Sabitlenmiş Tweet

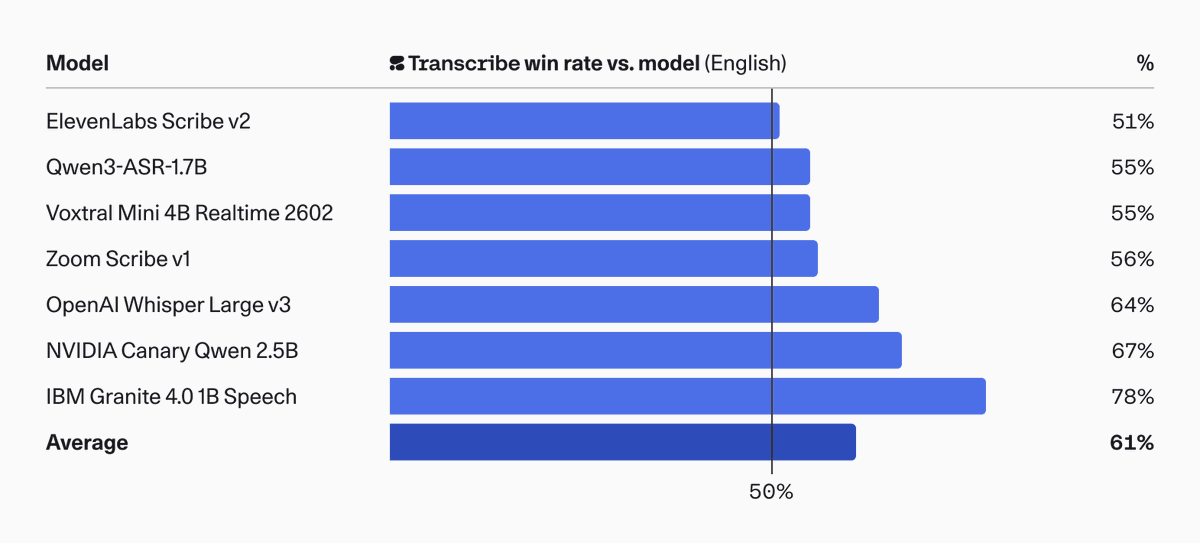
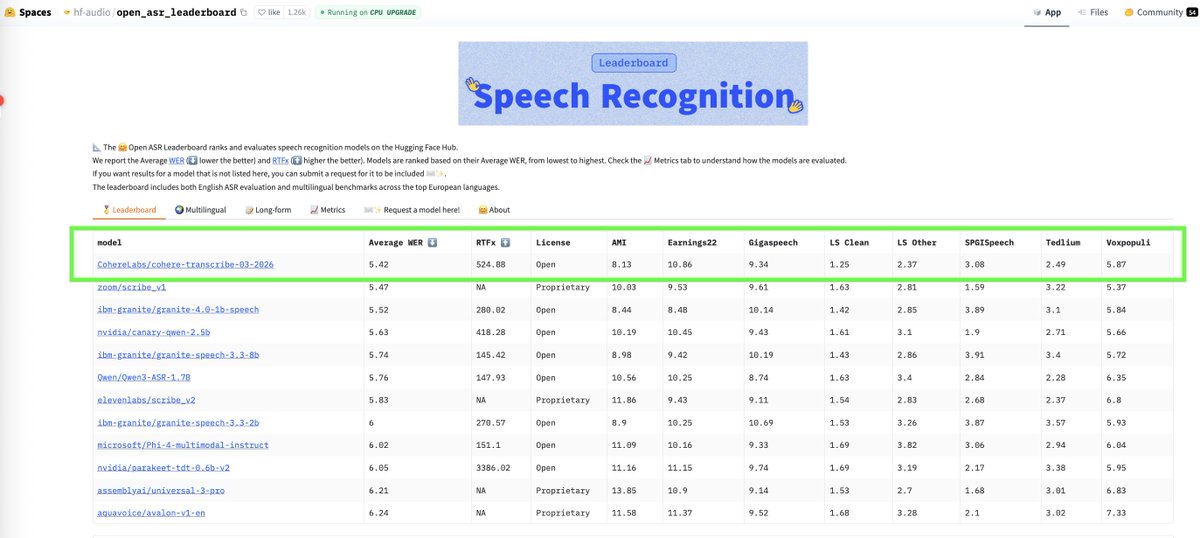
Happy to share what I've been working on recently: today we release Cohere Transcribe, a state-of-the-art speech recognition model that beats both commercial and open-source models to land at #1 on the Open ASR Leaderboard!
English