/25
5/22/25
5/23/25
5/24/25
5/25/25
5/26/25
5/27/25
5/28/25
5/29/25
English
Daniel Fabbri retweetledi

"The moat in AI products is built through 1,000 tiny paper cuts" - @rossmcnairn, cofounder at Wordsmith
If you want a moat with an AI product, you need to iron out all the tiny details that annoy users with your product.
Anyone can copy an AI product. Not anyone can copy one pleasant to use that "just works" just as expected
English
AWS Bedrock's Cross-Region Inference has the awesome potential to automatically scale AI throughput as usage demands spike. However, what happens if your health system sets an organizational security policy to restrict data to a subset of the AWS cross-region inference regions (e.g. data can only be stored in us-east-1 or us-east-2, but not us-west-2)?
Interestingly, in these cases, AWS cross-region inference is automatically blocked!!! The organization's security policy hard-stops the usage of the resource.
While there are options to do single-region inference, this comes with potential limited AI throughput or limited model availability.
This is was a surprising edge case that organizations will need to consider as they utilize AI on top of a multi-region architecture.
Follow Up: Organizations choose to limit data to specific AWS regions to limit data exposure and limit access points to monitor.
aws.amazon.com/blogs/machine-…
English
Advanced LLM reasoning is exciting. But, do you know what else is exciting? Being able to process every clinical note in an electronic medical record system to abstract relevant data for clinical trial matching, oncology disease progression and even identify pickle ball injuries.
We are starting to reach a cost + reasoning inflection point where, for thousands of dollars, we can abstract data across a million patients with good quality.
At Vanderbilt, the AI-Guided Chart Abstraction System (Brim) has been leveraged for over 12B tokens for under $6K for over 40 projects.

English
Daniel Fabbri retweetledi

Health technology is balancing act: system efficiency, data privacy, user experience (among others). Obviously, a lot of talk at ViVE was about AI. Similarly, there was a lot of talk of using AI appropriately. Here is a trend I am seeing...
- Over the last decade, health organizations have moved a lot of data to the cloud (either their own or vendors' cloud).
- As governance, privacy and security become increasingly more paramount, we will see more vendor applications running within healthcare organizations' cloud tenant (i.e within a hospital's AWS / Azure / GCP tenant).
- Vendor applications will have to leverage healthcare-organization-provided AI / LLM resources, in part to limit data egress and increase data controls.
Building Health IT applications that allow healthcare orgs to "Bring Their Own LLM" will likely be required going forward.

English
Daniel Fabbri retweetledi

Precision meets speed in clinical trials. 🌟 Learn how AI can unlock faster enrollment for studies with complex eligibility criteria. Blog post: brimanalytics.com/post/faster-en… #ClinicalTrials #AIinMedicine #HealthcareAI
English
Don’t Settle for 5%: Brim Unlocks a Wider Patient Pool for Clinical Trials
Clinical trial enrollment is one of the most significant bottlenecks in advancing medical research. Poor participant recruitment is the leading reason for premature discontinuation of randomized clinical trials, particularly investigator-initiated ones. Only 3-5% of candidates get matched today.
Brim allows clinical trail sites to define fine-grained matching criteria (such as 12 months have passed since surgery or last chemo until cancer recurrence) to identify candidate patients, drastically reducing manual review.
brimanalytics.com/post/faster-en…
English