Sabitlenmiş Tweet

Finalmente saiu: apresento a vocês o uPubly!
Estamos oficialmente nos inserindo no mercado de gestão de redes sociais no Brasil
Nossa missão é facilitar a vida de quem quer ter presença digital sem muito custo ou muito trabalho
Por isso demoramos 9 meses pra chegar até aqui, fomos e voltamos várias vezes até chegar em algo que parecia o ideal para a maioria das pessoas publicar em várias redes sociais com o minimo de esforço.
Preparamos cupons de desconto especiais no final da thread!
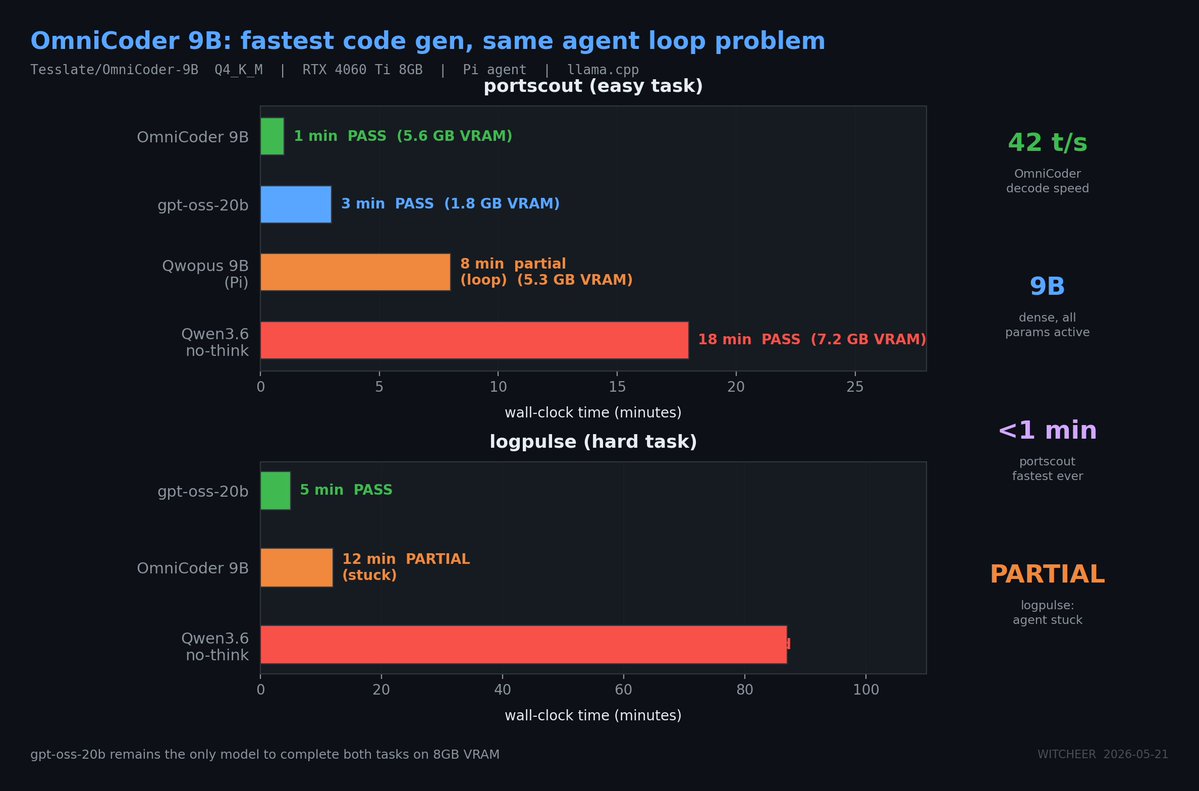
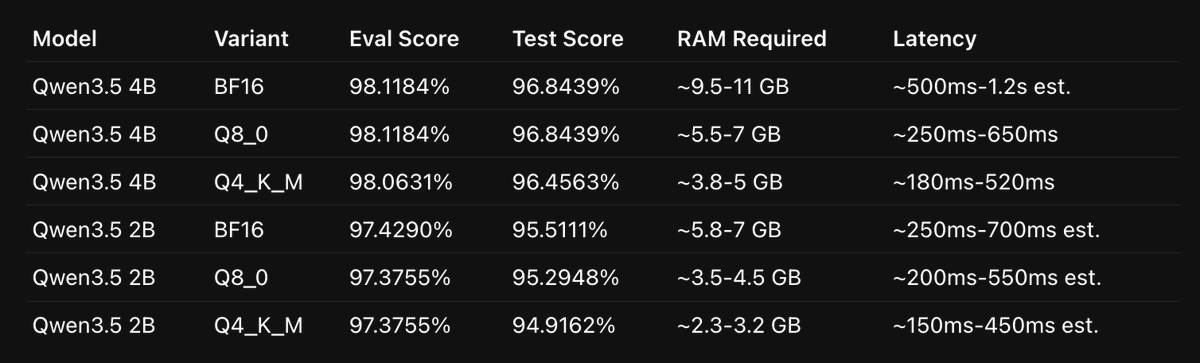
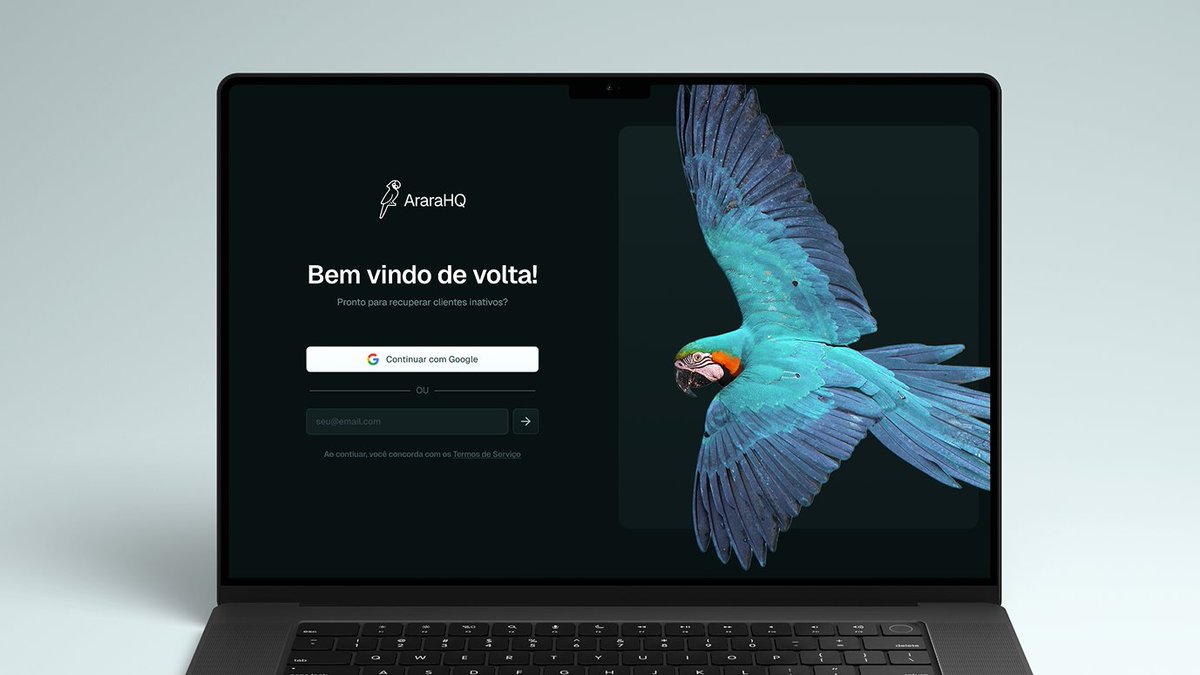
Aqui em baixo estão as features mais importantes do lançamento.

Português