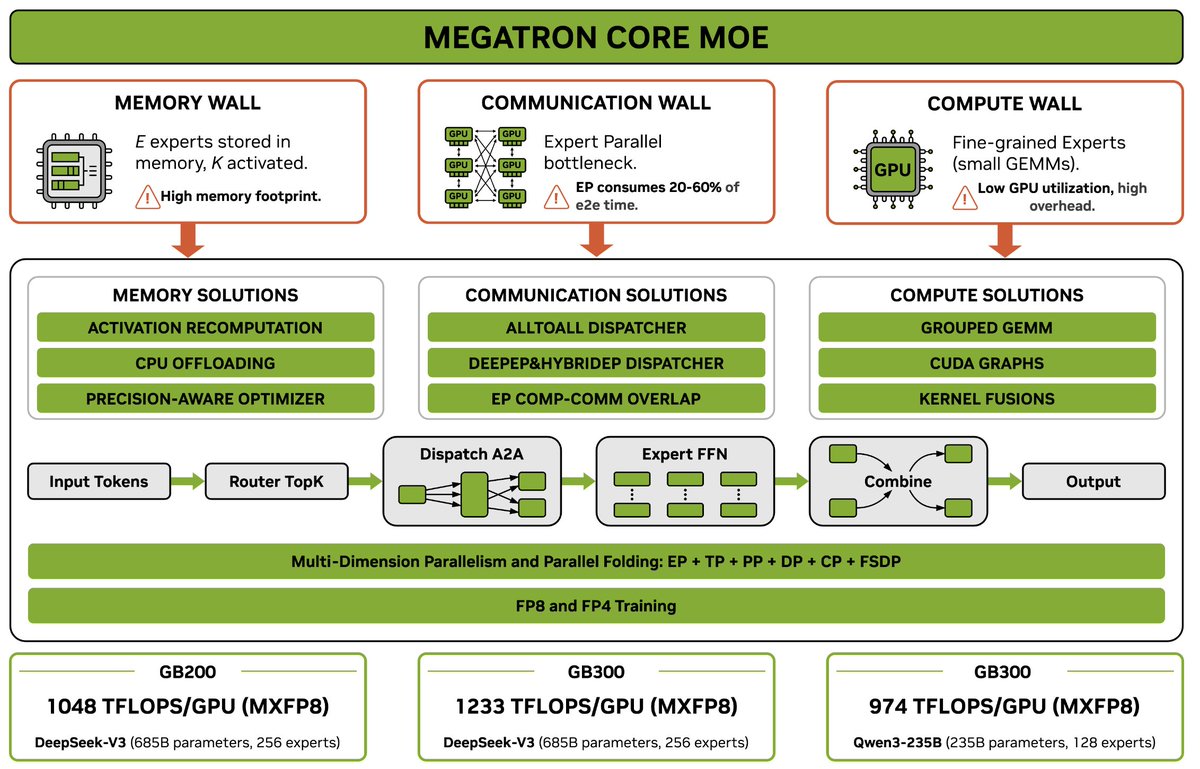
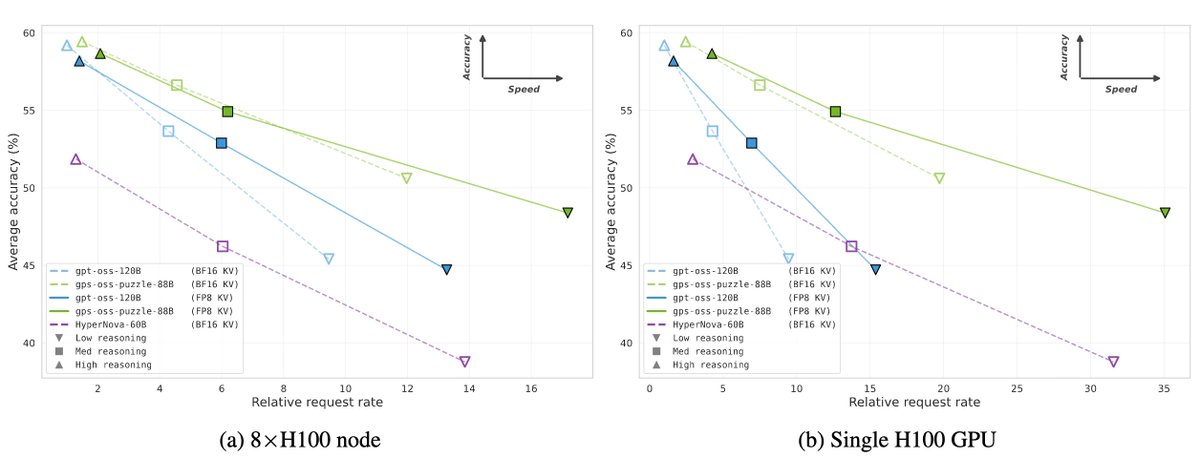
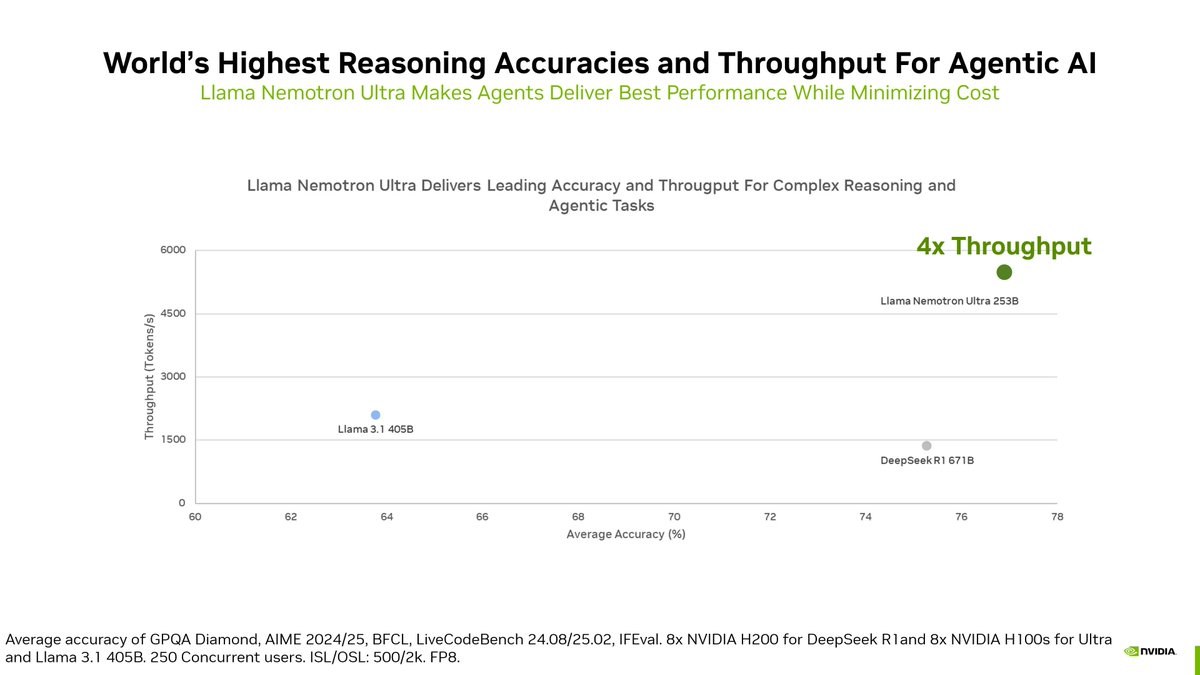
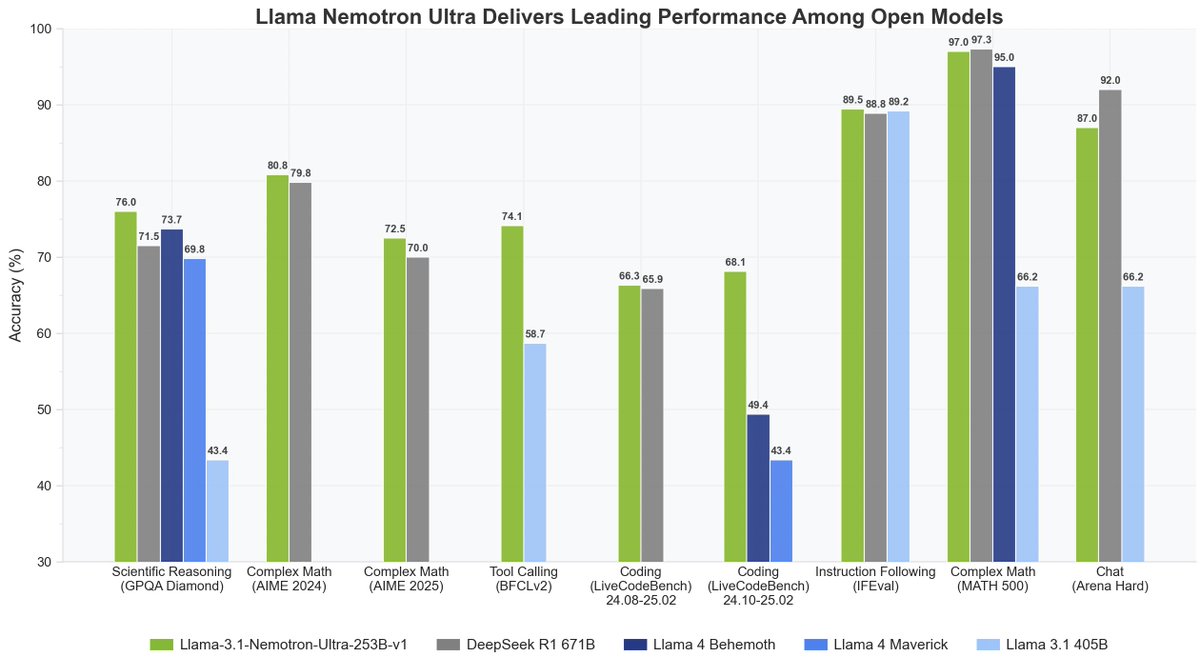
Itay Levy retweetledi

Nemotron 3 Super is live! So far the most intelligent agentic reasoning model in the Nemotron family, with world leading efficiency and openness.
Super particularly marks our first infra & research milestone in agentic reinforcement learning scaling up.
Stay tuned for more infra, data and agentic generalization research we will open to the ecosystem.
🤗 Huggingface: lnkd.in/gWfamwwX
📜 Tech Report: lnkd.in/gRFFJxKm
🤸♂️NeMo-Gym (RL env data and orchestration): github.com/NVIDIA-NeMo/Gym
🤸NeMo-RL (RL training): github.com/NVIDIA-NeMo/RL

English