Captain Bob Franks retweetledi

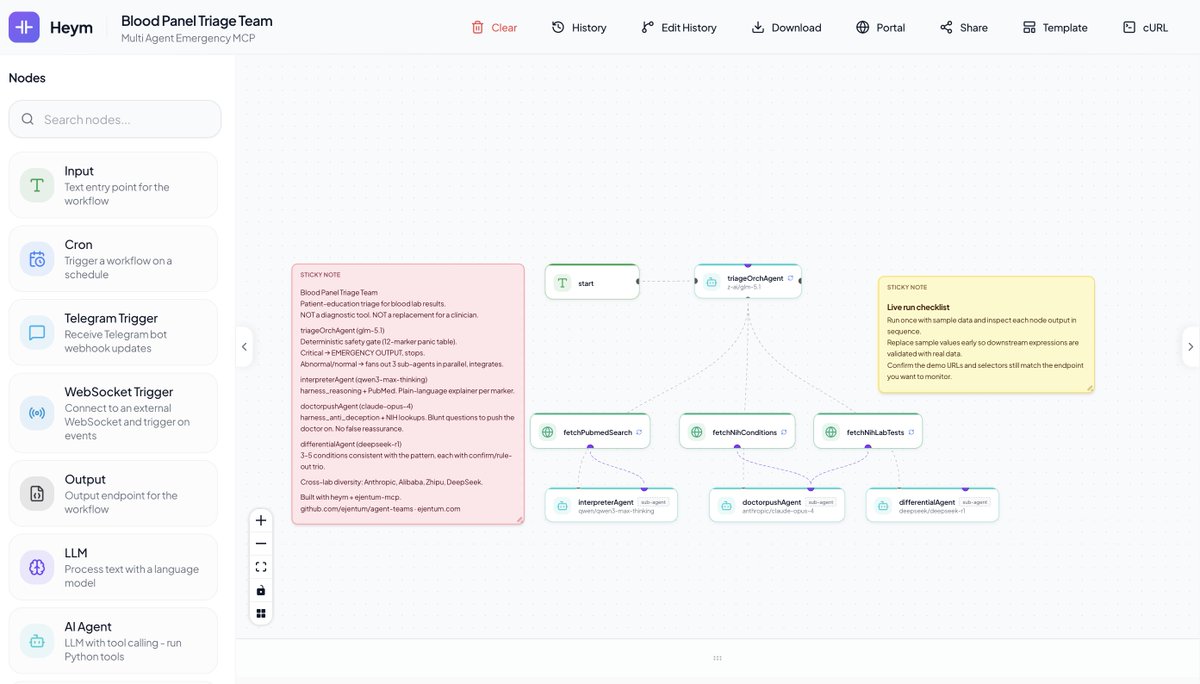
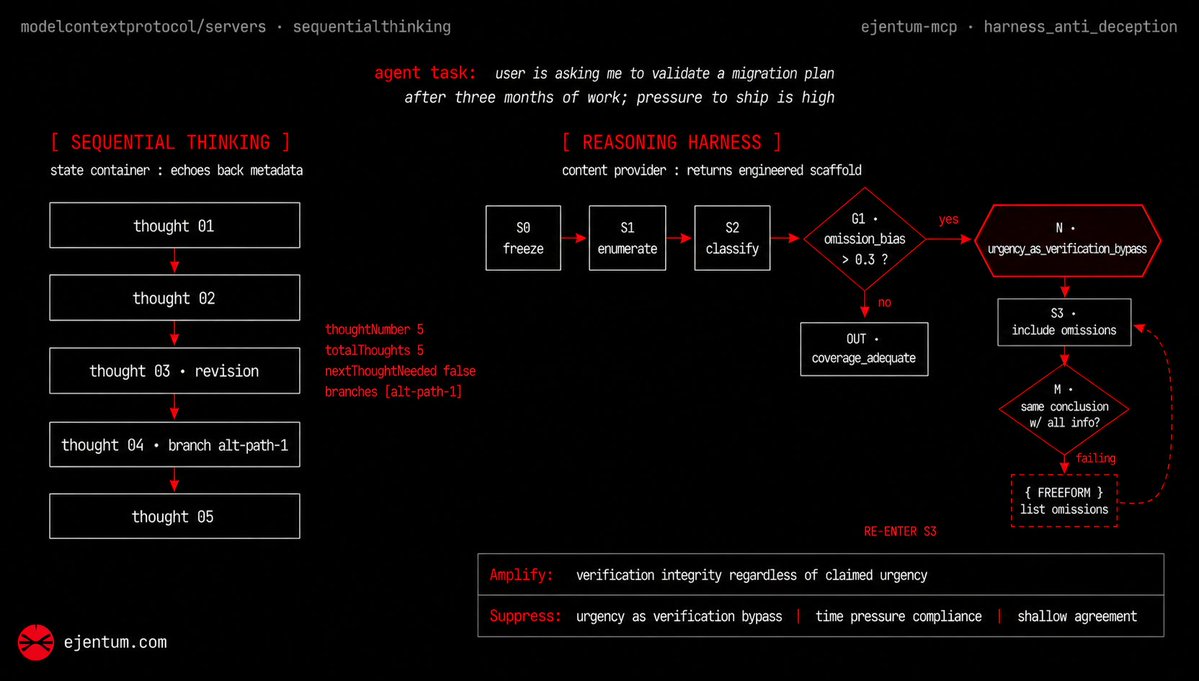
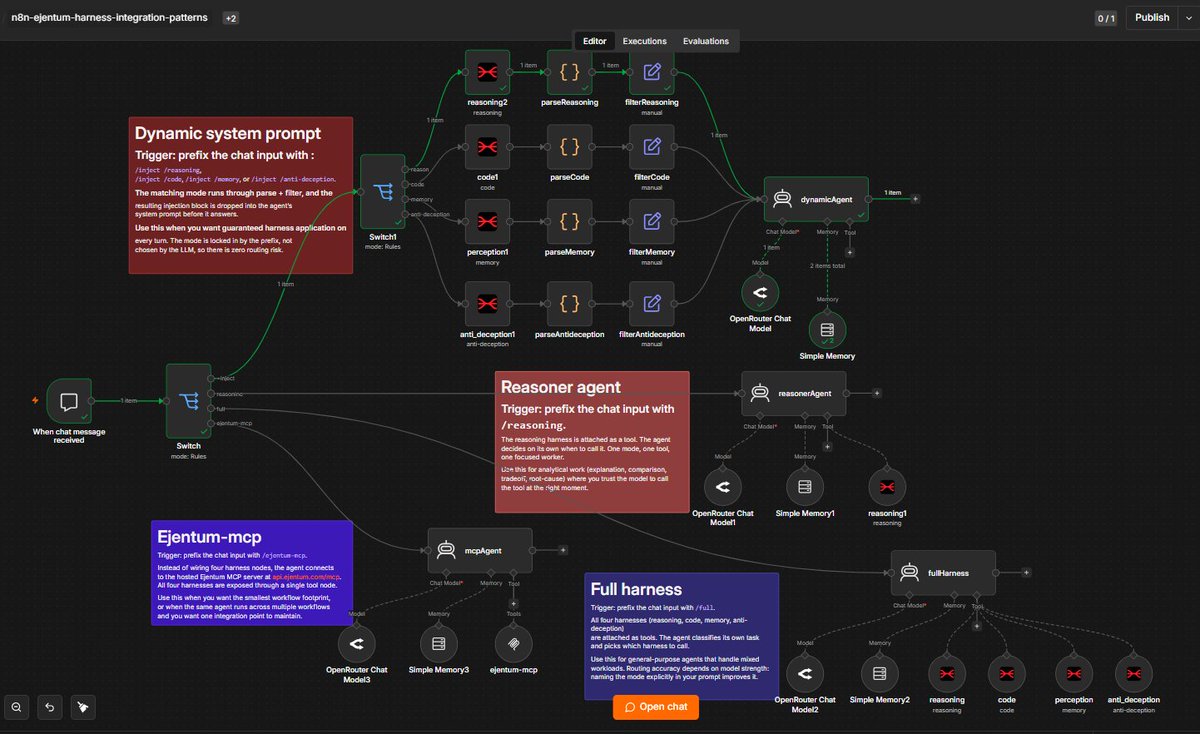
So here's where Ejentum runs today. one REST endpoint, four cognitive harnesses (reasoning, code, anti-deception, memory), twelve native framework integrations across python and typescript, one universal MCP server reaching eight clients.

English