Diffio AI
26 posts
Diffio AI
@diffioai
Audio restoration for podcasts. Visit https://t.co/KxDOlns8Wq for more.
Colorado Springs Katılım Kasım 2025
5 Takip Edilen6 Takipçiler

@diffioai Really interesting idea behind Diffio.
I’m a SaaS writer and a few content ideas came to mind while checking it out — happy to share if useful.
English
@viraataryabumi @Julianfmack @TheOneKloud github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

state-of-the-art ✅
open weights ✅
apache 2.0 ✅
multilingual ✅
we cooked. tip my hat to @Julianfmack and @TheOneKloud! legends! 🐐
Cohere@cohere
Introducing: Cohere Transcribe – a new state-of-the-art in open source speech recognition.
English
@tomaarsen @cohere github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

This is a very solid release! Apache 2.0 as well, 2B parameters (i.e. quite runnable), 14 languages, and supported using Transformers already. Great work @cohere 👏
Cohere@cohere
Introducing: Cohere Transcribe – a new state-of-the-art in open source speech recognition.
English
@TheOneKloud github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

Blog post : cohere.com/blog/transcribe
Technical blog post : huggingface.co/blog/CohereLab…
Model card : huggingface.co/CohereLabs/coh…
Pierre Richemond 🇪🇺@TheOneKloud
Excited and proud to introduce our latest: Cohere Transcribe, the best dedicated ASR model in the world. #1 EN HF leaderboard, SotA human evals, ahead of ElevenLabs, Qwen3, Mistral, Kyutai, and OpenAI. 14 supported languages. Apache 2.0, on HF for you to try. Our first audio model and a key step in powering North experiences. huggingface.co/CohereLabs/coh…
English
@fahdmirza github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

💥 Cohere Transcribe is HERE and it's OPEN SOURCE 🎙️
♠ A free 2B parameter ASR model you can run locally — Audio In, Text Out 🚀
🔹 14 languages supported: English, French, German, Arabic, Japanese, Korean & more
🔹 Conformer architecture — built from scratch for speech, not repurposed
🔹 Up to 3× faster real-time factor than other dedicated ASR models of the same size
🔹 Apache 2.0 license — fully free, no strings attached
🔹 Works on your own GPU, your own data, no API calls, no cost
🔥 Watch the full demo below 👇
English
@ClementDelangue @nickfrosst @huggingface @cohere github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

Got to meet @nickfrosst in Miami today to celebrate their awesome release of an open-source Apache 2.0 Transcribe model that could be a whisper killer and already trending on @huggingface!
@cohere deserves much more visibility in the community as one of the leaders of North American open-source!

English
@jaxson @cohere github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

If you regularly transcribe audio, @cohere Transcribe was just released - it's a free, open-source model that runs locally and is definitely worth checking out. I ran some tests against OpenAI's Whisper (which powers ChatGPT and many other apps).
I used Steve Jobs' 2005 Stanford Commencement Address (15 min) on YouTube as the test video. Both models running locally on a MacBook M4.
Some highlights of what each model heard:
Cohere: "I learned about serif and sans serif typefaces"
Whisper: "I learned about Sarah and Sans Sarah of typefaces"
Cohere: "Bob Noyce"
Whisper: "Bob Nois"
Cohere: "tried to apologize for screwing up so badly"
Whisper: "tried to apologize for sparing up so badly"
I also tested Whisper's largest model (1.55B parameters) to get a closer comparison to Cohere's 2B parameters. It fixed some of the name errors but started repeating phrases and took much longer.
How they compared:
- Cohere (2B params): 119 seconds, ~98% accuracy
- Whisper base (74M params): 69 seconds, ~90% accuracy
- Whisper large (1.55B params): 915 seconds, ~93% accuracy
Full side-by-side transcript comparison: github.com/jaxson/tests-p…
(Note I believe that some of the different word counts stem from hallucination loops that were encountered by Whisper).
Cohere Transcribe Model on Hugging Face: huggingface.co/CohereLabs/coh…
Test video on YouTube: youtube.com/watch?v=UF8uR6…
* Results may vary based on hardware, audio quality, and content. This is a very non scientific test!
**Audio clips used under fair use for commentary/analysis. All rights belong to their respective owners.

