
F. Gianferrari Pini
5.3K posts
F. Gianferrari Pini
@fgianferrari
dad & enterpreneur. opinions are mine
Monza, Italy Katılım Nisan 2009
696 Takip Edilen306 Takipçiler

The most common mistakes I see teams make with LLM judges:
• Too many metrics
• Complex scoring systems
• Ignoring domain experts
• Unvalidated measurements
That's why I wrote this guide, w/ detailed examples to help people avoid these issues (1/4)
hamel.dev/blog/posts/llm…
English

RAG is overrated. Reports are the real game-changer.
It's not about saving time answering questions. It's about generating high-value decision-making tools that drive business outcomes.
The future of AI isn't chat. It's crafting the perfect report template.
jxnl.co/writing/2024/0…
English



The related Papers
a) arxiv.org/abs/2402.17764
b) arxiv.org/abs/2310.11453
English
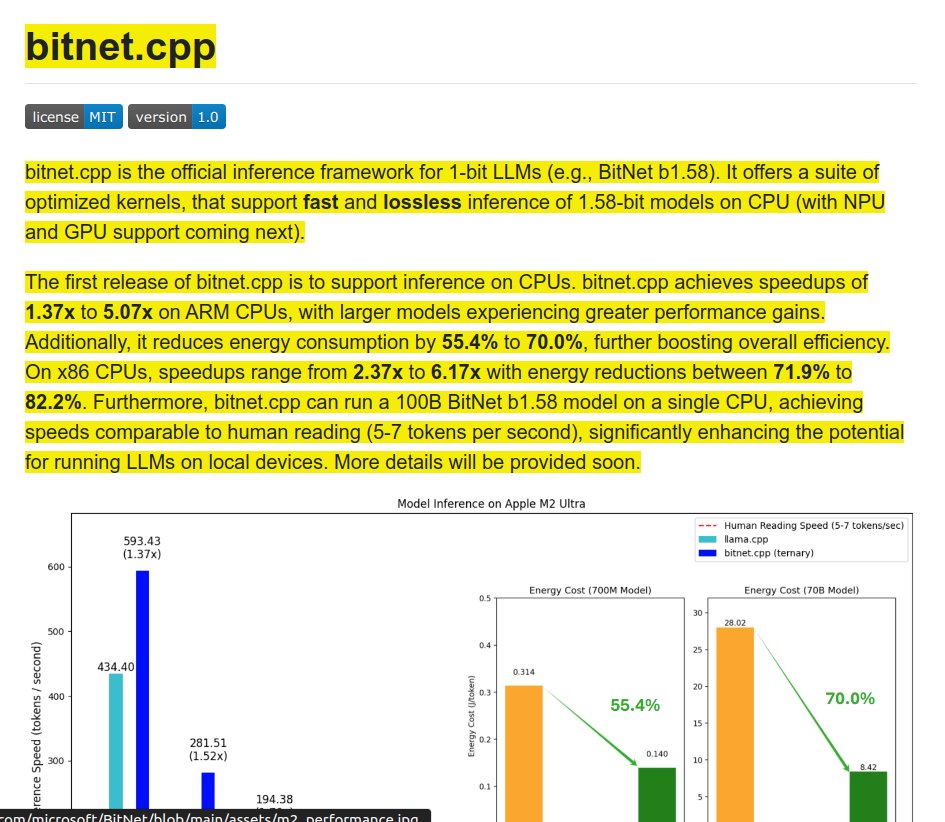
WOW. @Microsoft just open-sourced the code for one of "THE MOST" influential Paper of 2024 🔥
1-bit LLMs (e.g., BitNet b1.58).
Now you can run a 100B param models on local devices quantized with BitNet b1.58 on single CPU at 5-7 tokens/sec 🤯
The dream we have all been waiting for.
📊 Performance Improvements:
- Achieves speedups of 1.37x to 5.07x on ARM CPUs
- Larger models see greater performance gains
- Reduces energy consumption by 55.4% to 70.0% on ARM
- On x86 CPUs, speedups range from 2.37x to 6.17x
English

