
Fanf666
660 posts
Fanf666
@fanf666
Atypical rationalist with polymathic erudition, especially in pharmacology, technology and machine learning
Katılım Nisan 2020
335 Takip Edilen12 Takipçiler

@pkuhar The cheapest Direct Drive scooter wheel. ~20$ cost, can be as fast as 20 mph
English
Building up a mini Tidybot for <$2k in total.
More dynamic (realtime no speed up) and more robust
Plugged into upcoming X-bot universe with OpenClaw agentic applications.
github.com/TidyBot-Servic…
English
@philfung @hupobuboo @tonyh_lee @ajwagenmaker @KarlPertsch There is also huggingface.co/papers/2602.19…
English

added RoboReward to the reward comparison tool:
philfung.github.io/rewardscope
thanks @hupobuboo for suggesting to add this model and @tonyh_lee , @ajwagenmaker , @KarlPertsch for creating RoboReward!
pfung@philfung
Inspired by the TopReward paper, I made a lil web tool to test these robot manipulation rewards on your own videos. Try: philfung.github.io/rewardscope Record yourself folding a towel, upload it, and compare: 1. TopReward (this paper) 2. GVL (Deepmind) 3. Brute Force (i.e. at each frame, ask LLM to reply with a probability) TopReward (Qwen3VL-8B) holds its own surprisingly well against the others, even if those use ChatGPT! Great work @DJiafei, UW, AllenAI, thanks for pushing @VilleKuosmanen.
San Francisco, CA 🇺🇸 English

What can half of GPT-1 do? We trained a 42M transformer called SONIC to control the body of a humanoid robot. It takes a remarkable amount of subconscious processing for us humans to squat, turn, crawl, sprint. SONIC captures this "System 1" - the fast, reactive whole-body intelligence - in a single model that translates any motion command into stable, natural motor signals. And it's all open-source!!
The key insight: motion tracking is the one, true scalable task for whole body control. Instead of hand-engineering rewards for every new skill, we use dense, frame-by-frame supervision from human mocap data. The data itself encodes the reward function: "configure your limbs in any human-like position while maintaining balance".
We scaled humanoid motion RL to an unprecedented scale: 100M+ mocap frames and 500,000+ parallel robots across 128 GPUs. NVIDIA Isaac Lab allows us to accelerate physics at 10,000x faster tick, giving robots many years of virtual experience in only hours of wall clock time. After 3 days of training, the neural net transfers zero-shot to the real G1 robot with no finetuning. 100% success rate across 50 diverse real-world motion sequences.
One SONIC policy supports all of the following:
- VR whole-body teleoperation
- Human video. Just point a webcam to live stream motions.
- Text prompts. "Walk sideways", "dance like a monkey", "kick your left foot", etc.
- Music audio. The robot dances to the beat, adapting to tempo and rhythm.
- VLA foundation models. We plugged in GR00T N1.5 and achieved 95% success on mobile tasks.
We open-source the code and model checkpoints!! Deep dive in thread:
English
@paulkhls @Bio_Protocol @sciencebeach @Molecule_sci I beg you to do this for orexin agonists and neuropeptide s receptor agonists
English

🧵 We just designed three novel GLP-1 receptor agonists from scratch on a Sunday afternoon using autonomous AI agents on @bio_protocol infrastructure
Not a pharma lab. Not a $70M seed round. An AI scientist, a hypothesis on @ScienceBeach, and onchain compute via @Molecule_sci - here's what happened

English
@AnjariaManan I really don't see the point in those overpriced swerves VS Mechanum or a DIY swerve without any gears by placing a motor on the wheel.
English
@AnjariaManan While this is much needed I urge you to merge or take things from AhaRobot. AhaRobot cost 800$ and has as much arm force. What's needed is to make it holonomic.
Also why a swerve vs Mechanum ?
English

