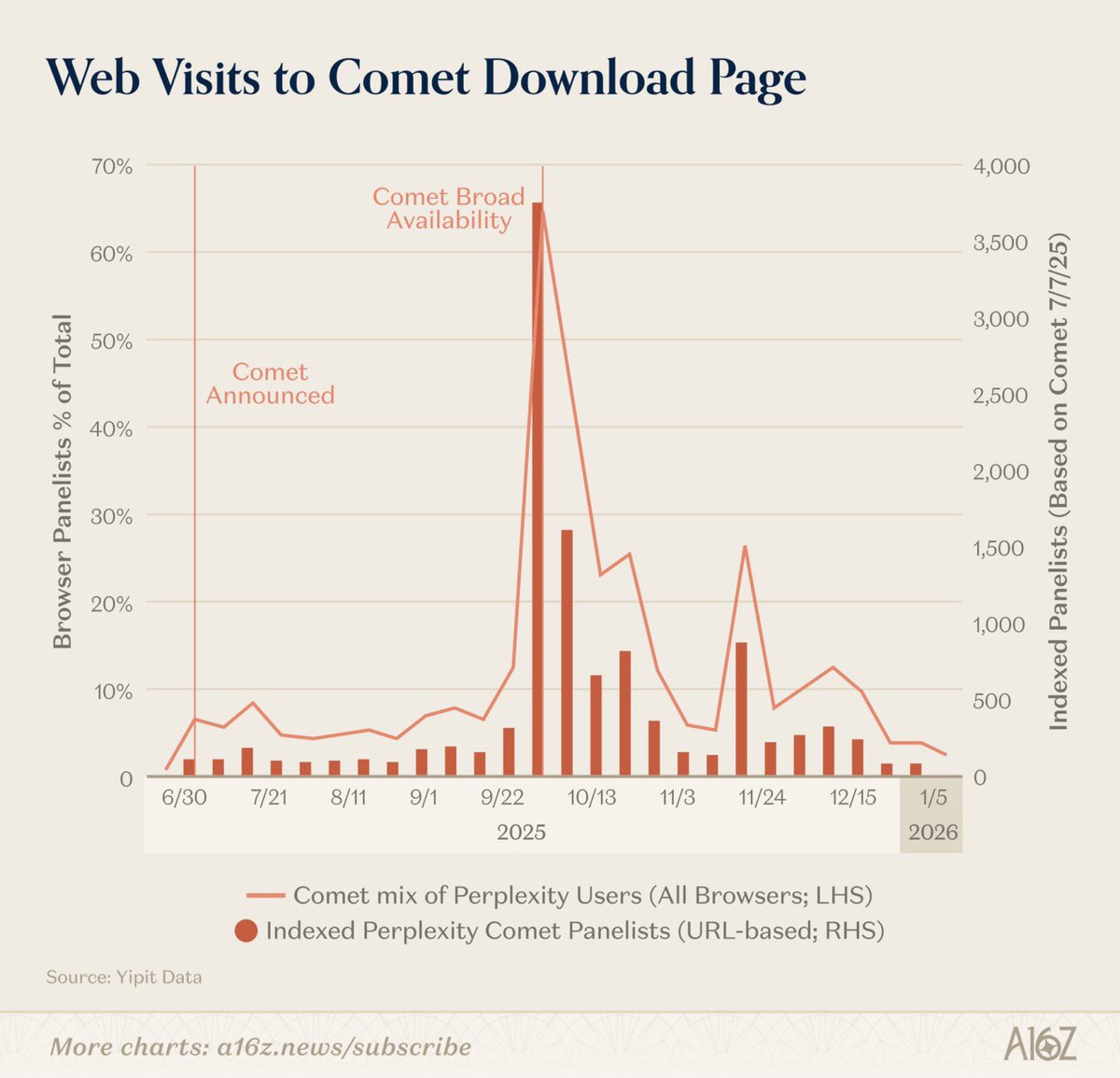
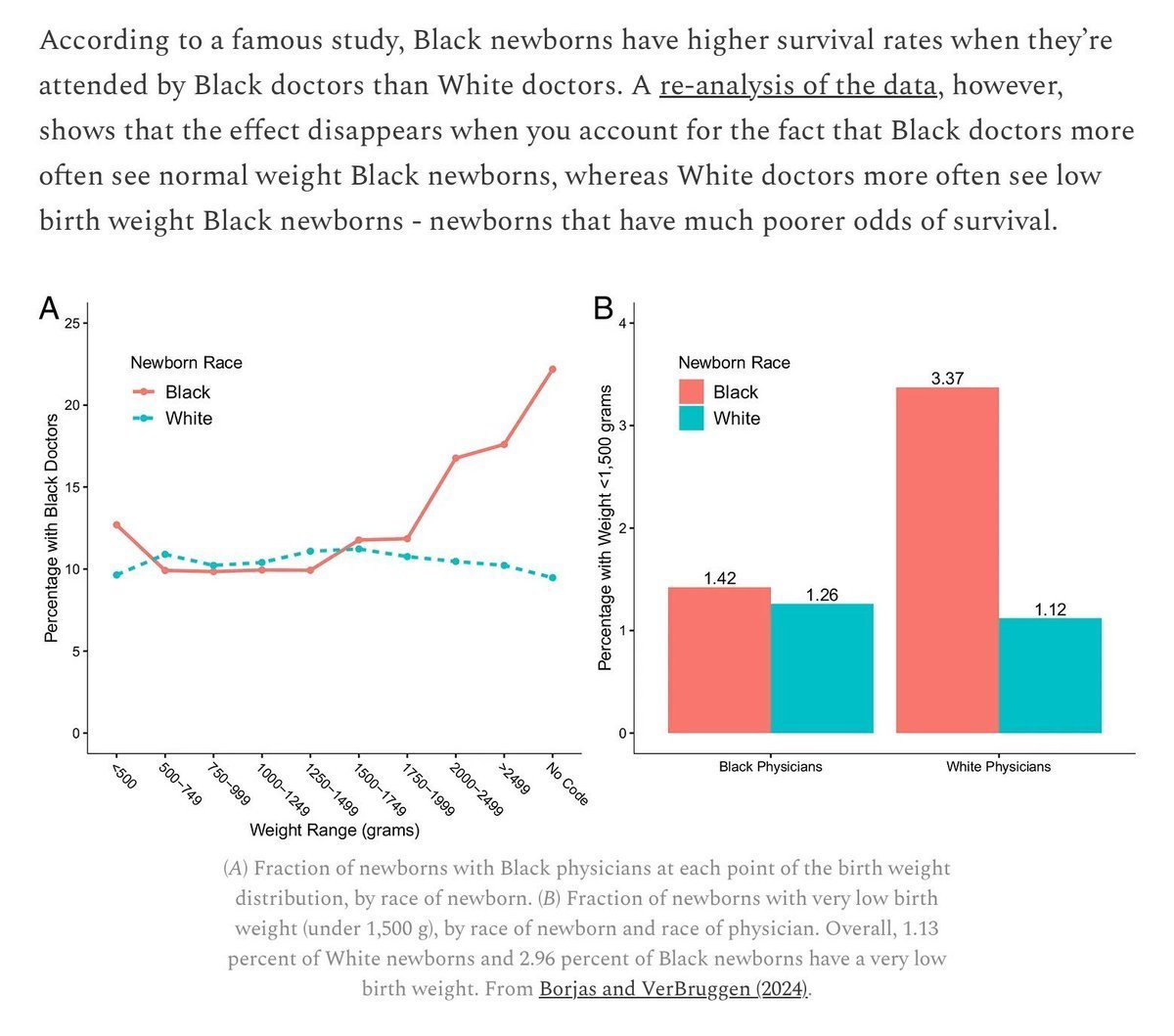
Dave Gilbert@docgotham
I Tried to Make ChatGPT Searchable via Airtable. I Found Architectural Debt.
I ran a simple experiment.
I exported my entire ChatGPT history and uploaded it into Airtable so I could query it from both ChatGPT and @AnthropicAI Claude. I also installed the @airtable app inside ChatGPT to compare the results directly.
For context: I’m not a data engineer. I was using Claude Cowork to help me inspect what was happening inside Airtable and my ChatGPT export files as I went.
I ran the same prompt against the same Airtable base in both systems, under identical conditions.
Claude produced a coherent summary of the material in the base.
ChatGPT’s Airtable app produced something shallow and constrained—and at the time, I couldn’t tell why.
That discrepancy made me look under the hood.
What I found was not just weak retrieval. It was massive API exhaust embedded directly in my archive.
Recent conversational records were filled with: – Raw tool call JSON – Connection IDs – Full API payloads – Schema definitions – Verbose error responses – Even a complete dump of the Airtable MCP API specification
That single interaction contained 2.4 million characters, almost none of it was the actual subject matter. With the help of Claude Cowork, I found dozens of additional records containing raw “/Airtable/link_…” traces. Some were several million characters long.
