Sabitlenmiş Tweet
eisneim
955 posts


eisneim
@eisneim
Gen AI | Web developer | videographer 视频大拍档特里
Shenzhen, China Katılım Nisan 2017
327 Takip Edilen318 Takipçiler
eisneim retweetledi

Another test with the LTX 2.3 vid2vid lip sync workflow. I've been finding the inpainting mode works more reliably overall, so I'd actually recommend turning it on even for close-ups.
English
eisneim retweetledi

Yet another amazing-lookingIC lora for LTX 2.3 lands on the scene.
Its v2v and text prompted. Does editing, removal, replacement and restyle.
Personally, I would REALLY like to know if it can handle a first frame as a reference. I'm guessing now though.
civitai.red/models/2553102…
English
eisneim retweetledi

eisneim retweetledi

eisneim retweetledi



github.com/eisneim/LTX-2_…
i created a new Repo for faster and better image to video generation using LTX 2.3 with triple stage sampling
English
github.com/GAIR-NLP/daVin…
new video model: 15B-parameter, 40-layer Transformer that jointly processes text, video, and audio via self-attention only. No cross-attention, no multi-stream complexity. Achieves 80.0% win rate vs Ovi 1.1 and 60.9% vs LTX 2.3
English
eisneim retweetledi

1/2 Qwen3.5 is here. The next frontier of Native Multimodal Agents is open. 🚀
We are thrilled to release Qwen3.5-397B-A17B, our flagship open-weight vision-language model. Built for the future of coding, reasoning, and seamless multimodal interaction.
Key Highlights:
Inference Efficiency: A massive 397B total parameters, but only 17B active—delivering flagship power at a fraction of the cost.
Hybrid Architecture: Innovative Gated Delta Networks (Linear Attention) + Sparse MoE for extreme speed.
True Multimodality: Exceptional performance across GUI interaction, video comprehension, and agentic workflows.
Global Scale: Qwen3.5 now supports over 200 languages.
Empowering developers and enterprises to build smarter, faster, and more versatile AI agents.
English
eisneim retweetledi

OpenCode + MLX + Qwen3.5-397B-A17B-4bit.
Video is 8x, but the goal is showing that It works!
This is something unimaginable just few months ago.
MLX Team is pushing like crazy and M5 Ultra will do the rest 🚀
English
eisneim retweetledi

Capybara? 14B model for T2V, T2I, TV2V, TI2I.
- based on HunyuanVideo1.5;
- byt5-small, Glyph-SDXL-v2, SigLIP;
- 480p-1080p; 16.7GB model, 5GB VAE..
mostly for video editing.
huggingface.co/xgen-universe/…
English
eisneim retweetledi

BitDance:字节大年初一开源的AI绘画模型
最大的亮点是速度快,使用高压缩视觉分词器,将图像映射为紧凑的二值Token序列,并且每一步扩散过程并行预测64个Token。所以即使模型大小有14B,生成图片的速度也非常快。
模型:huggingface.co/collections/sh…
Github:github.com/shallowdream20…

中文
eisneim retweetledi
Self-Refining Video Sampling: inference-time method using a video generator as its own refiner to correct physics and motion.
no retraining needed; scores >70% human preference; is validated on Wan2.2 & Cosmos.
agwmon.github.io/self-refine-vi…
English
eisneim retweetledi

eisneim retweetledi

Qwen just dropped Qwen3-TTS on Hugging Face
Voice cloning from 3s of audio, 10-language support, and 97ms streaming latency for ultra-realistic speech generation

English
eisneim retweetledi

Scaling scientific world models requires co-designing architectures, training objectives, and numerics. Today, we share the first posts in our series on low-precision pretraining, starting with NVIDIA's NVFP4 recipe for stable 4-bit training.
Part 1: radicalnumerics.ai/blog/nvfp4-par…
Part 2: radicalnumerics.ai/blog/nvfp4-par…
We cover floating point fundamentals, heuristics, custom CUDA kernels, and stabilization techniques. Future entries will cover custom recipes and results on hybrid architectures.
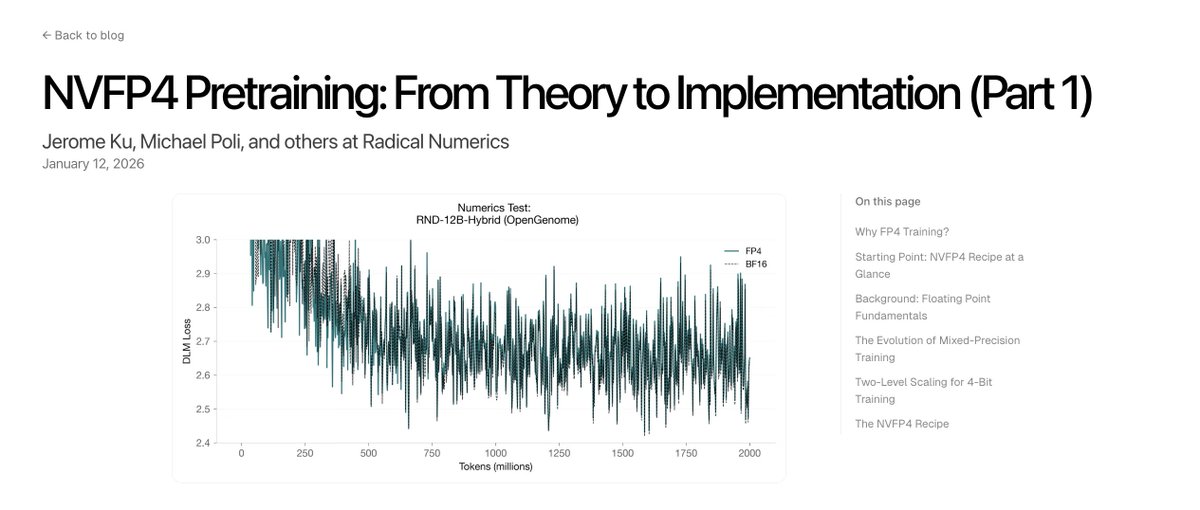
English
eisneim retweetledi
eisneim retweetledi





eisneim retweetledi
Again Wan. Reward Forcing: Real-time streaming video gen, 23 FPS w/ interactive control;
- infinite generation;
- built on Wan2.1-T2V-1.3B
reward-forcing.github.io
English
eisneim retweetledi

💡HunyuanVideo1.5 Update: We are now releasing the 480p I2V step-distilled model, which generates videos in 8 or 12 steps (recommended)! On RTX 4090, end-to-end generation time is reduced by 75%, and a single RTX 4090 can generate videos within 75 seconds. The step-distilled model maintains comparable quality to the original model while achieving significant speedup. For even faster generation, you can also try 4 steps (faster speed with slightly reduced quality).
🔗Check out the GitHub Repo: github.com/Tencent-Hunyua…
English
eisneim retweetledi
