Sabitlenmiş Tweet
仕方
194 posts







仕方 retweetledi




仕方 retweetledi


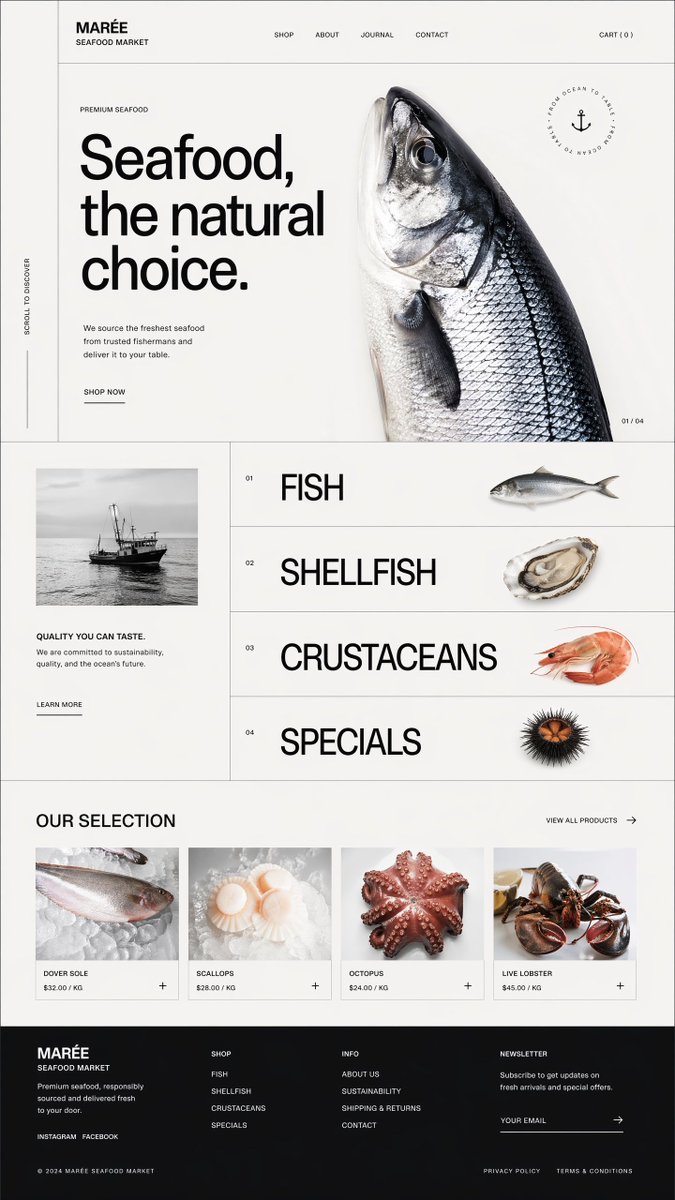
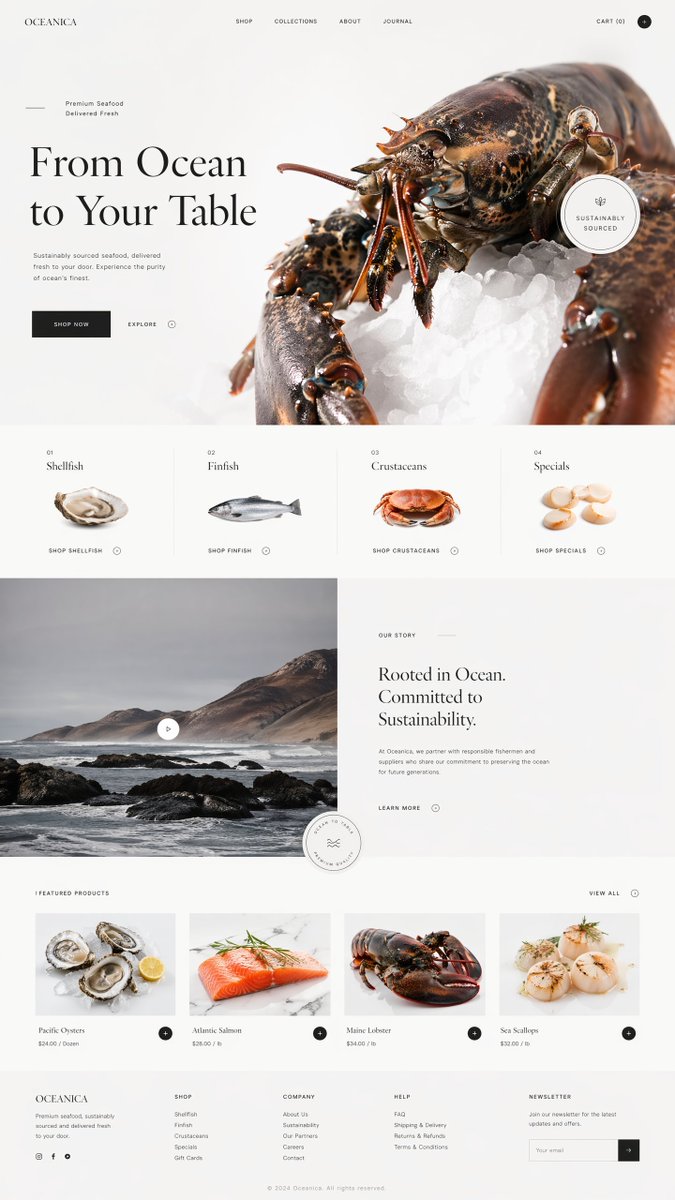
小红书上面抄的还是挺快,竟然还能这么抄,就截个图,文案都不改🤪
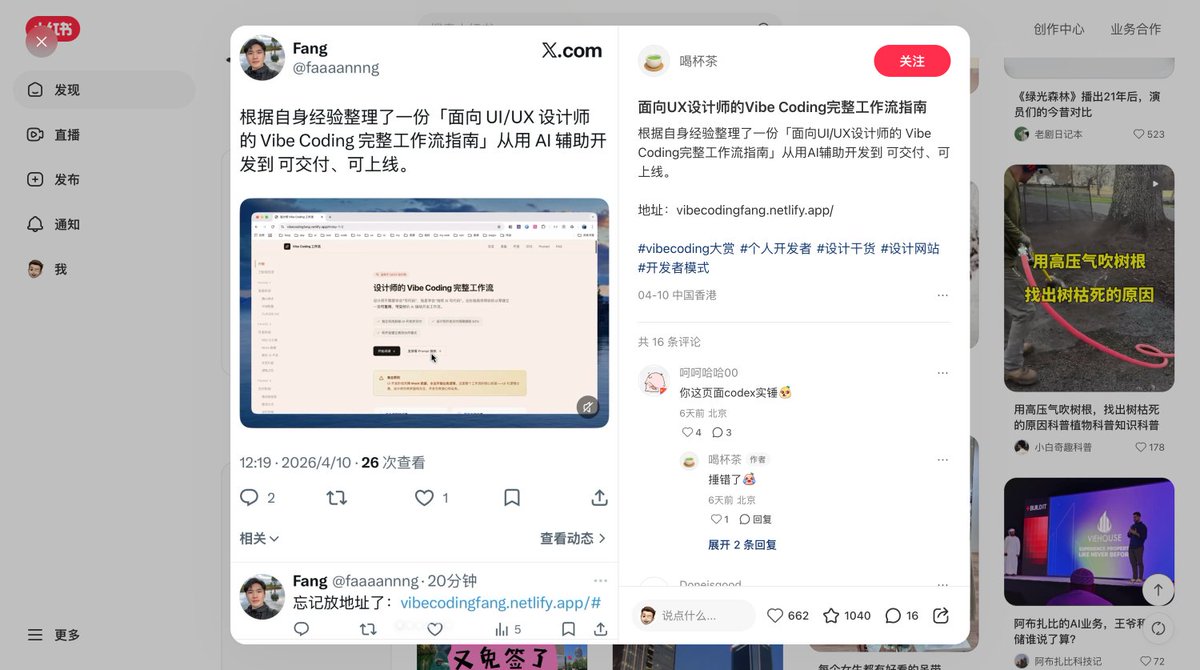
仕方@faaaannng
根据自身经验整理了一份「面向 UI/UX 设计师 的 Vibe Coding 完整工作流指南」从用 AI 辅助开发到 可交付、可上线。
中文
仕方 retweetledi

Anthropic 自家设计师 Ryan Mather,一人负责公司 7 个产品线。他发的几条自己用 Claude Design 的心得,结合官方教程:
1. 别急着干活,先花一小时搭你的设计系统。
把代码库、设计稿、品牌素材全塞给 Claude,让它抽出一套 UI Kit 并直接发布。这一小时的投入,以后你每次生成设计稿,风格都会自动套用,性价比爆表。公司要全面推开,可以投入一到两周做系统沉淀,道理不变:先沉下去规范,后面才有复利。
2. 别再玩接力,跟工程师一起边聊边改。
过去那种“设计师出稿→甩给工程师实现→回来再修改”的模式,已经过时了。开个会,你们一起看着画布,边讨论边敲定方案,一场会定下来直接开发,效率拉满。
3. 结构级大改用聊天,细节调整点评论。
你想换个深色模式、布局大洗牌、新增设置面板,或者一次出多个方向,这种级别的任务用聊天界面效率最高;按钮 padding 调一下、颜色换一换、输入框改下拉菜单,这种小修小补直接在元素上评论就行,精准又快速。
4. 反馈要具体,别给模糊情绪。
