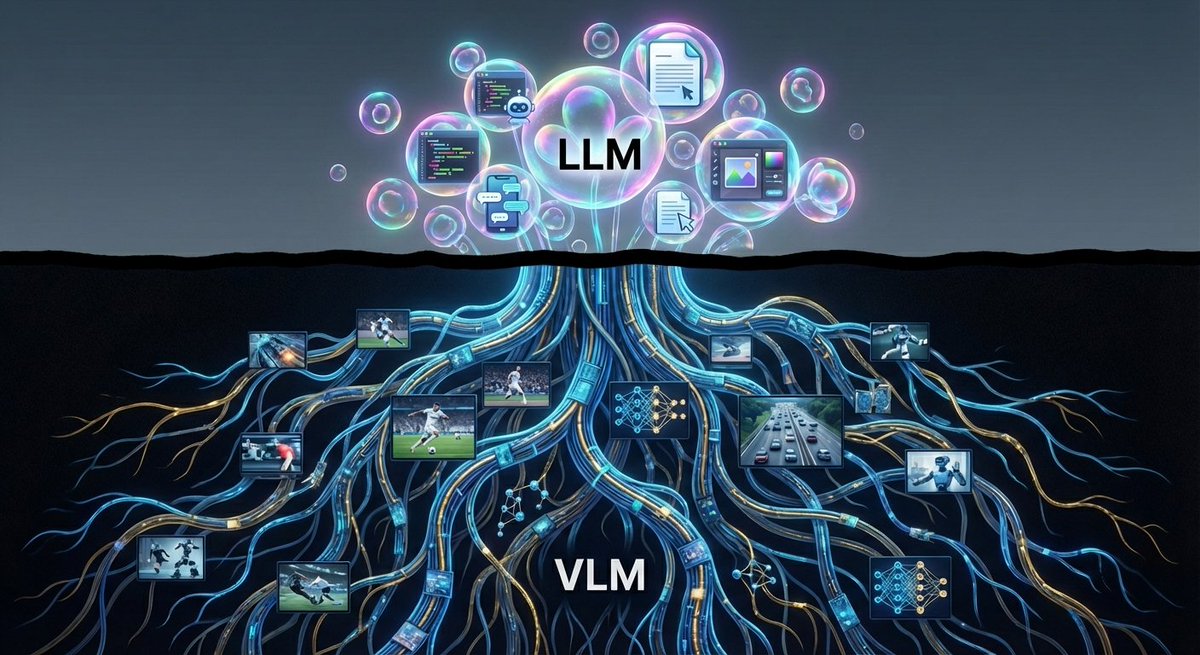
Sabitlenmiş Tweet

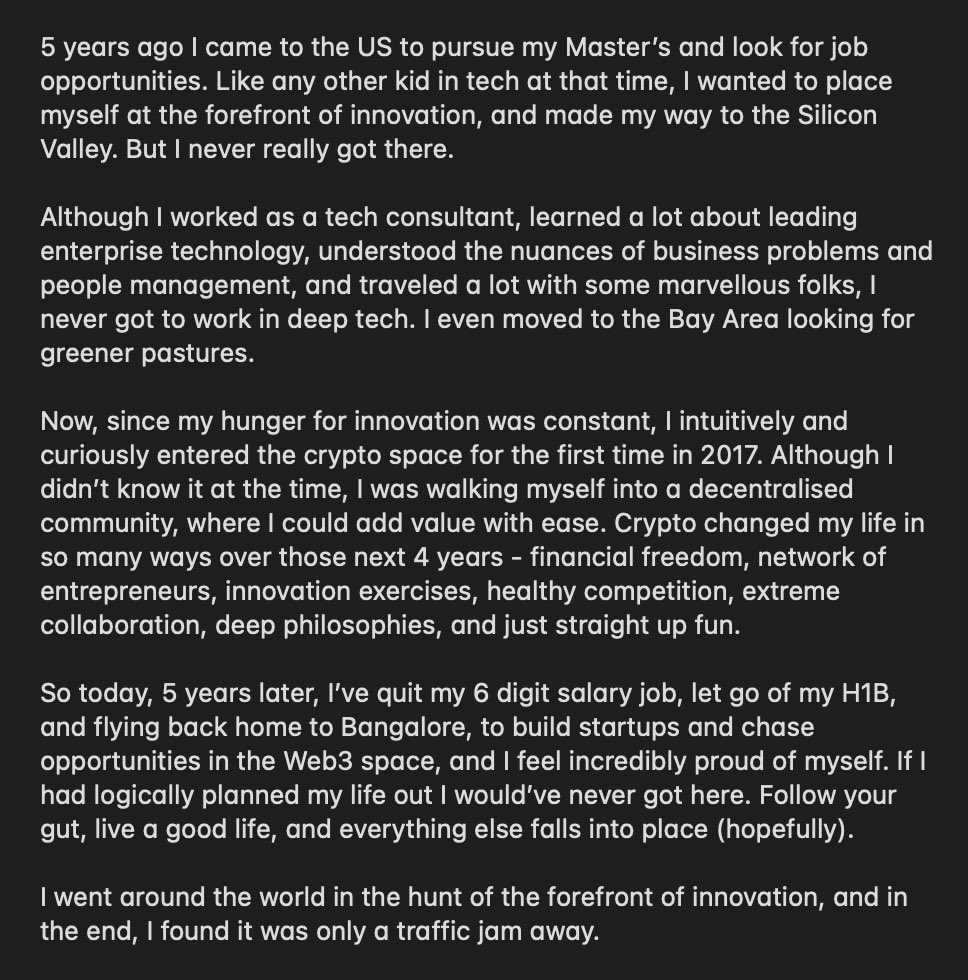
Today, I feel free.
I’m happy to be back home in Bangalore, and what an amazing journey I’ve had. I’m extremely grateful to every single person in my life who’s helped me get here.
Thank you, everyone.
Thank you, Satoshi Nakamoto.
English