YouTube
English
@Tu7uruu github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful. I also added automatic language detection.
English

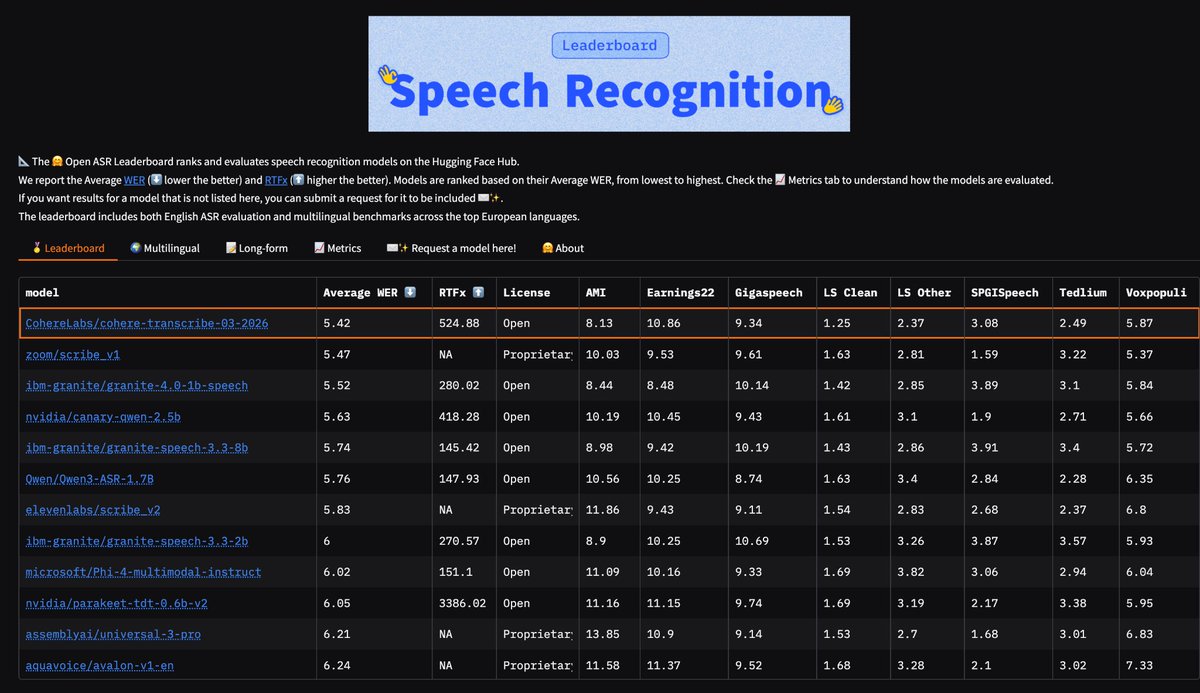
Just dropped on HF: Cohere’s cohere-transcribe-03-2026
> 🥇 #1 on the Open ASR leaderboard
> 🌍 #4 multilingual
> 📄 #6 long-form
> Supports 12+ languages: English, German, French, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Chinese, Japanese, Korean
> Conformer-based encoder + lightweight Transformer decoder for transcription
> And of course: Apache 2.0 license
English
@psk90_ai github.com/Diffio-AI/Cohe… WhisperX style interface for cohere. Has VAD (cohere recommends) and word alignment which is always helpful.
English

Cohere just took #1 on the Hugging Face Open ASR Leaderboard. First speech model. 5.42% WER. Open source.
━━━━━━━━━━━━━━━━━━━
Cohere Transcribe. Their first speech-to-text model — and it immediately tops the English accuracy charts.
→ 5.42% word error rate — #1 on HuggingFace Open ASR Leaderboard
→ Validated by human evaluation, not just automated benchmarks
→ One of the strongest accuracy-to-speed ratios at its size class
→ Minutes of audio → usable transcripts in seconds
→ Open source — download weights directly from Hugging Face
━━━━━━━━━━━━━━━━━━━
The bigger picture:
This isn't a standalone model release. Cohere is building toward full enterprise speech intelligence inside North — their agentic AI orchestration platform.
Translation: your AI agent will soon listen, transcribe, reason, and act — all within one enterprise platform. Transcribe is the ears.
The ASR space just got very crowded very fast. In the last few months: Mistral Voxtral, IBM Granite Speech, ElevenLabs Scribe, and now Cohere Transcribe — all pushing open-source ASR past what Whisper could do.
🔗 Blog: cohere.com/blog/transcribe
🔗 Model: lnkd.in/ggfeZye5
Building enterprise speech pipelines — transcription, voice agents, real-time audio processing — on-premise? That's what we do at Zingaro AI and LiteCompute AI. DM me.
♻️ Repost if useful.
Follow Pasha S for daily open-source AI drops.
English
@mr_r0b0t @cohere @NousResearch @LottoLabs @sudoingX github.com/Diffio-AI/Cohe… WhisperX style interface for cohere.
English