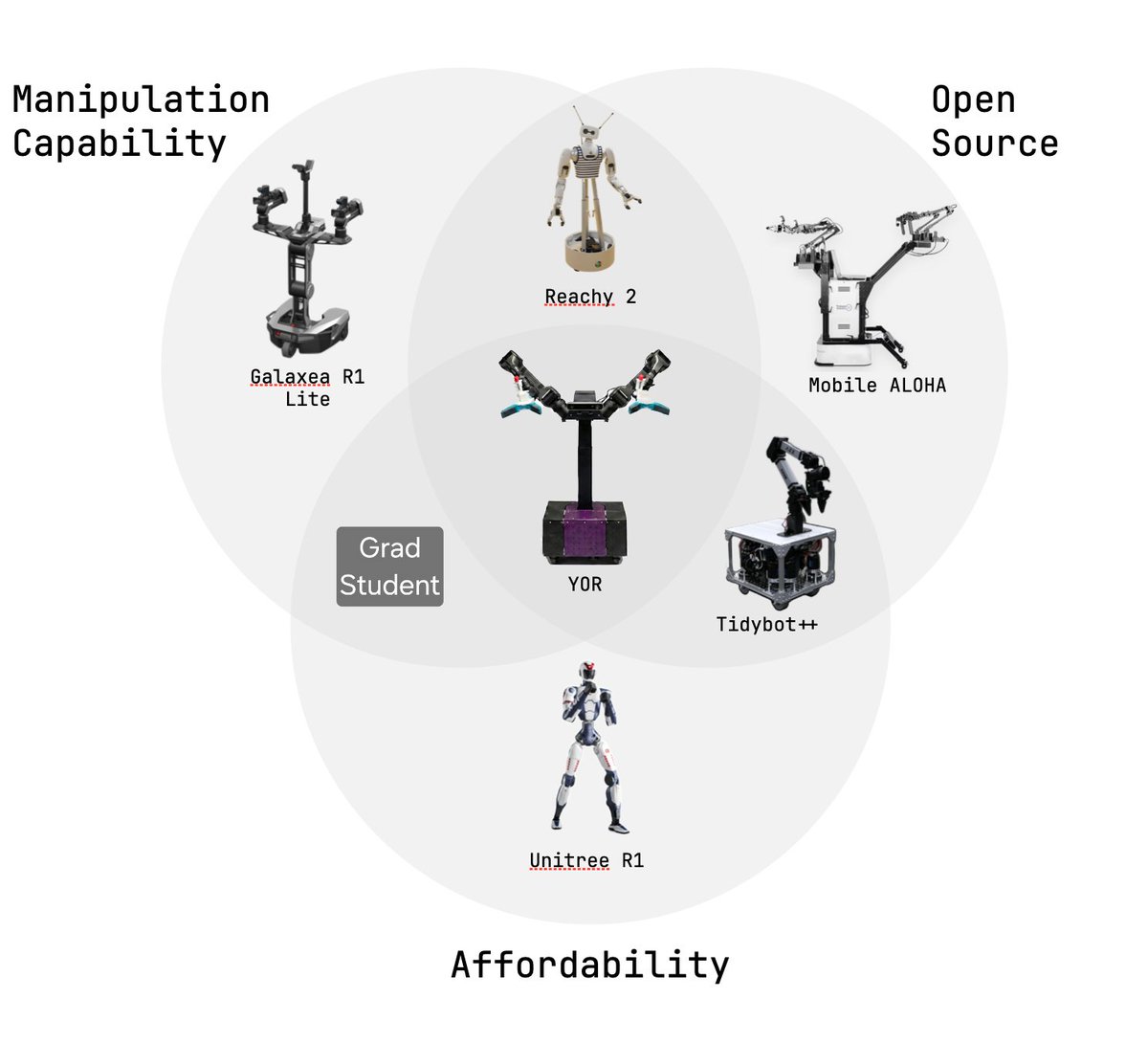
The real gap isn't capability, it's accessibility. We need platforms that labs can actually build, hack and improve without needing Big budgets or NDAs. Something modular, documented, cheap and yet capable enough to conduct hours of research .
We present you YOR
Mahi Shafiullah 🏠🤖@notmahi
Why buy a robot when you can build your own? Meet YOR, our new open-source bimanual mobile manipulator robot – built for researchers and hackers alike for only ~$10k. 🧵👇
English

