Sabitlenmiş Tweet

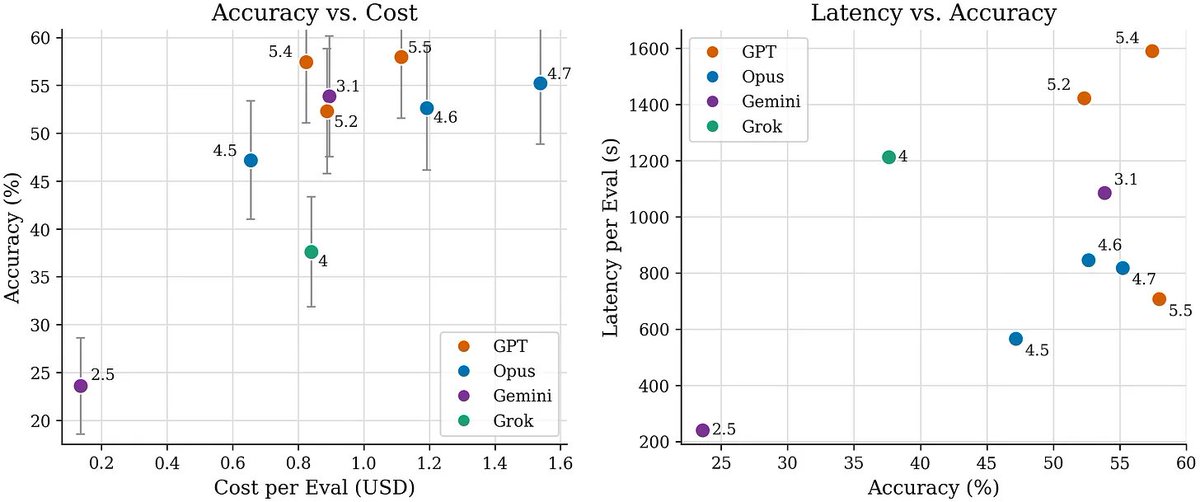
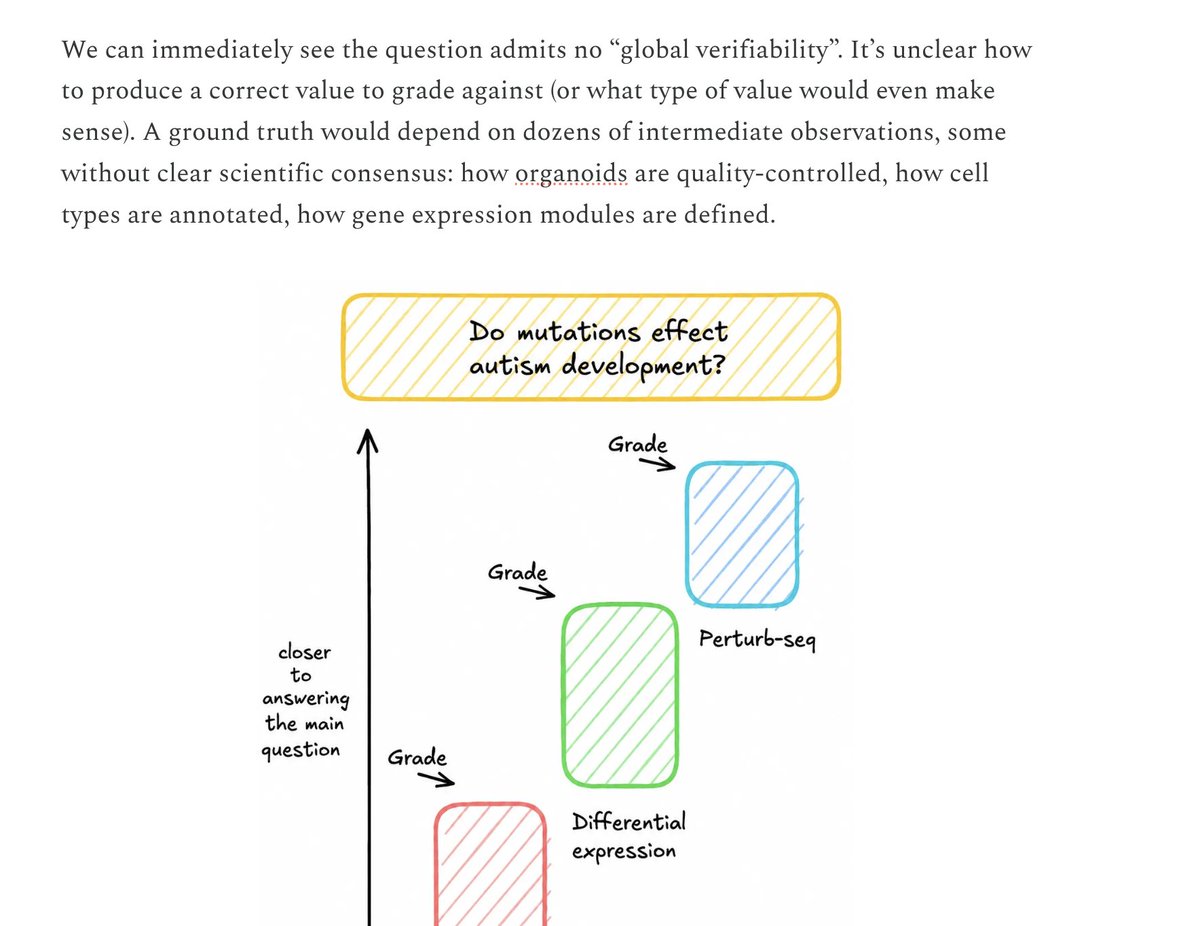
Gave a talk to Machine Learning @ Berkeley on benchmarking frontier models on spatial biology.
Why understanding how assays work is important, what verifiability might look like with messy biology + infrastructure challenges running agentic evals at scale.
English