Pengyu Zhao@zpysky1125
MiniMax M2 Tech Blog 3: Why Did M2 End Up as a Full Attention Model?
On behave of pre-training lead Haohai Sun. (zhihu.com/question/19653…)
I. Introduction
As the lead of MiniMax-M2 pretrain, I've been getting many queries from the community on "Why did you turn back the clock and go with full attention with MiniMax M2?" After explaining the backstory in one chat after another, I figured it's time to write down our journey in a blog.
Honestly, I could give you the textbook debate. I could talk all afternoon about why you should build linear/sparse attention. Then, I could turn around and talk all afternoon about why you shouldn't. But what's the point of all that hand-waving? The real question is whether you should actually do it.
So, let's start with the conclusion: We are always working on it. But in a real-world, industrial-grade system, the truth is that efficient attention still has some way to go before it can definitively beat full attention. As LLMs have evolved, the entire stack has become monstrously complex. We serve more scenarios, and the architecture design trade-offs are exploding: "How does it perform on code and math? What about agent scenarios? How does it handle multimodality? Does long-chain CoT still hold up? Can RL scale on top of it? Are there hidden traps with low-precision compute? How do you implement interleaved thinking, caching, or speculative decoding? ... "
In short, there's a vast difference between the promise on paper and its payoff in production. You only get to claim that payoff after satisfying Condition 1...n and solving Problem 1...n.
II. Why Efficient Attention?
Let's do a thought experiment. If you had infinite compute, would you even bother with linear or sparse attention? Some might bring up theoretical arguments about softmax attention "oversmoothing" in an infinite context... but who knows? Under the current compute bound, no model has truly pushed softmax attention to its absolute limit. So, for all practical purposes, the race for efficient attention is a race to save compute.
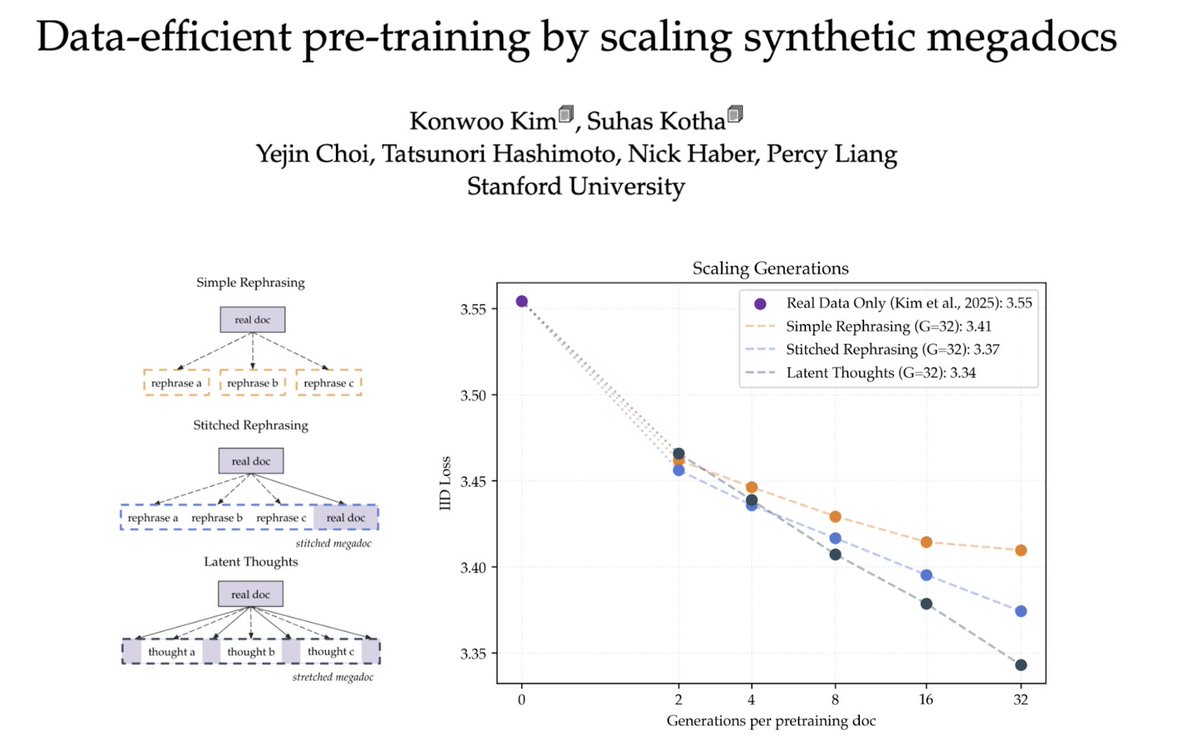
For our M2 design, could we aim to save tokens — achieving the same quality with fewer tokens? Well if you believe in scaling laws, to achieve this goal, you'd probably bet on other paths to get there, not efficient attention.
So, the simple truth is this: Compute is finite. We need an architecture that makes better use of it — models that achieve higher performance under the same budget (training & inference).
III. The Real Bottlenecks
To build a model that can practically be deployed and used by the community, we have to start with what users care: Quality, Speed (TPS), and Price. Quality is non-negotiable. A useless model is useless even if it's free. So how do we make a Linear/Sparse/Hybrid Attention model that performs well enough? The biggest challenge here isn’t the architecture design — the real bottleneck is the limitations of evaluation. (As for speed and price, those are heavily influenced by the inference stack—and great models tend to attract great engineers to optimize them.)
