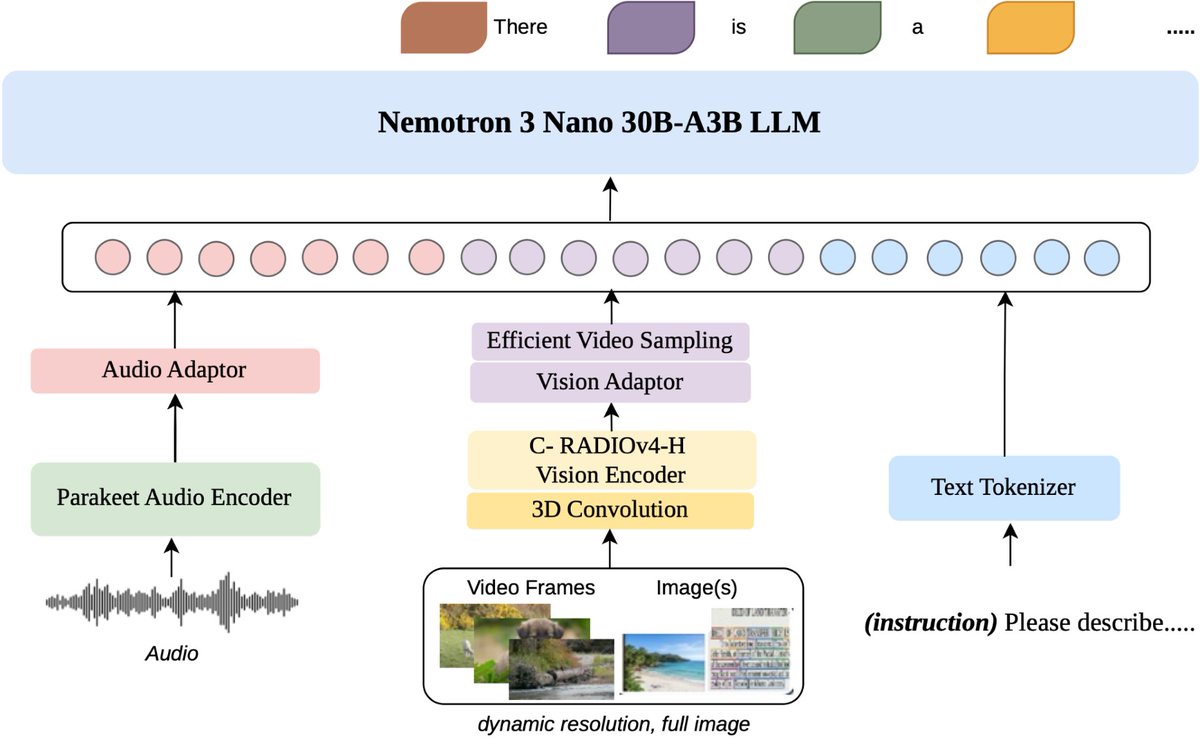
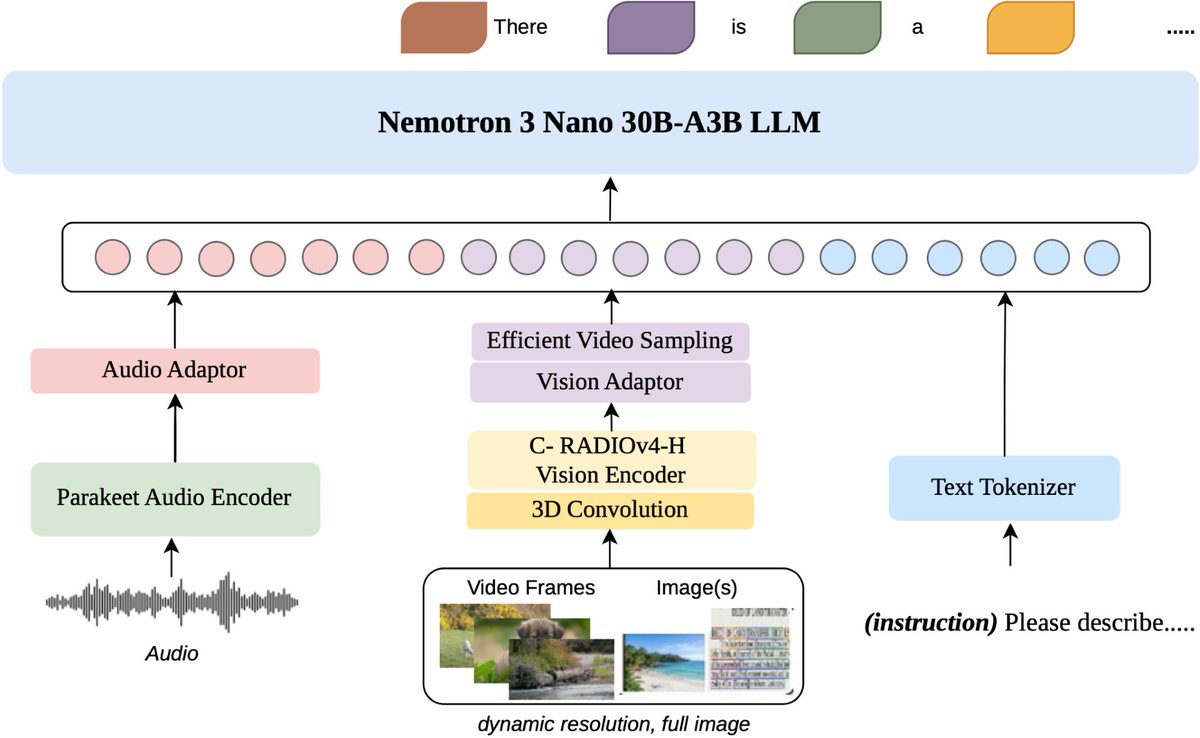
Sabitlenmiş Tweet

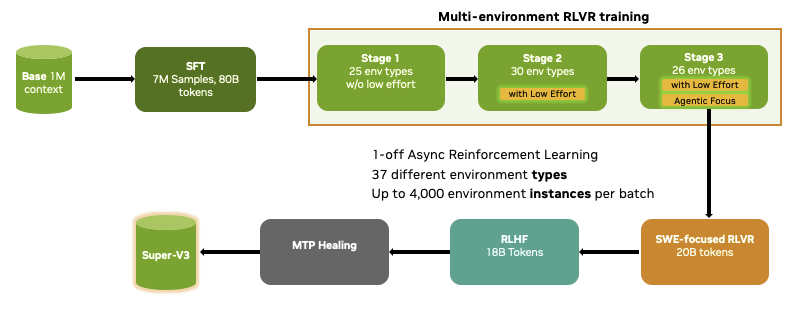
1/4 We see no wall in post-training. Scaling RL software, infra, and data keeps yielding major capability gains.
We trained across 30 RL environments with up to 4,000 instances per batch — math, code, STEM, agentic tool use, SWE, terminal, safety — all in a unified multi-environment RLVR setup.
English