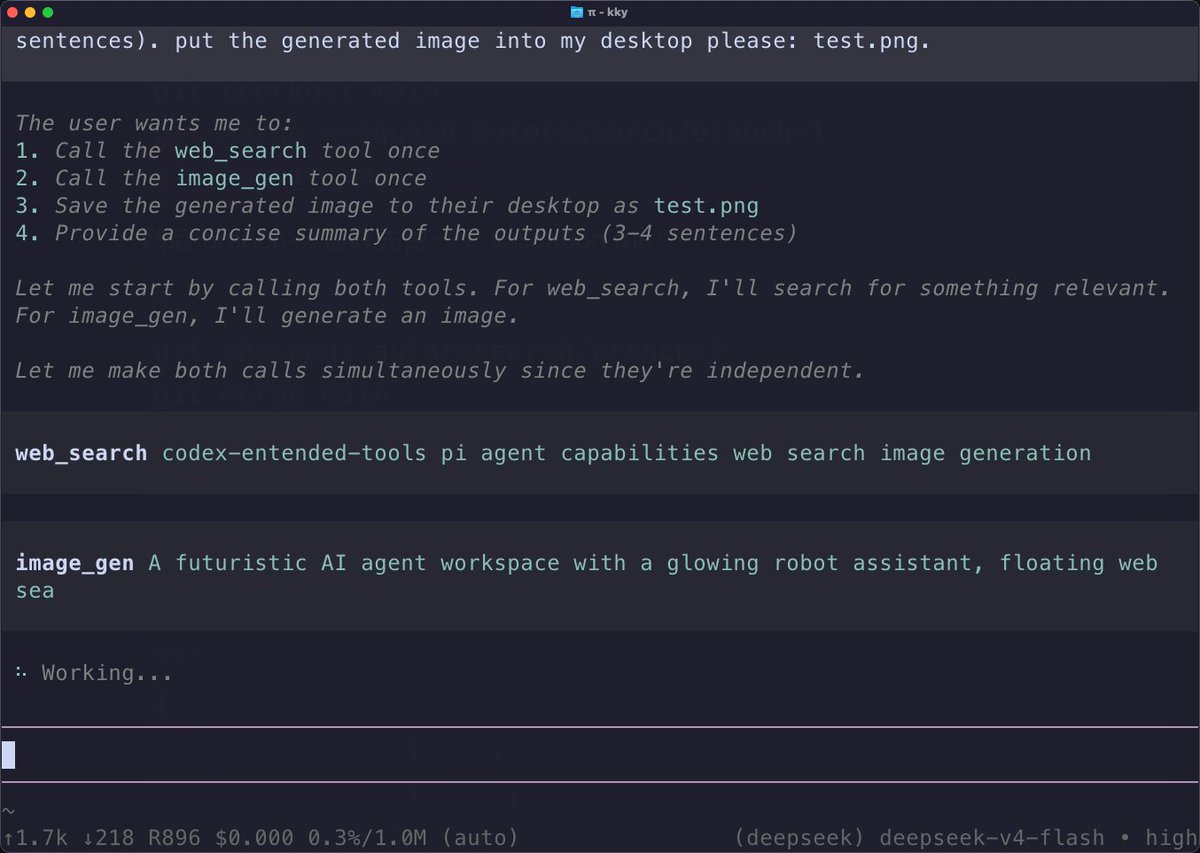
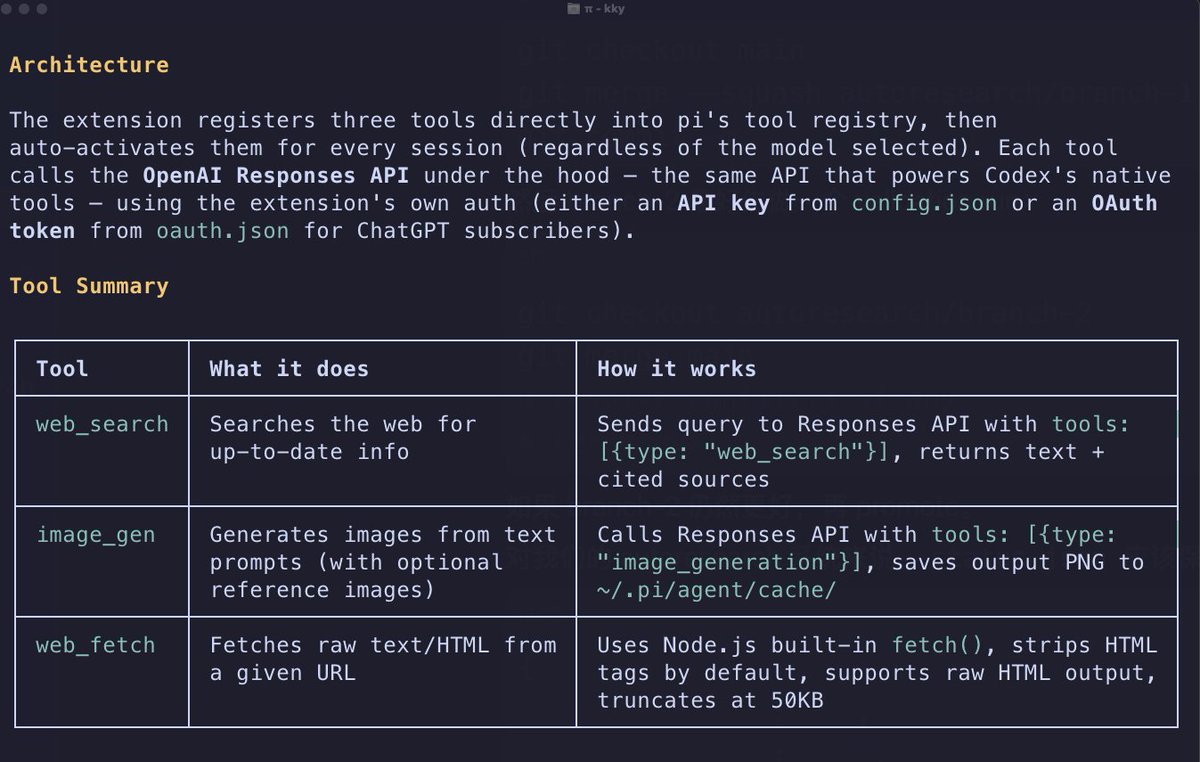
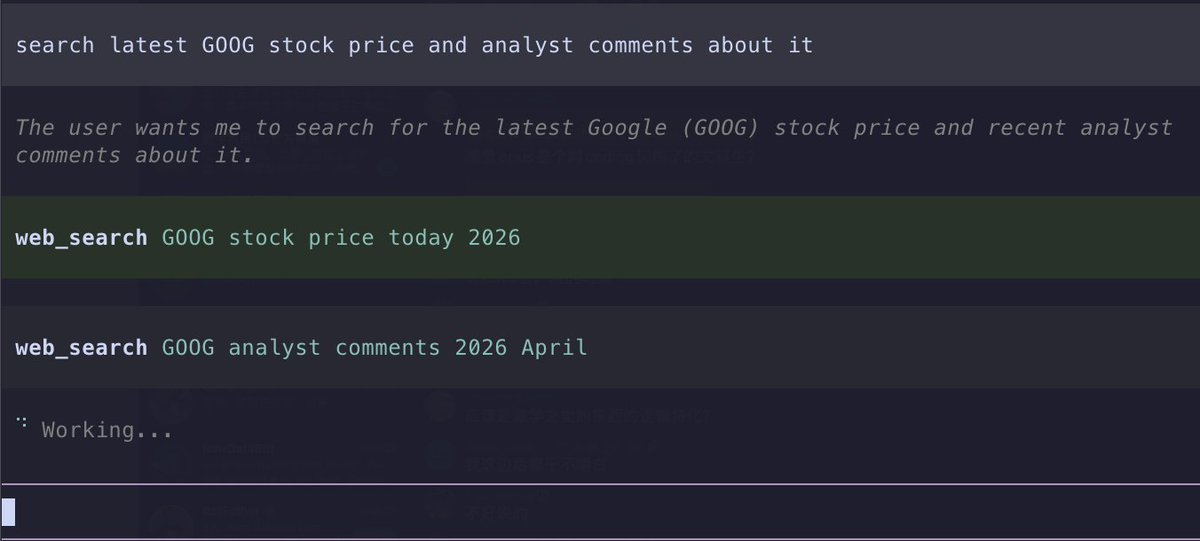
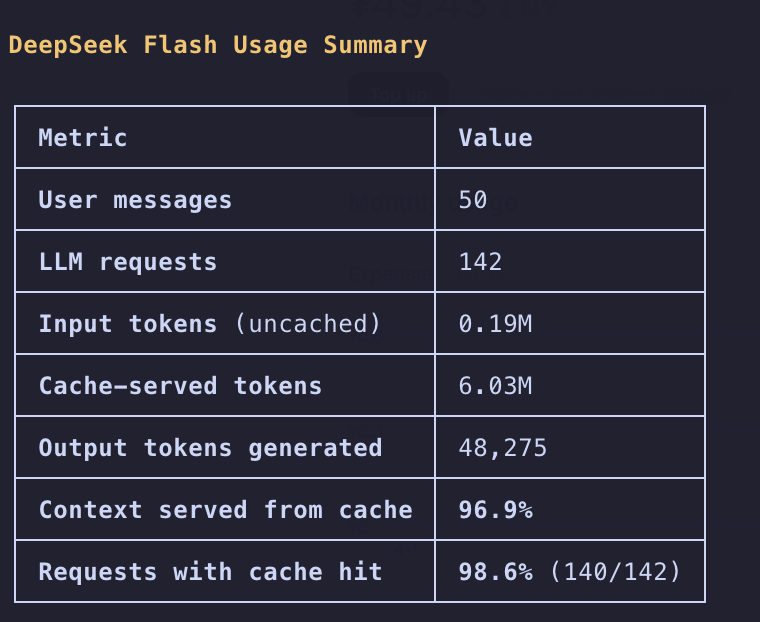
@VictorTaelin 1. Construct a preference(DPO) dataset, you could make it by talking with an agent. Let the agent interview you with two answers, you choose you answer.