官方举过一个特别好的例子:「看着不对劲」就是最差反馈,而「表单字段间距改成 8px」才是智能体最爱听的明确指令。Claude 最擅长处理具象具体的要求,不善于揣摩你抽象的审美情绪。
5. 接上 Connector,让 Claude 读懂上下文。
Ryan Mather 提到他最爱的用法:把产品吐槽会议的纪要喂给 Claude,然后出去溜达一圈,回来一份完整的解决方案 Deck 已经自动生成了。
让 Claude 干复杂又综合的脑力活儿,你腾出手做更重要、更有创造力的事。
6. 关键时刻,别怕手工慢下来。
新图标、核心插画、产品名字、品牌形象,这类活儿别指望模型给你完美答案。这不是 Claude 不够牛,而是这事儿本质上考验的是你的个人品味和判断。Ryan 把这叫作“Agentic Designing 的艺术部分”。
7. 挂代码要精准,别塞整个 monorepo。
把整个 repo 拖进去会直接卡爆浏览器,模型的上下文也被无用信息污染了。你只要挂目标组件的文件夹或 package 就够了,记得排除 .git 和 node_modules,干净利索。
再补两条官方没说的小窍门:
1) 多开几个 Chat 平行探索。
同一个想法开 3 个对话,各自往不同方向跑一段,然后再挑精华合并,比在一个对话里反复折腾要高效太多。
2) 团队 Leader 得改改你的审查流程。
以前是“人做、人审”,现在是“Claude 做、人审”,这个差别巨大。如果你不调整节奏和人力配置,工具的价值会浪费一半,审查这一步一定要重构。
Ryan Mather@Flomerboy
🧵 My tips for getting the best results out of Claude Design! I’m on the verticals team at Anthropic which means I serve 7 different products. Claude Design makes it possible! 