
David McLaughlin
143 posts

David McLaughlin
@dsmcl
Director, Global Developer Ecosystem, Google. Developer Relations Programs. Dev Communities and Accelerators.
San Francisco, CA, USA Katılım Mayıs 2008
358 Takip Edilen2.3K Takipçiler

Joining @CrusoeAI to lead product partnerships. The next AI leap isn’t just ‘more GPUs’ — it’s power + cooling + networking + memory + fleet ops that actually run well at scale.
English
David McLaughlin retweetledi

Gemini 3.1 Pro launches today -- and sets a new state-of-the-art mark for a foundation model intelligence.
Try it today across Gemini App, AI Studio, Antigravity, or Vertex!
Artificial Analysis@ArtificialAnlys
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run @GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index and improves significantly over Gemini 3 Pro Preview across capabilities, with the biggest gains in reasoning and knowledge, coding, and hallucination reduction. Gemini 3.1 Pro Preview also remains relatively token efficient, using ~57M tokens to run the Artificial Analysis Intelligence Index (+1M from Gemini 3 Pro Preview), lower than other frontier models at max reasoning settings such as Opus 4.6 (max) and GPT-5.2 (xhigh). Combined with lower per-token pricing, Gemini 3.1 Pro Preview is cost-efficient among frontier peers, costing less than half as much as Opus 4.6 (max) to run the full Intelligence Index, though still nearly 2x the leading open-weights model, GLM-5. Key Takeaways: ➤ State-of-the-art intelligence at lower costs: Gemini 3.1 Pro Preview is leading 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index at less than half the cost to run of frontier peers from @OpenAI and @AnthropicAI. It obtains the highest score in Terminal-Bench Hard (agentic coding), AA-Omniscience (knowledge & hallucination), Humanity’s Last Exam (reasoning & knowledge), GPQA-Diamond (scientific reasoning), SciCode (coding) and CritPt (research-level physics). The CritPt score is particularly notable, scoring 18% on unpublished, research-level physics reasoning problems, over 5 p.p. above the next best model ➤ Improved real-world agentic performance, but not leading: Gemini 3.1 Pro Preview shows an improvement in GDPval-AA, our agentic evaluation focusing on real-world tasks, but is still not the leading model in this area. The model increases its ELO score over 100 points to 1316 (up from Gemini 3 Pro Preview), however still sits behind Claude Sonnet 4.6, Opus 4.6, GPT-5.2 (xhigh), and GLM-5 ➤ Leading coding abilities: Gemini 3.1 Pro Preview leads the Artificial Analysis Coding Index, achieving the highest score in both Terminal-Bench Hard (54%) and SciCode (59%) ➤ Reduced hallucinations: Gemini 3.1 Pro Preview shows a major improvement in tendency to guess incorrectly when it doesn’t know the answer, reducing its AA-Omniscience hallucination rate by 38 p.p. from Gemini 3 Pro Preview ➤ Maintained token and cost efficiency: Gemini 3.1 Pro Preview improves without material increases in cost or token usage. It uses only ~2% more tokens to run the Artificial Analysis Intelligence Index than Gemini 3 Pro Preview, and keeps the same pricing ($2/$12 per 1M input/output tokens for ≤200k context). Its cost to run the Artificial Analysis Intelligence Index of $892 is less than half of frontier models such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open weights models such as GLM 5 ($547) ➤ Google takes top 3 spots in multi-modality: Gemini 3.1 Pro Preview ranks #1 on MMMU-Pro, our multimodal understanding and reasoning benchmark, ahead of Gemini 3 Pro Preview and Gemini 3 Flash, reinforcing Google’s leadership in multimodal reasoning ➤ Other model details: Gemini 3.1 Pro Preview retains the same 1 million token context window as its predecessor, and includes support for tool calling, structured outputs, and JSON mode
English
David McLaughlin retweetledi