2. Train a model through DPO-lora on that dataset.
Cheap but useful
English
KKY
202 posts
@evilpsycho42
Data scientist | Kaggle Global Rank 35th | 分享多模态、LLMs、生成视觉模型的实践和思考





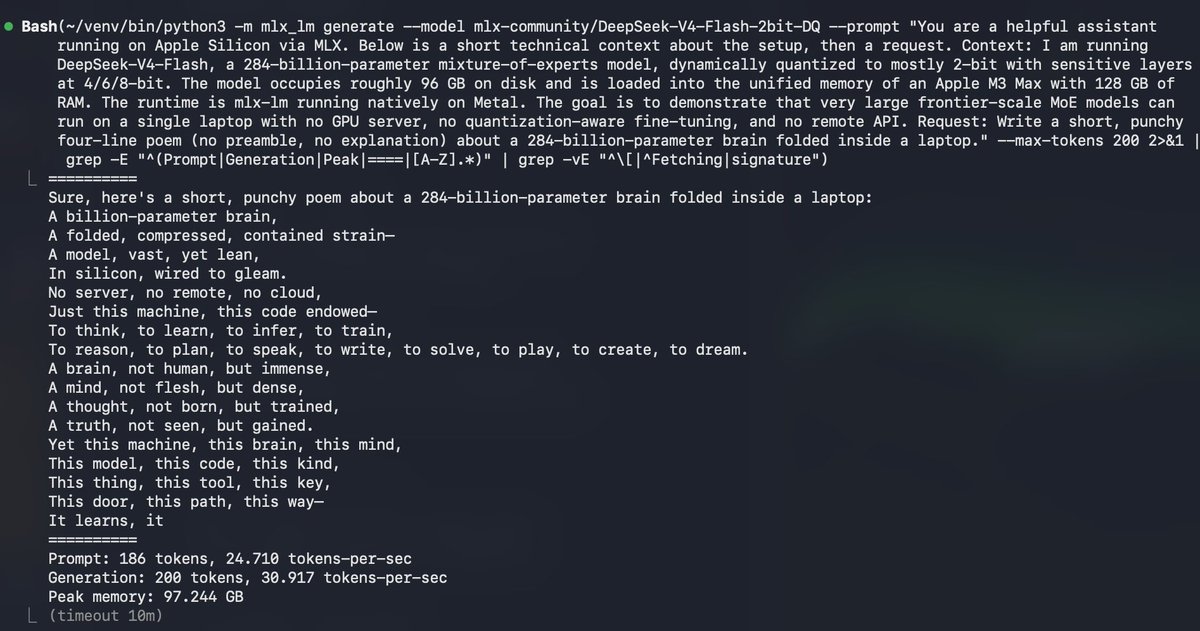


MacBookPro(M5Max)LMStudioでのMLXモデルの速度 Qwen3.6-35b-a3b-nvfp4 110tok/sec Qwen3.6-35b-a3b-mxfp8 85tok/sec Qwen3.6-27B-nvfp4 30tok/sec Qwen3.6-27B-mxfp8 17tok/sec


GPT-5.5 by @OpenAI is now live in the Arena, landing across multiple leaderboards. Here’s how it ranks by modality: - Code Arena (agentic web dev): #9, a strong +50pt jump over GPT-5.4 - Document Arena (analysis & long-content reasoning): #6, on par with Sonnet 4.6 - Text Arena: #7, Math #3, Instruction Following: #8 - Expert Arena: #5 - Search Arena: #2 - Vision Arena: #5 Strong, well-rounded performance, especially in Code (+50 pts vs GPT-5.4). Congrats to @OpenAI on the release. Full category breakdowns by modality in the thread.