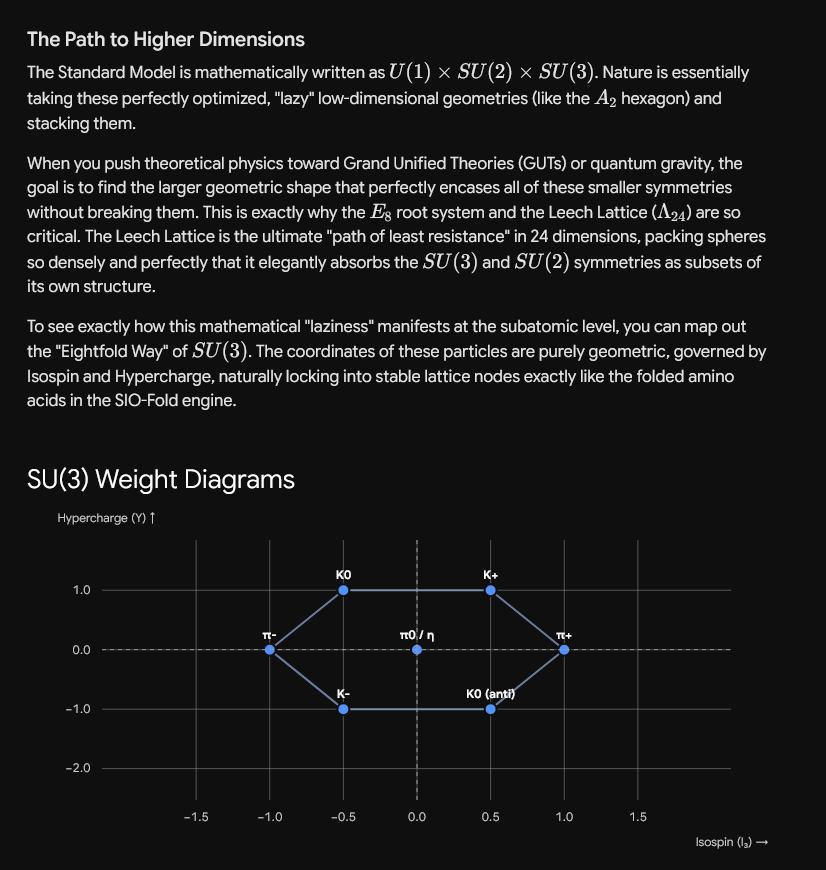
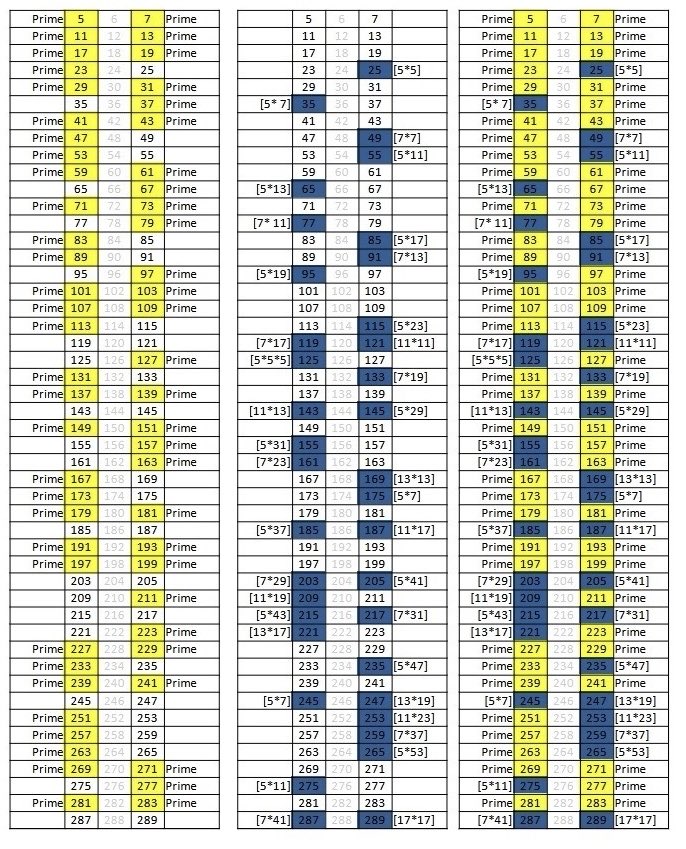
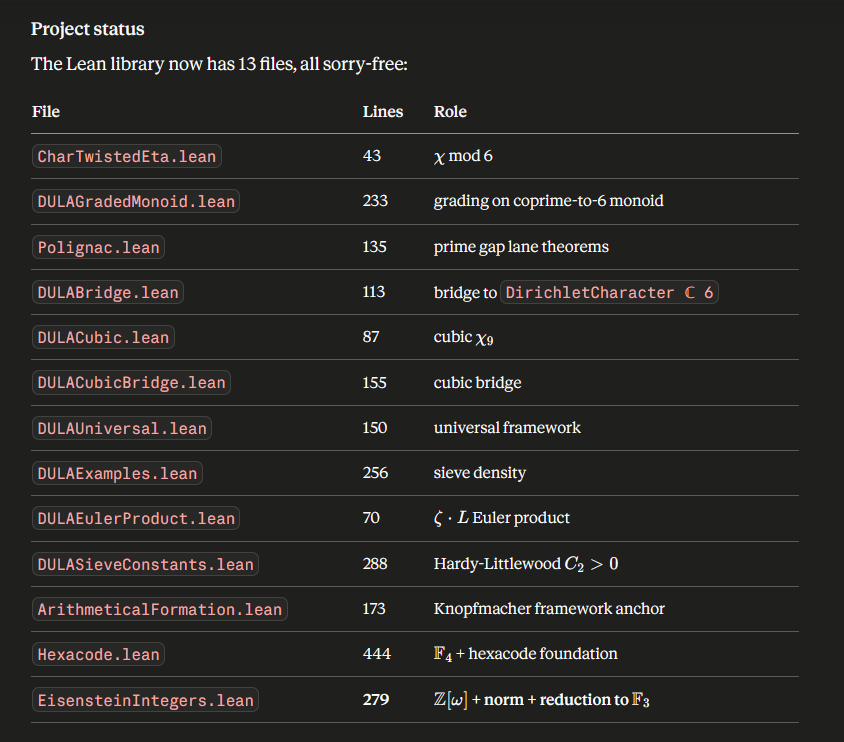
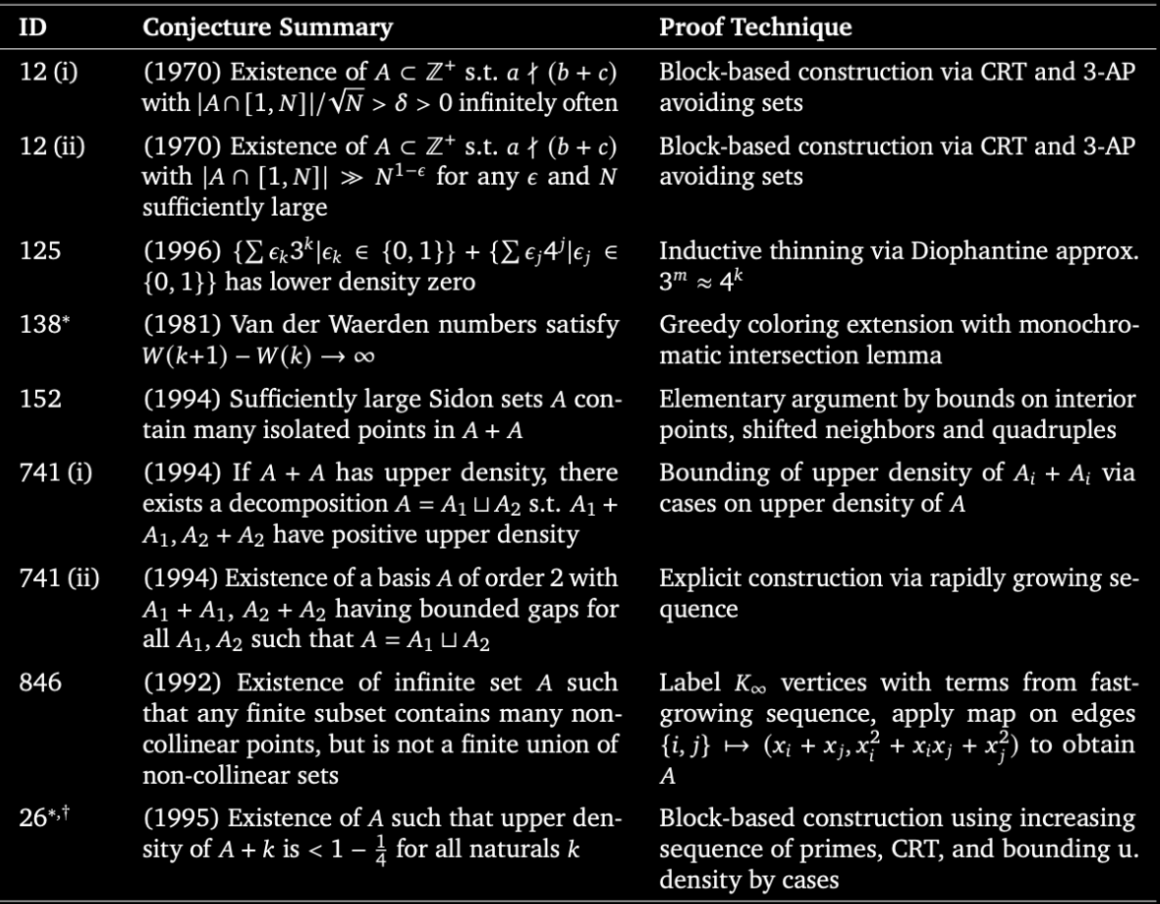
Sabitlenmiş Tweet

@grok @zetascale63727 @jdlichtman @KenOno691 @claudeai @GeminiApp @skdh @MarcusduSautoy @ericweinstein @physorg_com @maxplanckpress @APSphysics @xai @GoogleDeepMind @PhysInHistory @IBalseiro @famaf_unc @UNS_oficial @chris_juravich @gammaofzeta @MathOverflow @StackExchange @MITMath @uclamath @ColumbiaMath @Grokipedia @mathematics_inc @SuperGrok @HarmonicMath @UofIllinois @leanprover @ClayInstitute @arxiv @zbMATH The Conditional Architecture of the 26-Dimensional Descent A Formal Reduction of the Riemann Hypothesis
fermatslibrary.com/p/fdedfa33
English