Google is now dominating ARC-AGI-2 with Gemini 3 Flash, Gemini 3.1 Pro and Gemini 3 Deep Think (Feb)
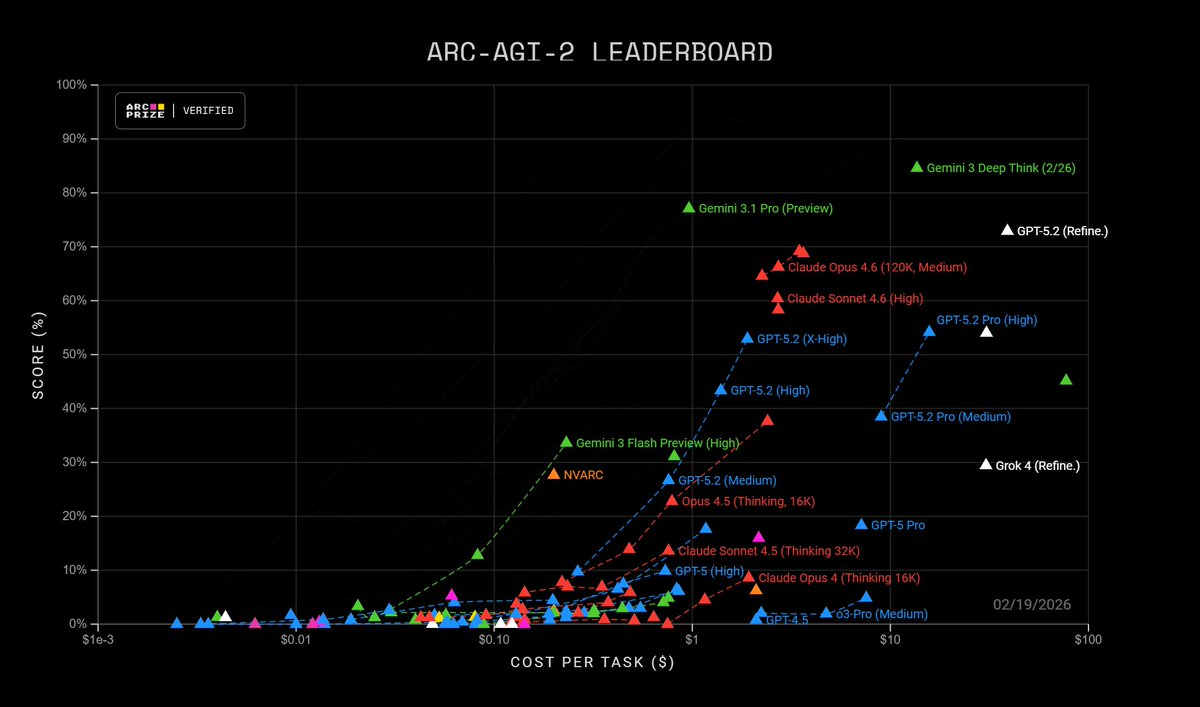
English
English



I spent the last two weeks building apps that I always wished existed. From chord progression designers to screen recorders. I think we are going into an era where every app will be built on demand. Buying software makes sense if it's solving a problem that cannot be generated.
English
@startupandrew @taskletai Go Tasklet! I can't wait to see what y'all have cooking.
English

2026 is gonna be a huge year for @TaskletAI.
OpenAI and Google are in an existential fight for the consumer.
Anthropic is focused on their models and API.
Manus sold out.
But meanwhile we’re laser focused on business adoption.
Greg Brockman@gdb
two big themes of AI in 2026 will be enterprise agent adoption and scientific acceleration
English
I’m not sure why I’ve not been clued into this before but @tailscale is magic. The good kind.
English
David McLaughlin retweetledi