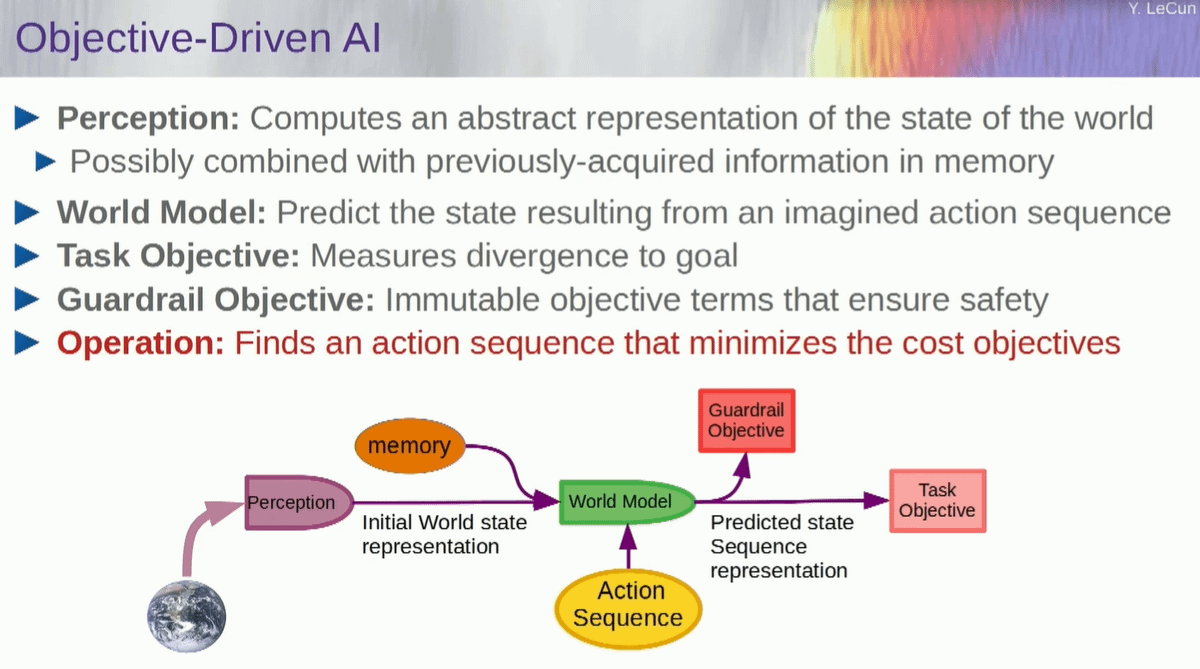
We need to achieve human-level AI. But how can we get there?
@ylecun proposes Objective-Driven AI as a promising new direction for achieving human-like reasoning and planning.
Here are the main points from his keynote at the Hudson Forum:

English

Confession: despite all of the debates about whether or not an LLM can "reason", I still don't really understand exactly what the term "reasoning" means
So just like with "agents" and "AI" itself, I'm not sure the people engaged in those debates are talking about the same thing
English