The Evaluation Trap: Goodhart's Law in Action
“As long as you build the benchmark, I’ll find a way to beat it.” Over the past few years of LLM development, the pace of leaderboard progress is staggering. No matter how hard a benchmark is — even if the SOTA score starts in single digits — once it catches the industry’s attention, it’s usually crushed within a few iterations. But how do you build an evaluation system that is comprehensive and actually reflects a model's true capabilities? That’s one of the hardest — and most critical — problems in LLM development, and it becomes even more acute when you start messing with a component as fundamental as attention.
Benchmarks are a Leaky Abstraction
There’s no free lunch. When you reduce the complexity of attention, you pay a price. The question is, where?
When we were developing MiniMax-Text-01, everyone was still evaluating MMLU, BBH, MATH, and LongBench (all of which are now saturated). From the perspective of a year ago, a hybrid of Lightning Attention and Full Attention looked just as good as pure full attention. Our own small-scale hybrid models confirmed this on the leaderboards. (Did we find a free lunch?)
Not quite. The price paid became obvious at a larger scale: the model had clear deficits in complex, multi-hop reasoning tasks.
Okay, once a problem is exposed, you can fix it. We developed proxy metrics for this specific weakness and iterated until the hybrid model seemed to match MHA. But does that proxy metric still correlate with real-world downstream performance at an even larger scale? Are there other hidden weaknesses? Who knows. We haven't run those experiments yet.
The better the models get, the harder they are to evaluate. But that’s a must part of the journey — keep it up, eval teams!
The High Cost of Knowing Things
For complex reasoning tasks, we can sometimes find early proxy metrics that correlate well with final performance — but not for all tasks (at least, not yet). As tasks get harder, the amount of experiment compute required just to get a statistically significant signal on your metric grows astronomically — which is ironic, since we study efficient attention because compute is limited.
And beyond the academic benchmarks, optimization issues often only surface at scale. You never really know what’s going to happen until you scale up. Anyone who read our M1 paper will recall the serious precision issues we hit during RL training — problems that would’ve been spotted earlier. Going back and analyzing Lightning Attention's numerical convergence with that experience in hand was incredibly clarifying.
Discovering the real problems is often far harder than solving them.
A Symphony of Variables
There are just too many variables in model training. Different architectures behave very differently on different data distributions and with different optimizers. In a world where our data is constantly being updated, an experiment run on last month's data mix might yield the opposite conclusion today.
We can’t observe everything perfectly — but we’re working on finding more reliable experimental strategies.
Infrastructure: Where Theory Meets Metal
Compared to full attention, the infrastructure for linear and sparse attention is much less mature. To actually get the promised results, there’s still a lot of groundwork to fill in.
Take linear attention for example: If you analyze the compute intensity of existing linear architectures, many of them are memory-bound — even during training. Without extreme IO optimization, you’re basically leaving a huge amount of GPU FLOPs on the table. And inference brings even more challenges than training: How do you deliver a service that is genuinely faster and cheaper? Linear attention has linear compute complexity and constant memory usage. That means there’s a crossover point where it becomes more efficient than full attention in compute and memory. In theory, that point lies at a few thousand tokens — which isn’t particularly long for today’s large models.
But that’s just theory. We need to solve a few key problems to actually approach it:
Low-Precision State Storage: Linear attention is currently far more sensitive to numerical precision than full attention.
Prefix Caching: In real-world applications, the cache-hit rate for conversations is very high. A new architecture must handle this gracefully.
Speculative Decoding: How do you optimize speculative decoding with linear attention backbone?
Well fortunately, all of these seem solvable.
IV. What’s Next
Scaling remains the name of the game, and context scaling is one of the key problems. Longer and longer context length is key in both pre-training and post-training. As GPU compute growth slows while data length keeps increasing, the benefits of linear and sparse attention will gradually emerge. We should start preparing now:
Better Data: More multimodal, information-rich long-context data.
Better Evaluation: More informative evaluation system and experimental paradigms to speed up iteration.
Better Infrastructure: Mature training and inference infrastructure to fully squeeze out GPU potential.
V. Addendum: the SWA code...
We accidentally left the SWA inference code in the open-source release, and some people asked why it wasn’t used in the final model. Simple answer: the performance wasn't good enough.
That experiment was from quite early on, before GPT-OSS was open-sourced (we were pretty surprised to see its structure, by the way). But I can share a brief summary of our failed attempt. We tried adapting CPT into a Hybrid SWA, testing both inter & intra-layer mixing. The motivation for intra-layer mixing was to balance the compute intensity across all layers, which is friendly to both PP in training and PP or AFD during inference. Unfortunately, neither worked. Performance degraded noticeably as context length grew — which is unacceptable in agentic scenarios.
Our analysis showed that many global attention patterns (like retrieval head and induction head) were already established early during pre-training. CPT can hardly adjust those patterns afterwards. You surely can mitigate the issue by using data probes to identify and keep those heads as full attention — but unfortunately, it’s nearly impossible to discover them all from human priors.
(And no, this issue isn’t related to attention sinks.)
If you're interested in this line of research, I recommend taking a closer look at GPT-OSS, CWM, and Gemma, especially their long-context performance.
Finally, we’re hiring! If you want to join us, send your resume to guixianren@minimaxi.com.
References
MiniMax-01: Scaling Foundation Models with Lightning Attention
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
CWM: An Open-Weights LLM for Research on Code Generation with World Models
Qwen3-Next
Gemma 3 Technical Report
gpt-oss-120b & gpt-oss-20b Model Card
Retrieval Head Mechanistically Explains Long-Context Factuality
transformer-circuits.pub/2022/in-contex…