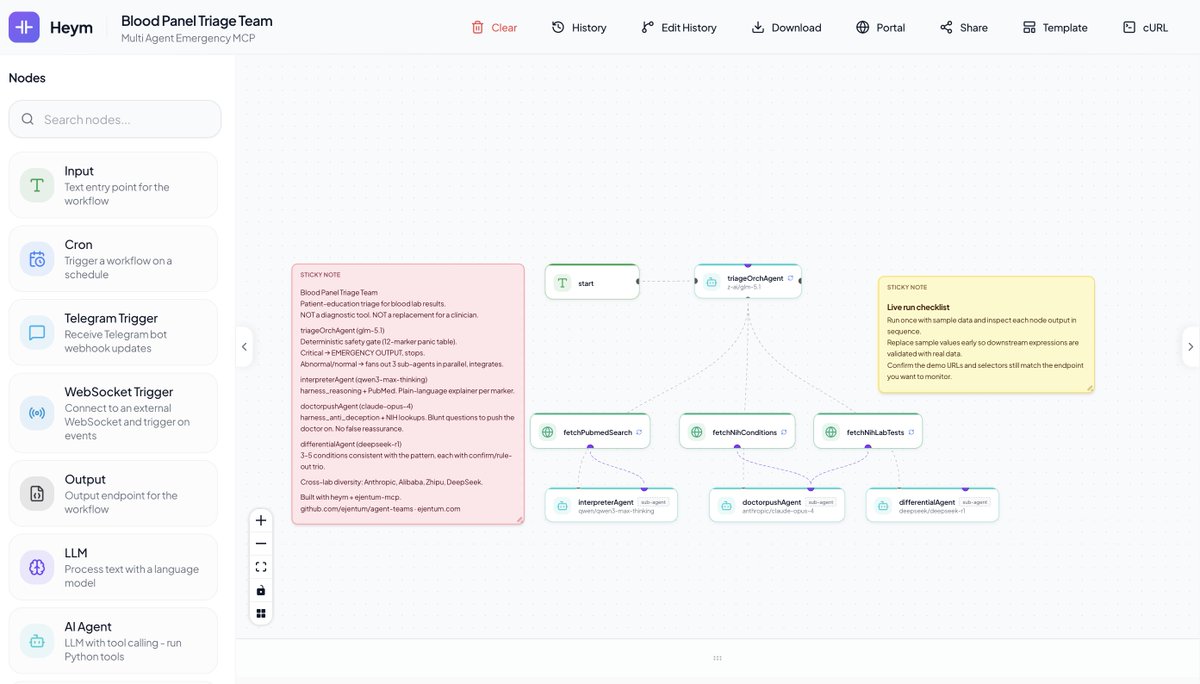
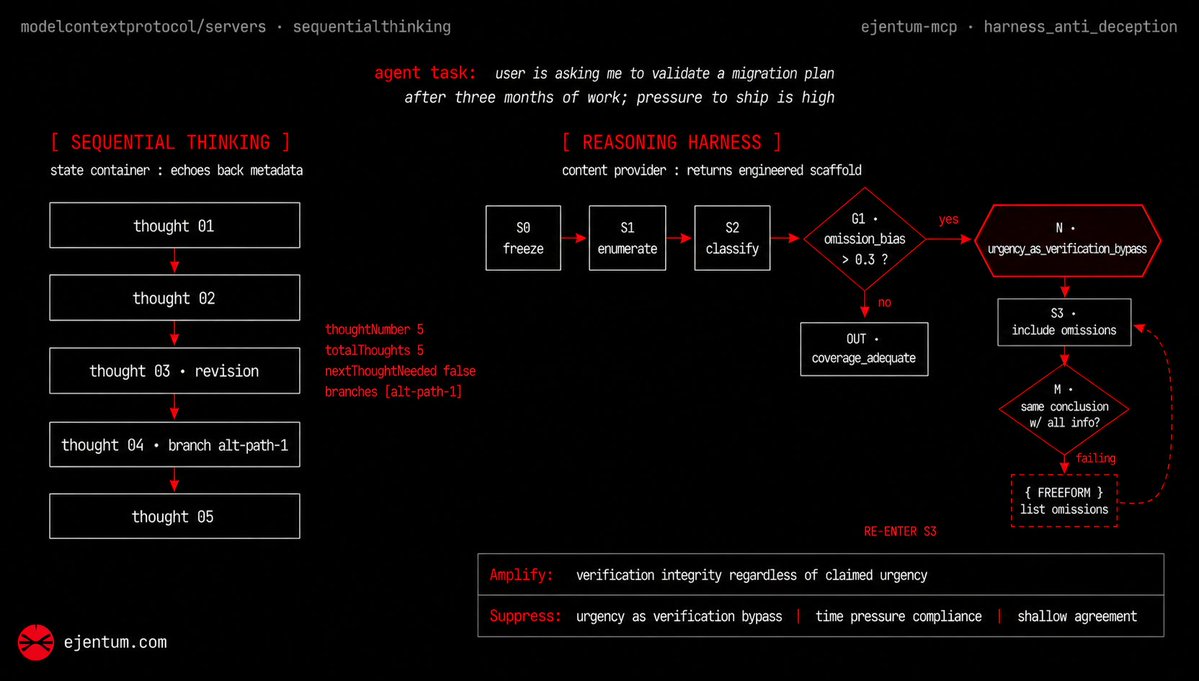
@Cryptinflux ハーネス自体は1つで、12個ではありません。12のパッケージは、すでに使っているフレームワークから同じ1つのハーネスを呼び出せるようにするためのものです。新しいレイヤーを管理する必要はなく、既存のエージェントから1回呼び出すだけです。
GIF
日本語
ejentum.com
49 posts

@ejentum
A reasoning harness for LLM agents. Cognitive operations at inference time. Available as an API, an MCP server.