You might ask: why use Airtable at all? Sure—this could be done with a vector database. I wasn’t trying to build that stack. More importantly, Airtable didn’t create the bloat. Those millions of characters of API exhaust already exist in OpenAI’s persistence layer.
The integration is presentation-first; it renders iframe widgets that are so limited they’re nearly useless—especially when Airtable’s own interface (and its AI assistant, Omni) is far more capable. But beneath that presentation layer, ChatGPT persists the entire request/response cycle as conversation. There’s no clean separation between user intent and tool execution trace.
Three problems: storage bloat. portability failure. memory pollution.
When exports include raw infrastructure logs, cross-conversation memory systems must wade through schema definitions and endpoint documentation just to recover meaning.
This problem, of course, will scale with adoption.
I'm one user with one tool integration. But the architecture suggests a common pattern: tool calls and responses stored as conversation turns. If other connectors in OpenAI's expanding app ecosystem follow a similar approach, the bloat compounds across every integration users adopt.
If the architecture doesn’t separate tool execution traces from conversation content, every tool call inflates storage and every stored conversation costs more to index for memory. Every memory query has to wade through noise to find signal, and every context window burns tokens on infrastructure plumbing instead of user intent.
So yes, this started out as a problem for me, the user. The data quality sucked. But it’s a compounding cost structure problem for @OpenAI and @OpenAIDevs .