English

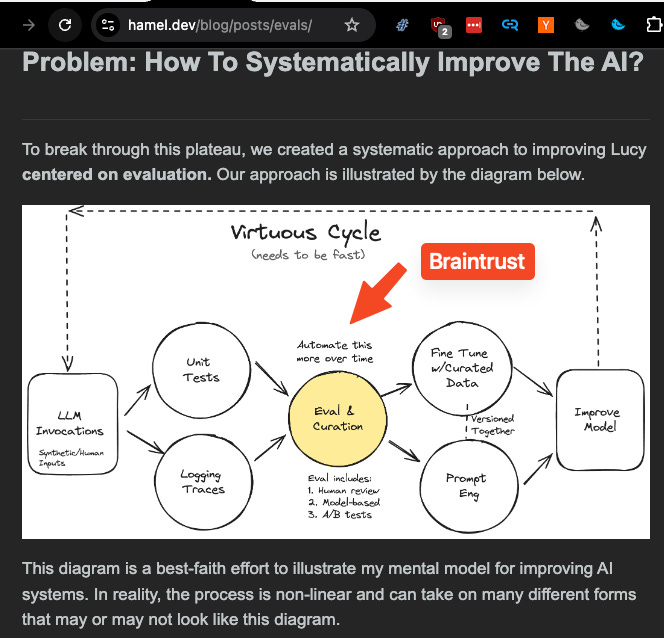
🆕 Production AI Engineering starts with Evals
latent.space/p/braintrust
A 2 hour deep dive on the state of the LLM Ops industry with @ankrgyl following the @braintrustdata Series A!
We discuss:
why @HamelHusain was right: Evals are at the center of the production AI engineering map
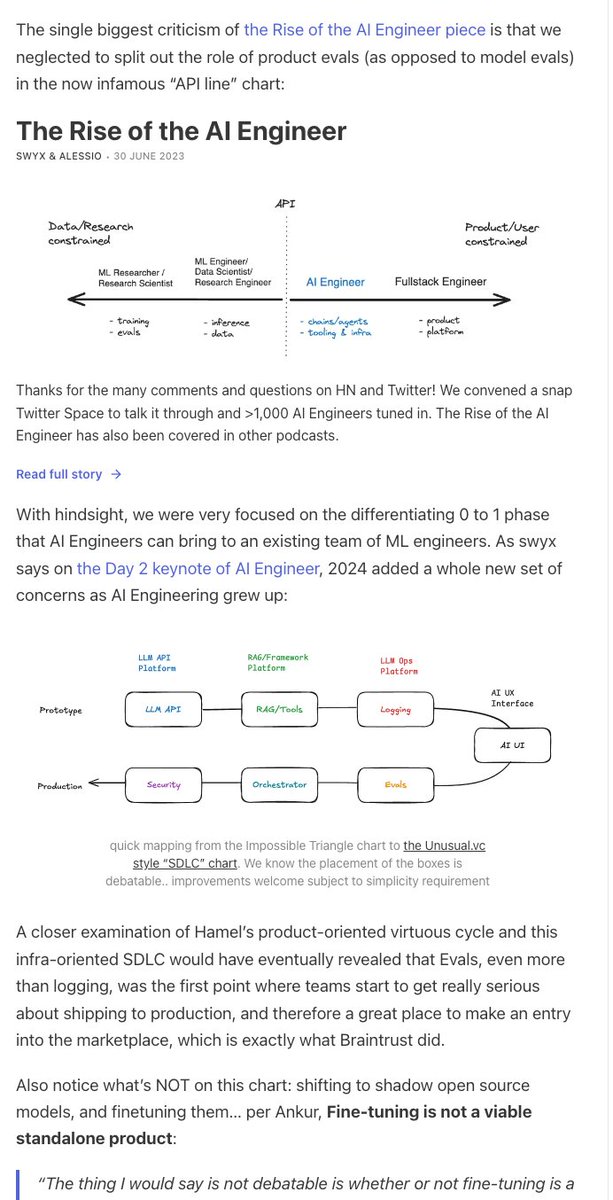
swyx's pet theory on the Impossible Triangle of LLM Infra:
leading to an update of @doppenhe's AI SDLC chart:
as well as more info on the shocking <5% open source stats I teased last month!


English
Are you building Starlette based apps (FastAPI, FastHTML, etc) apps but are confused by how to run things in the background (ex: LLM calls)?
This thread is for you! I did a deep dive into this
First, how can you use your SQL DB directly as a queue?
1/10

English
Re: CaseText & eval driven development (EDD) for AI.
EDD was always front and center pre-generative AI. Ex: nobody cares about your fraud/churn/forecasting model if it’s not accurate.
This is missing with most LLM products. But the best practices and playbooks are there in classic ML! It’s a bit amusing that EDD is an epiphany (but glad there is attention being brought to it)
Here are some posts that may be helpful
1. hamel.dev/blog/posts/eva…
2. eugeneyan.com/writing/evals/
Garry Tan@garrytan
One bad experience with an AI agent and users give up, and often they never return. How do you get LLMs to hit 100% accuracy?
English