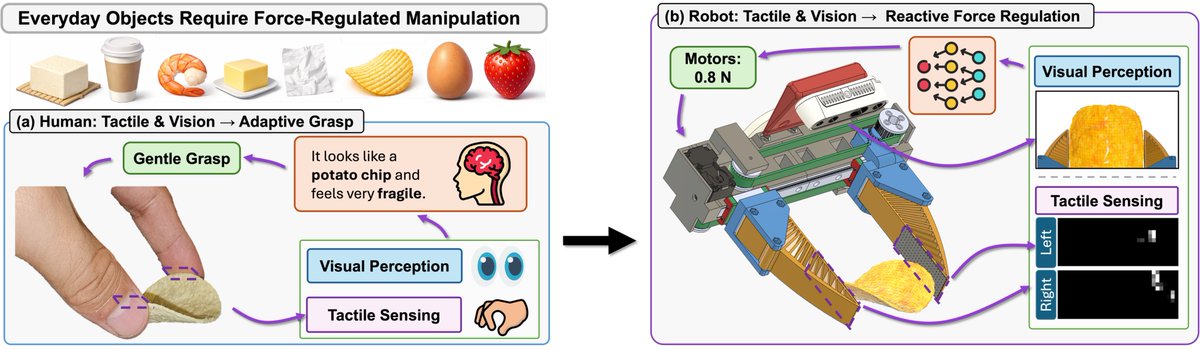
How can robots handle fragile, soft everyday objects like humans do, using vision & tactile to regulate force? 🤖🥚
Introducing our full-stack solution: a low-cost ($150) force gripper (0.45~45N), a force-aware teleoperator, and a reactive policy for learning force control.
English

1/
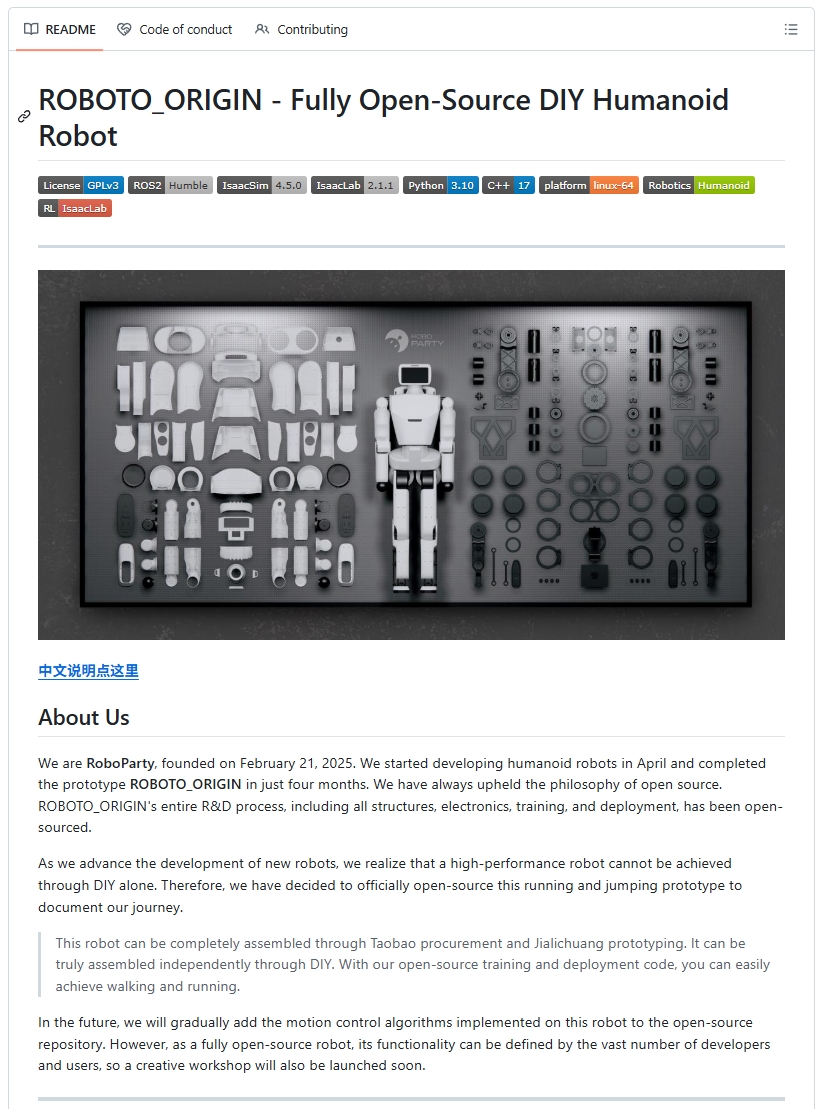
Humanoid robotics doesn’t need more demos. It needs more rebuildable baselines.
So we open-sourced RoboParty ROBOTO ORIGIN: hardware + motion control + bring-up + validation.
Built in 120 days — from zero to 3 m/s running.
Let’s make humanoids reproducible.
English