For nearly ten years, the @google Accelerator program has guided and assisted more than 1,700 startups. The results are astounding.
My team (led by @dsmcl) plays a huge part here, and the global impact is worth checking out. Read the report!
blog.google/outreach-initi…
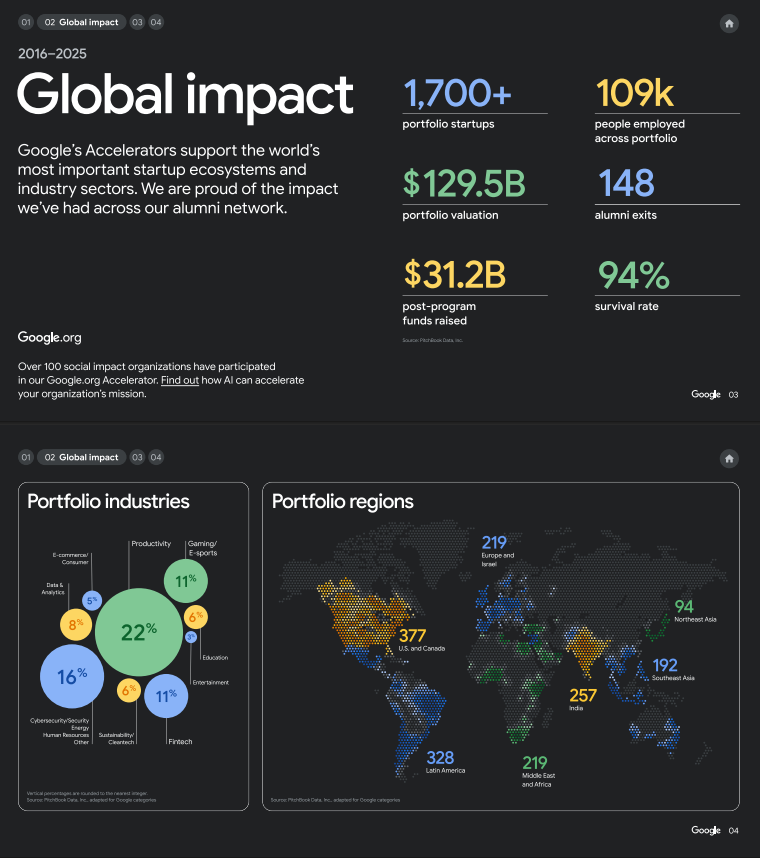
English
@ZviadKardava @cerebral_valley Love it! Looks like a great crowd!
English

Full house at the Google Gemini VibeCode Hackathon here at @cerebral_valley. Developers are locked in and building apps with Gemini. Excited to see what they ship today! 🚀


English
@timothyjordan What a wonderful run you had at Google, Timothy! It's been a lot of fun working across almost every continent with you and building the craft of DevRel at Google. I can't wait to hear reports from your new adventure!
English

My exit from Google: we don't say goodbye, we say good journey. timothyjordan.com/blog/2025/10/2…

English

Today is my last day at Firebase.
4,211 days where I lived the dream: join a small startup, build cool stuff, and grow to insane scale.
All while meeting the greatest people.
It's been amazing and I'm excited for what's next.

English
David McLaughlin retweetledi

On this day in 1959, Dave Brubeck Quartet released the single “Take Five”
English
@ZviadKardava Yeah I agree. I’ve seen a bunch of those too. Point release incoming I hope.
English
@dsmcl Random things – window focus doesn't move to a window you click on. App wouldn't close when clicking on X. File wouldn't get selected. Custom shortcuts randomly don't work. Can't resize or move windows with hotkeys. Window resizing. Had to force quite few apps. And so on...
English
I made the mistake of updating to a MacOS 26 Tahoe and it is unusable. It is bad. And I'm not talking about the looks and style but bugs & issues
Zviad ზვიად 🇬🇪 | 🇺🇦@ZviadKardava
What is the easiest way to rollback the MacOS version? Asking for a friend...
English
Excited for the Dev Ecosystem India team for a record-breaking Agentic AI Day! We hosted the largest ever AI Agent hackathon in Bangalore, and officially secured a GUINNESS WORLD RECORDS title. Over 2,000 developers built amazing MVPs in 700 AI-first teams. Congrats!

English
Closing up my Berlin tour with two talks at the GDE summit! 🎤
- @Firebase Studio: Past, Present, and Future
- @Firebase AMA.
Huge thanks to Rosario Fernandez and @twerske for the partnership on stage, to @SeraAndroid and @dsmcl for the invitation, and to all our GDE community for the support.


English
@sgnagnarella @Firebase @twerske @SeraAndroid Thank you for engaging so passionately with all the developers!
English

This view never gets old. (From our office in Shibuya, Tokyo)

English
Passkeys continue to improve their UX. Liking that major players are working together to enable import/export. People should own their credentials for passkeys to be truly universal.
English