*An introduction to State Space Models*
by @chuswlove
Nice series of blog post on structured SSMs, organized in 3 parts and covering up to Mamba-2. Great balance between math and intuitions!
chus.space/blog/2024/ssm_…

English

We spent a year developing cde-small-v1, the best BERT-sized text embedding model in the world.
today, we're releasing the model on HuggingFace, along with the paper on ArXiv.
I think our release marks a paradigm shift for text retrieval. let me tell you why👇

English

You won’t believe your eyes, wild
but your brain can’t compute inaccurate facial information when faces are turned upside down.
rotate your phone and see for yourself
1. Famous singer…

English

Sometimes, the obvious must be studied so it can be asserted with full confidence:
- LLMs can not answer questions whose answers are not in their training set in some form,
- they can not solve problems they haven't been trained on,
- they can not acquire new skills our knowledge without lots of human help,
- they can not invent new things.
Now, LLMs are merely a subset of AI techniques.
Merely scaling up LLMs will *not* lead systems with these capabilities.
There is little doubt AI systems will have these capabilities in the future.
But until we have small prototypes of that, or at least some vague blueprint, bloviating about AI existential risk is like debating the sex of angels (or, as I've pointed out before, worrying about turbojet safety in 1920).
bath.ac.uk/announcements/…
English

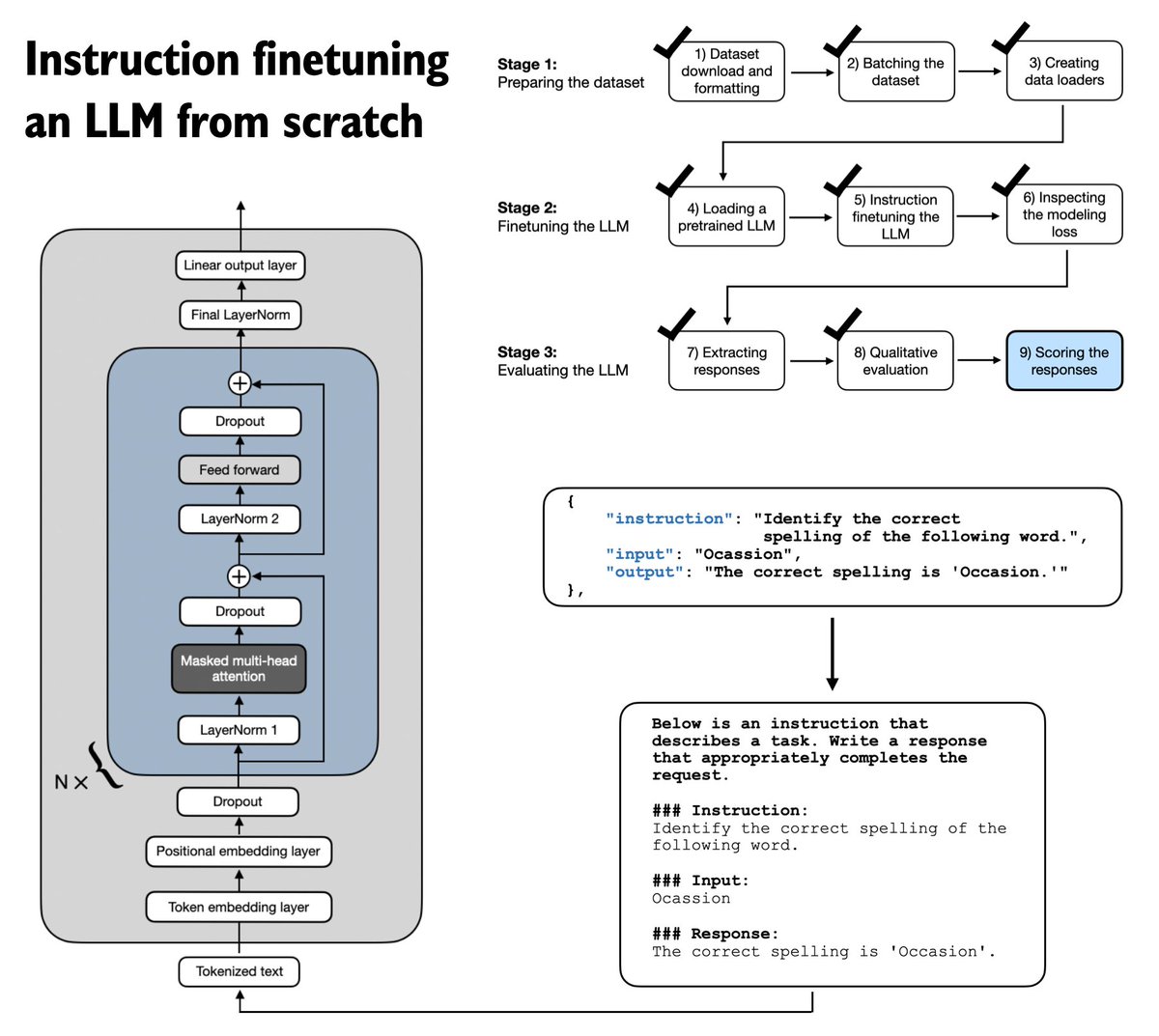
If you are looking for something to read this weekend, I am happy to share that Chapter 7 on instruction finetuning LLMs is now finally live on the Manning website: manning.com/books/build-a-…
This is the longest chapter in the book and takes a from-scratch approach to implementing the instruction finetuning pipeline. This includes everything from input formatting to batching with a custom collate function, masking padding tokens, the training loop itself, and scoring the response quality of the finetuned LLM on a custom test set.
(The exercises include changing prompt styles, instruction masking, and adding LoRA.)
As a side note, it's also the last chapter, and the publisher is currently preparing the layouts for the print version.
PS: After moving, traveling, and returning from the awesome SciPy conference, I am now also super eager to finally type up my notes from recent research papers on the instruction finetuning front. I will share them soon, in the next few days, as a follow-up!
English
English
One of the least talked about subjects in AI/ML is how to clean, curate and look at data. Its the least sexiest but most important topic.
Good news, @vanstriendaniel & @davidberenstei has an entire talk on this
Links in next tweet


