
@GorinGennady Reminds me of one of my favorite recent single-cell tech papers from @AdamCribbs -
check out Fig 1 - nature.com/articles/s4200…
English
David McKellar
418 posts

@dwmckellar
building tech for RNA @ Romix Bio former @NYGCtech | @CornellBME | @NHGRI postbac

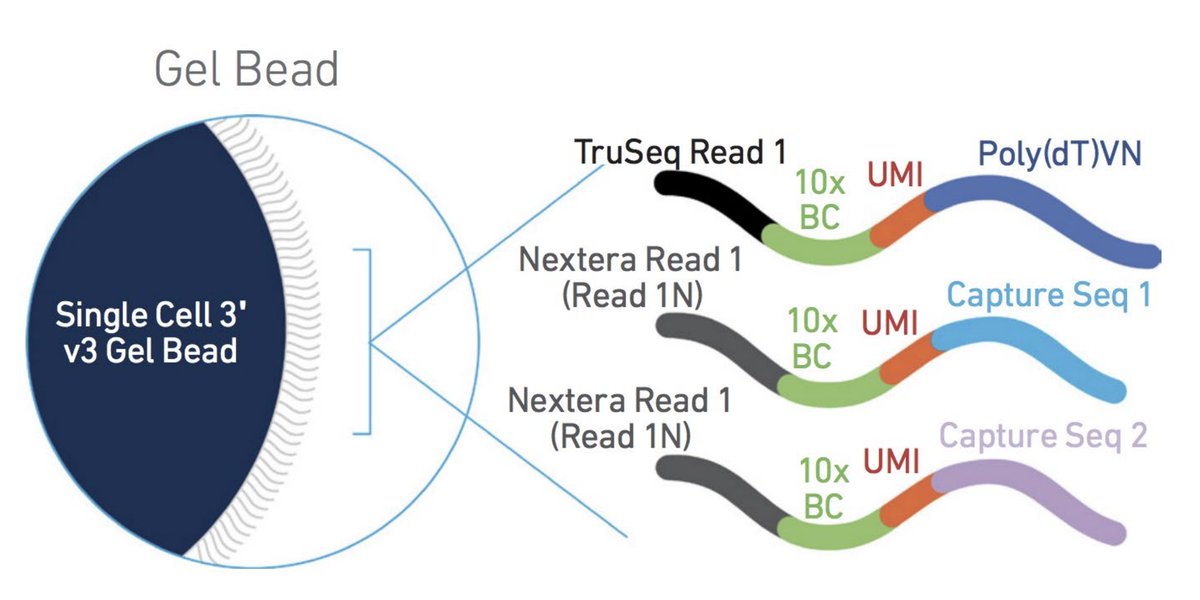

Empty drops in scRNA-seq uncover the surprising prevalence of sequestered neuropeptide mRNA and pervasive sequencing artifacts biorxiv.org/content/10.648… #biorxiv_bioinfo







A mechanical engineering alumnus has bestowed Georgia Tech with the largest single gift in the history of the Institute — $100 million. The late John Durstine graduated from Tech in 1957 and built a 32-year career at @Ford. His generosity will shape generations of students to come. He will — forever and always — be a Yellow Jacket. 🐝 #WeCanDoThat #TransformingTomorrow | c.gatech.edu/durstine







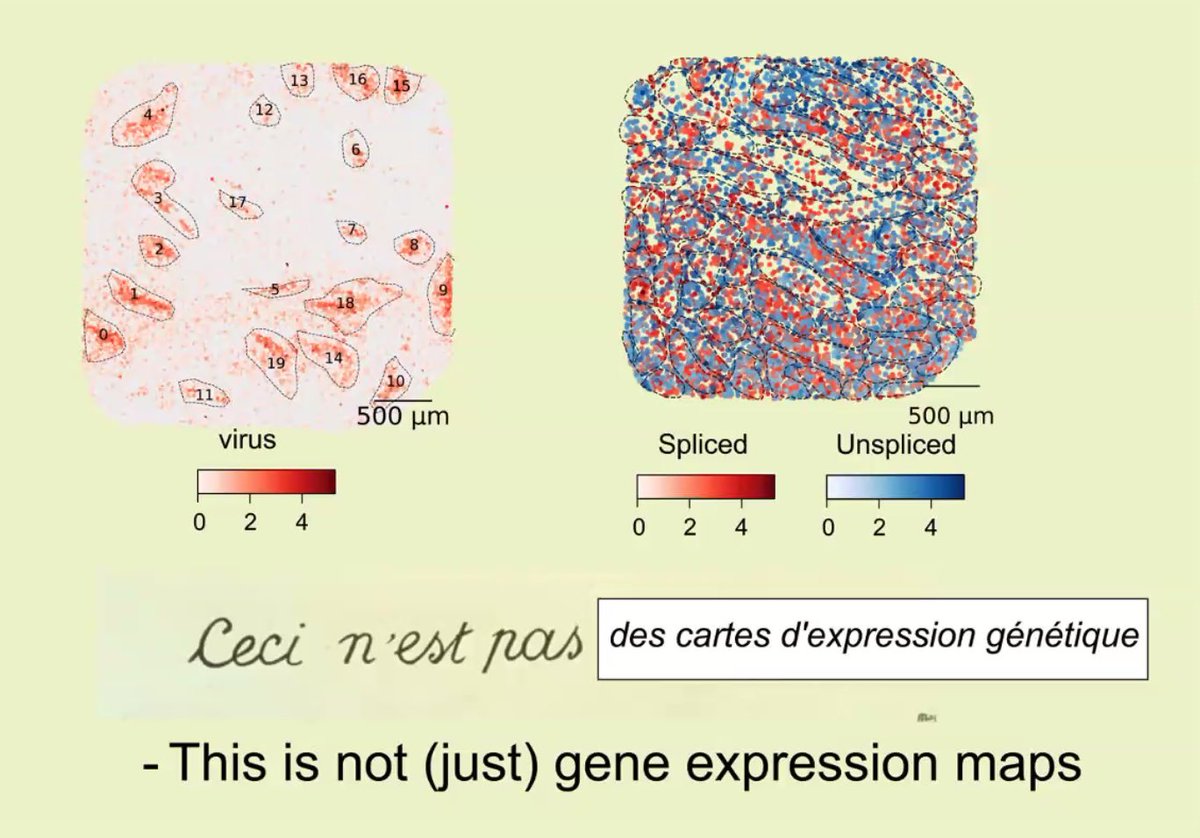
We also found a set of systematically low quality spots in the Visium platform, and provide evidence that this likely stems from the underlying synthetic barcodes that lead to downstream PCR biases.
Very excited to announce the first **RNA x Tech Dev Mini-Symposium** in collab with @Tri_I_RNA! Talks from @mason_lab, @IGainetdinov, @wu_xuebing, and @mssanjavickovic. Come down to @nygenome and hear about the latest in RNA technology development being done in NYC!

Unpaired socks. Should I just throw everything out and start again?