1. Set up your design system and your core screens. An hour of setup and refinement here is worth it
中文


仕方 retweetledi

仕方 retweetledi
推荐阅读若石写的这篇博客:模型不是笨,是 Harness 没配好
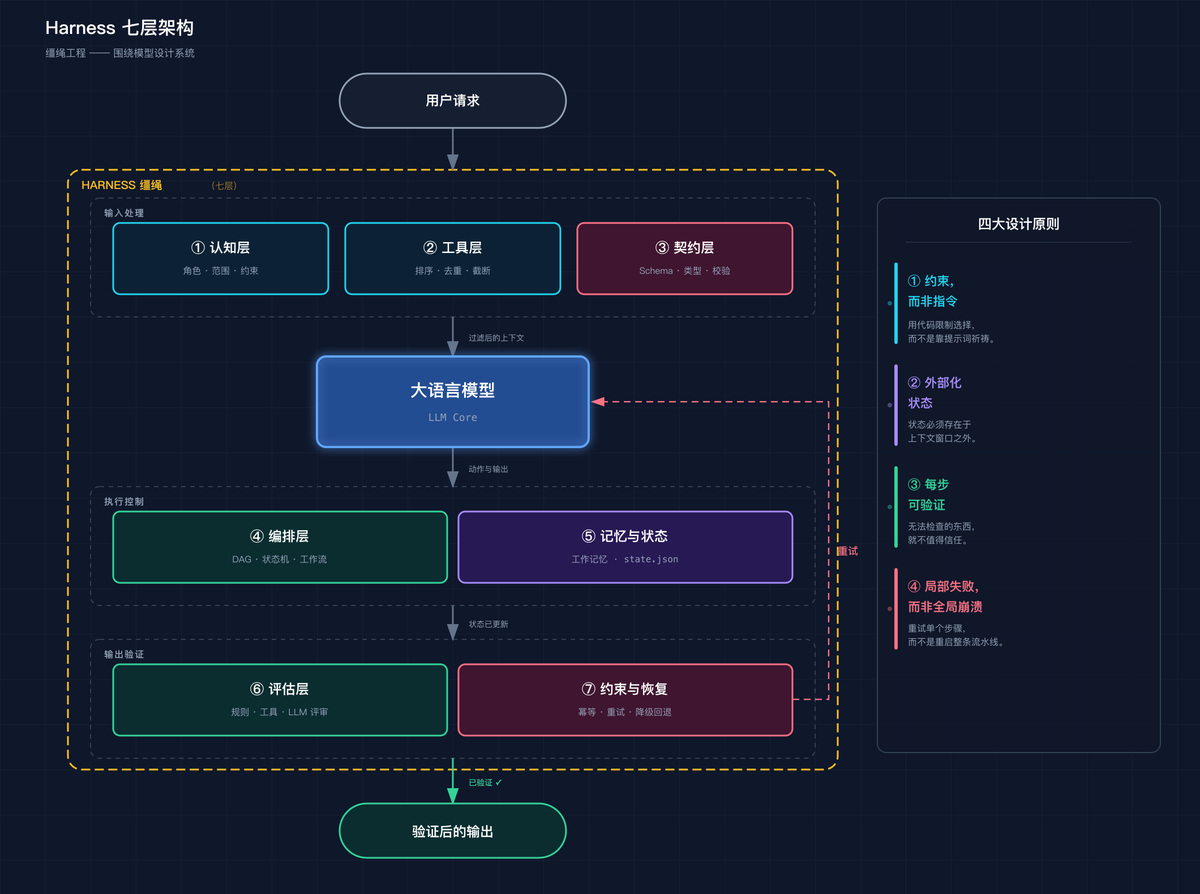
AI 智能体跑十步就崩,很多人第一反应是模型太蠢,但这篇文章却给出另一个视角:不是马不行,是缰绳没拴好。
文章提出的 Harness Engineering,你可以理解成给 AI 模型戴上安全带、装上安全气囊的工程实践。
过去两年,我们经历了两个阶段:Prompt Engineering(怎么问)、Context Engineering(喂什么料),但它们对付不了模型多步自主执行时的各种意外。
文章中有一个生动的例子:让一个智能体写市场分析报告,前三步相当顺利,但到第七步突然开始胡编乱造,因为搜索返回的内容超出上下文窗口被默默截掉了;第十步输出一段残破的 JSON,整条链路就此夭折,只能重头再来。
要解决这种问题,Harness Engineering 给出四个简单又实用的原则:
1. 能用代码约束的事儿,别指望模型自觉。
比如 JSON 格式,别在提示词里苦口婆心求模型输出合法内容,直接上 Schema 验证器,非法输出直接回炉。
2. 关键状态必须外置,不让模型在脑子里憋着。
就像你写代码不会只存在内存里一样,模型跑到哪一步、哪些任务完成了、哪些没做,都记到一个外部的 state.json 文件里,这样即使中途崩了,重新启动后还能接着来。