English
English

Property Graphs are powerful tools that allow you to model complex relationships from documents, featuring properties on both nodes and edges.
We are excited to announce a 6-part video series on Property Graphs in LlamaIndex using @mistralai, @neo4j and @ollama, presented in a brand-new tutorial series by @ravithejads!
➡️ What’s a property graph and why is it useful?
➡️ How to build a property graph in LlamaIndex
➡️ Building graph data extractors and retrievers
➡️ Using Neo4j with LlamaIndex
➡️ Using Ollama with pre-defined schemas
➡️ Building custom retrievers
youtube.com/playlist?list=…

English

There was a super impressive AI competition that happened last week that many people missed in the noise of AI world. I happen to know several participants so let me tell you a bit of this story as a Sunday morning coffee time.
You probably know the Millennium Prize Problems where the Clay Institute pledged a US$1 million prize for the first correct solution to each of 7 deep math problems. To this date only one of these, the Poincaré conjecture, has been solved by Grigori Perelman who famously declined the award (go check Grigori out if you haven't the guy has a totally based life).
So this new competition, the Artificial Intelligence Math Olympiad (AIMO) also came with a US$1M prize but was only open to AI model (so the human get the price for the work of the AI...). It tackle also very challenging but still simpler problems, namely problems at the International Math Olympiad gold level. Not yet the frontier of math knowledge but definitely above what most people, me included, can solve today.
The organizing committee of the AIMO is kind-of-a who-is-who of highly respected mathematicians in the world, for instance Terence Tao widely famous math prodigy widely regarded as one of the greatest living mathematicians.
Enter our team, Jia Li, Yann Fleuret, and Hélène Evain. After a successful exit in a previous startup (that I happen to have know well when I was an IP lawyer in a previous life but that's for another story) they decided to co-found Numina as a non-profit to do open AI4Math.
Numina wanted to act as a counterpoint to AI math efforts like DeepMind's but in a much more open way with the goal to advance the use of AI in mathematics and make progress on hard, open problems. Along the way, they managed to recruit the help of some very impressive names in the AI+math world like Guillaume Lample, co-founder of Mistral or Stanislas Polu, formerly pushing math models at OpenAI.
As Jia was participating in the code-model BigCode collaboration with some Hugging Face folks, came the idea to collaborate and explore how well code models could be used for formal mathematics.
For context, olympiad math problems are extremely hard and the core of the issue is in the battle plan you draft to tackle each problem. A first focus of Numina was thus on creating high quality instruction Chain-of-Thought (CoT) data for competition-level mathematics. This CoT data has already been used to train models like DeepSeek Math, but is very rarely released so this dataset became an unvaluated ressource to tackle the challenges.
BigCode's lead Leandro put Jia in touch with the team that trained the Zephyr models at Hugging Face, namely, Lewis, Ed, Costa and Kashif with additional help from Roman and Ben and the goal became to have a go at training some strong models on the math and code data to tackle the first progress prize of AIMO.
And the trainings started:
Jia being an olympiad coach, was intimately familiar with the difficulty level of these competitions and able to curate an very strong internal validation set to enable model selection (Kaggle submissions are blind). While iterating on dataset construction, Lewis and Ed from Hugging Face focused on training the models and building the inference pipeline for the Kaggle submissions.
As often in competition it was an intense journey with Eureka and Aha moments pushing everyone further.
Lewis told me about a couple of them which totally blow my mind. A tech report is coming so this is just some "along the way" nuggets that will be soon gathered in a much more comprehensive recipe and report.
Learning to code: The submission of the team relied on self-consistency decoding (aka majority voting) to generate N candidates per problem and pick the most common solution. But initial models trained on the Numina data only scored around 13/50... they needed a better approach. They then saw the MuMath-Code paper (arxiv.org/abs/2405.07551) which showed you can combine CoT data with code data to get strong models. Jia was able to generate great code execution data from GPT-4 to enable the training of the initial models and get to impressive boost in performance.
Taming the variance: Another Ahah moment came at some point when a Kaggle member shared a notebook showing how DeepSeek models worked super well with code execution (the model breaks down the problem into steps and each step is run in Python to reason about the next one).
However, when the team tried this notebook they found this method had huge variance (the scores on Kaggle varied from 16/50 to 23/50).
When meeting in Paris for a hackathon to improve this issue (like the HF team often does) Ed had the idea to frame the majority voting as a "tree of thoughts" where you'd progressively grow and prune a tree of candidate solutions (arxiv.org/abs/2305.10601).
This had an impressive impact on the variance and enabled them to be much more confident in their submissions (which showed in how the model ended up performing extremely well on the test set versus the validation set)
Overcoming compute constraints: the Kaggle submissions had to run on 2xT4s in under 9h which is really hard because FA2 doesn't work and you can't use bfloat16 either. The team explored quantization methods like AWQ and GPTQ, finding that 8-bit quantization of a 7B model with GPTQ was best
Looking at the data: a large part of the focus was also on checking the GPT-4 datasets for quality (and fixing them) as they quickly discovered that GPT-4 was prone to hallucinations and failing to correctly interpret the code output. Fixing data issues in the final week led to a significant boost in performance.
Final push: The result were really amazing and the model climbed to the 1 place. And even more, while tying up for first place on the public, validation leaderboard (28 solved challenges versus 27 for the second place), it really shined when tested on the private, test leaderboard where it took a wide margin solving 29 challenges versus 22 for the second team.
As Terence Tao himself set it up, this is "higher than expected"
Maybe what's even more impressive about this competition, beside the level of math these models are already capable of is how ressource contraint the participants were actually, having to run inference in a short amont of time on T4 which only let us imagine how powerful these models will become in the coming months.
Time seem to be ripe for GenAI to have some impact in science and it's probably one of the most exciting thing AI will bring us in the coming 1-2 year. Accelerating human development and tackling all the real world problems science is able to tackle.