Running Pi0.5 on AlohaMini (~$600 open-source BOM).
• 20-episode fine-tuning
• Action-space aligned
• Randomized object placement
Experience: aligning the action space with Pi0.5 noticeably improved the task success rate.
Exploring how far low-cost embodied hardware can go.
@LeRobotHF @lachygroom
English
@YJH_GIGIYE Would be nice if you could make the same for robot dogs (wheeled or not)
English

🎓Scholar Insights
FastStair framework empower LimX's Oli conquers stairs at speeds of 1.65m/s, seamlessly blending model-based stability with high-speed reinforcement learning.
📚Arxiv: arxiv.org/pdf/2601.10365
💡Project: npcliu.github.io/FastStair/

English

Enabled fp8 training for +4.3% improvement to "time to GPT-2", down to 2.91 hours now. Also worth noting that if you use 8XH100 spot instance prices, this GPT-2 repro really only costs ~$20. So this is exciting -
GPT-2 (7 years ago): too dangerous to release.
GPT-2 (today): new MNIST! :)
Surely this can go well below 1 hr.
A few more words on fp8, it was a little bit more tricky than I anticipated and it took me a while to reach for it and even now I'm not 100% sure if it's a great idea because of less overall support for it. On paper, fp8 on H100 is 2X the FLOPS, but in practice it's a lot less. We're not 100% compute bound in the actual training run, there is extra overhead from added scale conversions, the GEMMs are not large enough on GPT-2 scale to make the overhead clearly worth it, and of course - at lower precision the quality of each step is smaller. For rowwise scaling recipe the fp8 vs bf16 loss curves were quite close but it was stepping net slower. For tensorwise scaling the loss curves separated more (i.e. each step is of worse quality), but we now at least do get a speedup (~7.3%). You can naively recover the performance by bumping the training horizon (you train for more steps, but each step is faster) and hope that on net you come out ahead. In this case and overall, playing with these recipes and training horizons a bit, so far I ended up with ~5% speedup. torchao in their paper reports Llama3-8B fp8 training speedup of 25% (vs my ~7.3% without taking into account capability), which is closer to what I was hoping for initially, though Llama3-8B is a lot bigger model. This is probably not the end of the fp8 saga. it should be possible to improve things by picking and choosing which layers to apply it on exactly, and being more careful with the numerics across the network.
Andrej Karpathy@karpathy
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node). GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100. Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc. As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try. A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here: github.com/karpathy/nanoc… Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning. The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up. Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
English
@AI_Nate_SA @omarsar0 VLA are a dead end and obsolete.
Modular agents allow higher performance, flexibility and in a zero shot manner.
English

The "no saturation" finding at 20,000 hours is the headline, but the engineering underneath LingBot-VLA is just as impressive. Hitting 261 samples per second per GPU is a massive optimization over codebases like StarVLA—you simply can't scale to that volume of real-world data without that kind of throughput.
It’s also smart to see them leveraging Qwen2.5-VL within that Mixture-of-Transformers design. Keeping high-level semantic priors separate from the action generation seems to be the key to avoiding interference. Beating π0.5 on the GM-100 benchmark by such a margin (17.30% vs 13.02%) really validates this "pragmatic" approach.
English

First empirical evidence that VLA models scale with massive real-world robot data.
VLA foundation models promise robots that can follow natural language instructions and adapt to new tasks quickly. However, the field has lacked comprehensive studies on how performance actually scales with real-world data.
This new research introduces LingBot-VLA, a Vision-Language-Action foundation model trained on approximately 20,000 hours of real-world manipulation data from 9 dual-arm robot configurations.
Scaling pre-training data from 3,000 hours to 20,000 hours improves downstream success rates consistently, with no signs of saturation.
More data still helps.
The architecture uses a Mixture-of-Transformers design that couples a pre-trained VLM (Qwen2.5-VL) with an action expert through shared self-attention. This allows high-dimensional semantic priors to guide action generation while avoiding cross-modal interference.
On the GM-100 benchmark spanning 100 tasks across 3 robotic platforms with 22,500 evaluation trials, LingBot-VLA achieves 17.30% success rate and 35.41% progress score, outperforming π0.5 (13.02% SR, 27.65% PS), GR00T N1.6 (7.59% SR, 15.99% PS), and WALL-OSS (4.05% SR, 10.35% PS).
In simulation on RoboTwin 2.0, the model reaches 88.56% success rate in clean scenes and 86.68% in randomized environments, beating π0.5 by 5.82% and 9.92% respectively.
Training efficiency matters for scaling. Their optimized codebase achieves 261 samples per second per GPU on an 8-GPU setup, representing a 1.5-2.8× speedup over existing VLA codebases like StarVLA, OpenPI, and DexBotic.
Data efficiency is equally impressive: with only 80 demonstrations per task, LingBot-VLA outperforms π0.5 using the full 130-demonstration set.
This is the first empirical demonstration that VLA performance continues scaling with more real-world robot data without saturation, providing a clear roadmap for building more capable robotic foundation models.
Paper: arxiv.org/abs/2601.18692
Learn to build effective AI agents in our academy: dair-ai.thinkific.com

