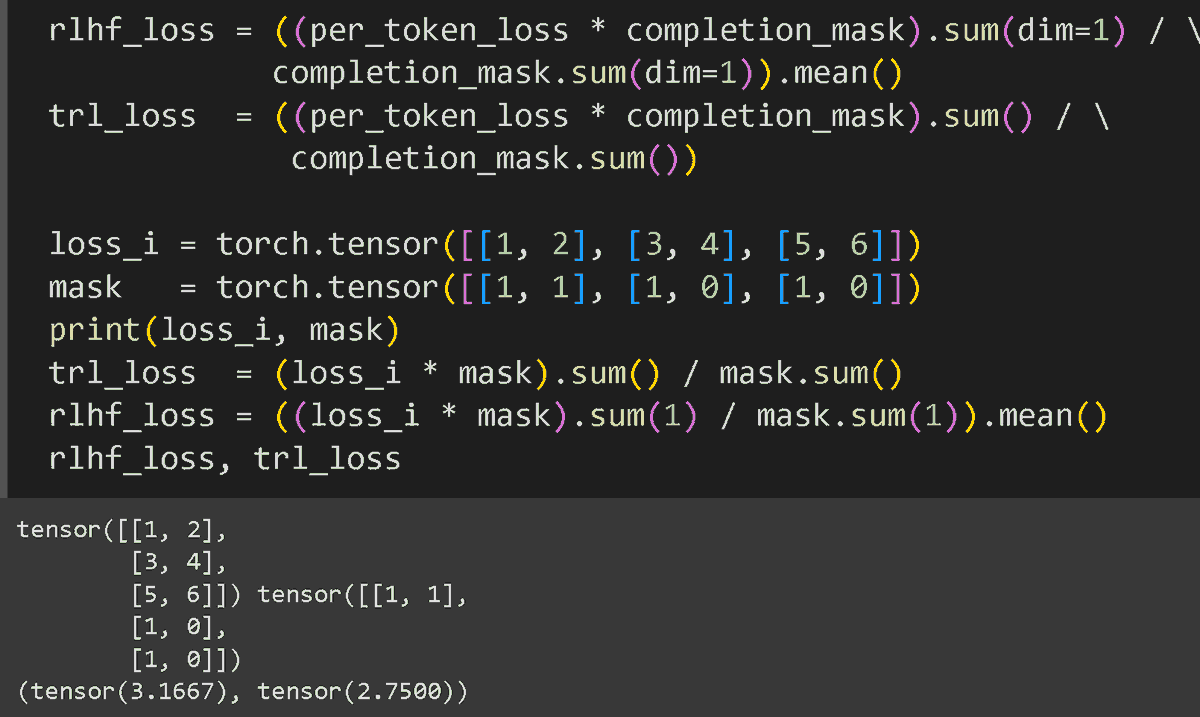
This opens up more flexible and powerful student-teacher pairings. You can now pick the best teacher and best student for the job, without worrying if their tokenizers match. You can read the full technical write-up and find the open-source code here: huggingface.co/spaces/Hugging…
English