English

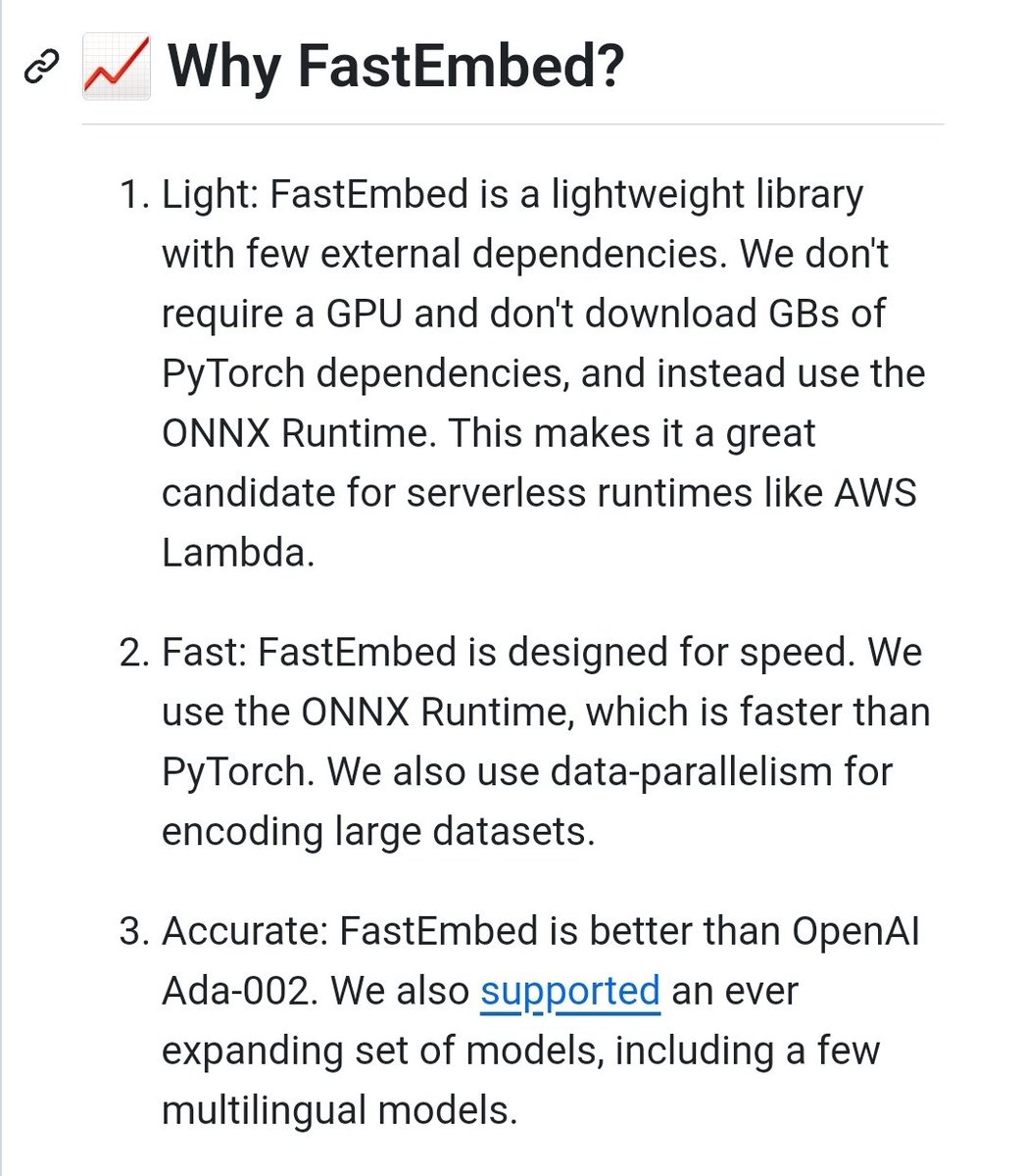
FastEmbed
Fast, Accurate, Lightweight Python library to make State of the Art Embedding
github.com/qdrant/fastemb…
English