English

We release Cosmos Policy 💫: a state-of-the-art robot policy built on a video diffusion model backbone.
- policy + world model + value function — in 1 model
- no architectural changes to the base video model
- SOTA in LIBERO (98.5%), RoboCasa (67.1%), & ALOHA tasks (93.6%)
🧵👇
English
@sentdefender Insane to pretend there is a need to reverse engineer such trivial drones
English

Renault Group, the French multinational automobile manufacturer, is preparing to launch the production of long-range attack drones at its factories in Le Mans and Cléon, with cooperation from the aerospace and defense manufacturer Turgis et Gaillard Groupe.
Renault has stated that it intends to produce 600 drones per month, with employees and equipment being transferred from its automotive manufacturing lines in France.
Chorus, the name of the drone to be manufactured by Renault, are meant to be reverse engineered Russian/Iranian “Shahed-131/136 One-Way Attack Drones, which have been used in the tens if not hundreds of thousands in the Middle East and Ukraine.

English
@CherriRip1964 @NatureMedicine For migraine gepants might help. Maybe botox too. Most importantly you should consider trying stellate ganglion block.
Also maybe carbamazepine for pain reduction. CoQ10 weak but nice to have, NAC too. Glp1 maybe
English

I how do I go about getting help with having something like this done to me. I’ve had a a massive headache for over 11 yrs w/o any stoppage & am in critical condition, have numerous other chronic health issues, in which I am becoming more & more bedfast after: I had my neck broken in 2003, -which resulted in my having (15) 1& half inch screws installed in my neck vertebrae’s, a long Titanium rod & plate installed & all but 2 neck vertebrae’s bone grafted & fused together. But unfortunately I began getting really sick afterwards & w/i 5 yrs, I fell down & shattered 7 additional vertebrae’s in my back btwn’ my shoulder blades. Then within 4 more yrs’ my spinal column collapsed by 5 more inches & now I have heart problems, my gastrointestinal system is failing & I’m mostly bedfast due to a plethora of other serious issues such lymphatic issues & blood circulation issues as well. I’m now 61yo. And when my neck was broken I dev’d severe PTSD due to it being caused by a s** predator who’d snatched me & he’d nearly killed me numerous times before I he broke my neck & I thankfully was covertly rescued w/i 24 hrs after he had dragged me down a flight of stairs by my long hair.
English

Researchers studied blood-based metabolome of over 23,000 individuals from 10 ethnically diverse cohorts. They identified 235 metabolites associated with future risk of T2D. By integrating genetic and modifiable lifestyle factors, their findings provide insights into T2D mechanisms and could improve risk prediction and inform precision prevention.
nature.com/articles/s4159…
English
Fanf666 retweetledi

Force is the missing modality in in-the-wild robot learning.
UMI-FT introduces coin-sized 6-axis force torque sensors on each finger, capturing both external contact forces and internal grasp forces during human demonstrations
English
@ziwenzhuang_leo That's amazing, could you make it work on a wheeled dog?
Such as DIY flores or Unitree
github.com/ZhichengSong6/…
English

We believe robots need instinct, not only reasoning.
Introducing Project-Instinct — a full-stack, instinct-level whole-body control toolkit for legged & humanoid robots.
🔗 project-instinct.github.io
(1/3)
English

Check out our blog for more results and details: 1x.tech/discover/world…
We have many technical challenges to solve from faster inference and lower latency, to continual closed loop replanning and stronger physical alignment. If you are interested in world model driven robotics, come help us generate our way to household autonomy: 1x.recruitee.com/o/ai-research-…
English
Introducing 1XWM, a world-model-based policy that turns text-conditioned video generation into robot actions.
It leverages dynamics learned from internet-scale video to generalize to novel objects and tasks, using limited robot data for grounding instead of task-specific demonstrations.
(WM generation on left, real robot execution on right)
1X@1x_tech
NEO’s Starting to Learn on Its Own
English