Huge news for local transcription!
Thanks @cohere, my @NousResearch Hermes agent will love this!
@LottoLabs @sudoingX
huggingface.co/CohereLabs/coh…
English
@nickfrosst @cohere @huggingface Just made a whisperX style interface for cohere. github.com/Diffio-AI/Cohe…
English

@cohere just released the best speech->text model :)
It currently ranks #1 for accuracy on @huggingface Open ASR Leaderboard, setting a new benchmark for real-world transcription performance. Read more 👇

Cohere@cohere
Introducing: Cohere Transcribe – a new state-of-the-art in open source speech recognition.
English
@cohere Love it. Just made a whisperX style interface for it with VAD and word alignment. github.com/Diffio-AI/Cohe…
English


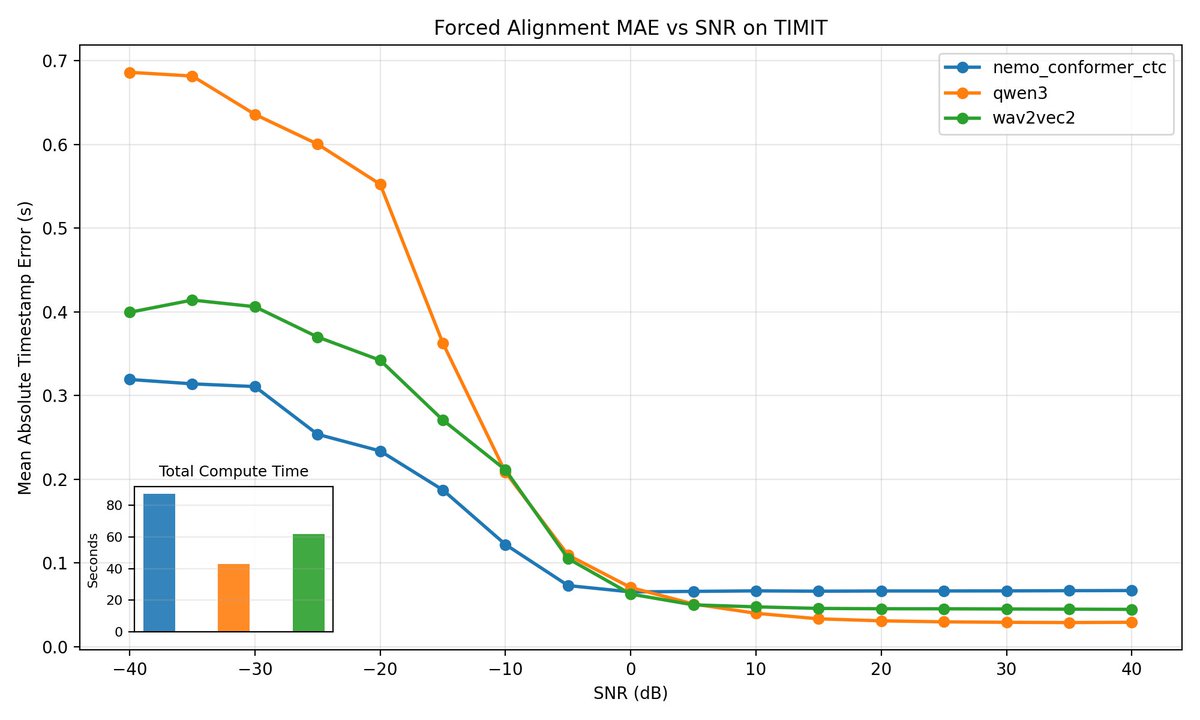
- OpenAI Whisper timing github.com/openai/whisper
OpenAI Whisper timing uses Whisper’s internal alignment heads and decoder cross-attention, then applies DTW over the token-to-frame attention matrix to derive word timestamps from the token sequence.
English

- whisper-char-alignment github.com/30stomercury/w… whisper-char-alignment Whisper’s own decoder cross-attention maps, teacher-forces the reference text at character level, and uses DTW plus attention-head aggregation to infer word boundaries.
English
- WhisperX github.com/m-bain/whisperX
WhisperX performs forced alignment with an external phoneme/CTC aligner, typically a wav2vec2-based model, to align a known transcript to the waveform and recover word timestamps.
English
Codex Wrapped 2025
Total Tokens: 3,073,600,806
Total Messages: 1,782
Total Sessions: 512
Top model: GPT 5.2 Codex
Total Estimated Cost: $814.14
Credit: @nummanali @moddi3io

English