3. 模型输出不能自卖自夸,必须找第三方验收。
永远不要让模型给自己的作业评分,因为它总觉得自己很棒。需要一个独立的 Evaluator 模型,它不看原始思考过程,只对结果验收。最好还真能执行一下(跑跑编译器、打开页面看UI),而不是靠想象力评价。
4. 失败要限制在局部,不能一人出错全家连坐。
工具调用失败了,就让这一步重试,别搞得整个流程跟着陪葬。
文章后半段还提到了几个反直觉的坑:
首先是「上下文焦虑症」。
上下文一旦占了 70% 以上,模型就变得焦躁,开始跳步骤、草草收尾,好像急着下班一样。解决办法也很直观:别死守污染的上下文,干脆存盘、清空、重启一个干净实例继续干。
其次是「自评骗局」。
模型把稀烂的代码夸成“结构清晰、可读性佳”,根本不可信。真实验收标准必须独立而且有执行过程,不然你迟早翻车。
最后是「记忆整理周期」。
长期运行的智能体日志像凌乱的备忘录,新旧信息打架、浪费 token。这时候要做定期整理,把杂乱的日志压缩成清晰的状态文件。有团队靠这个技巧,把 32K token 的日志压到 7K,还一点不掉关键信息。
当然,让你一开始就搭出这种七层塔楼有点难度。
文章中提到了个一天内能落地的最小版本:
- 一个 state.json 存任务状态;
- 工具调用加 try/catch,失败就指数退避重试;
- 模型输出全都 Schema 校验;
- 工具返回的数据统一截断,绝不爆 token。
如果能做到这些,就能大幅提升智能体的任务成功率。推荐阅读原文。
若石@iceboundrock
Agents don't fail because models are weak. They fail because systems are undefined. blog.ltbase.dev/posts/agents/h…
中文
仕方 retweetledi
