Elad Segal retweetledi

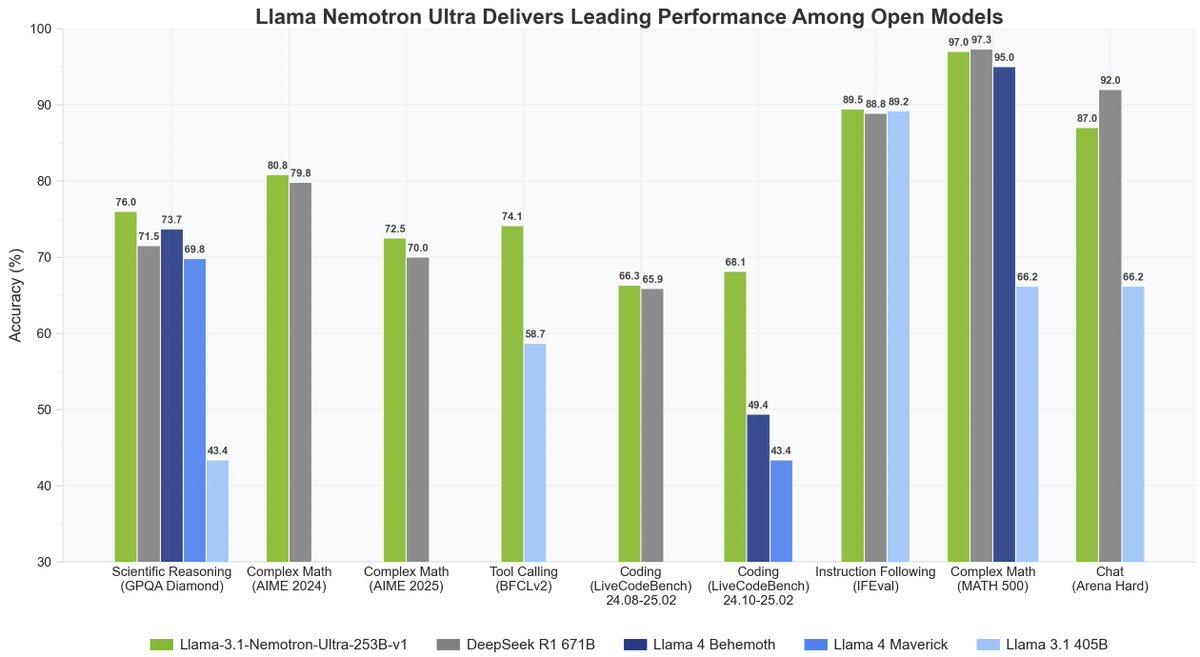
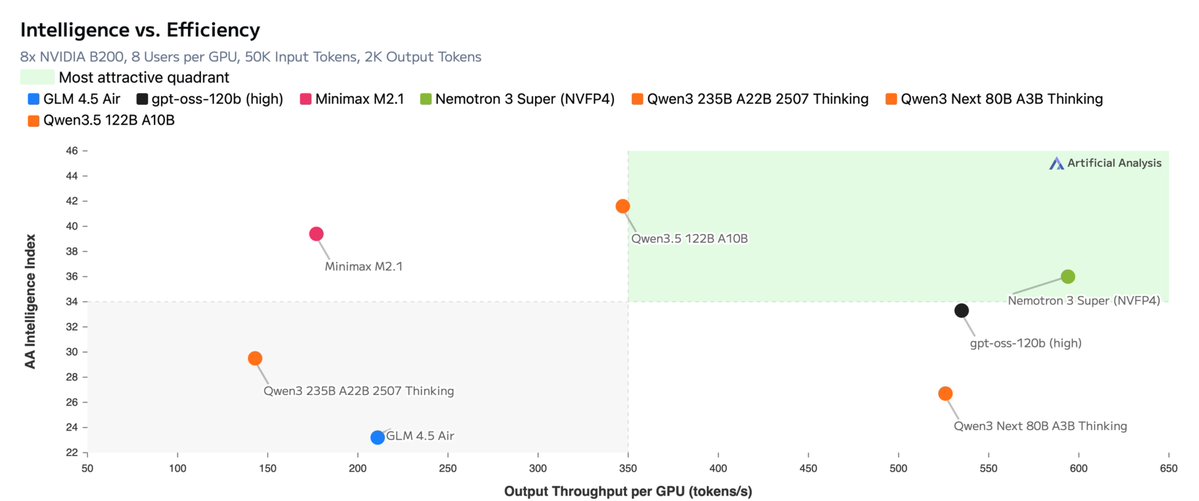
Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell
💚36 on AAIndex v4
💚up to 2.2X faster than GPT-OSS-120B in FP4
💚Open data, open recipe, open weights
Models, Tech report, etc. here:
research.nvidia.com/labs/nemotron/…
And yes, Ultra is coming!
English