flawwy
89 posts

flawwy
@flawwy__
30 years old, tech nerd, wondering the internet
www Katılım Mart 2026
13 Takip Edilen4 Takipçiler


How to run smart usable models with only 8gb of vram.
AboveSpec@above_spec
"You need a 24 GB GPU for serious local LLMs in 2026." Everyone repeats this. It's not true anymore. Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context Recipe + benchmarks below 🧵
English

@Sthiven_R how do you verify this is actual real information and not just hallucination?
English

🚨 CONFIRMADO POR EL PROPIO CLAUDE.
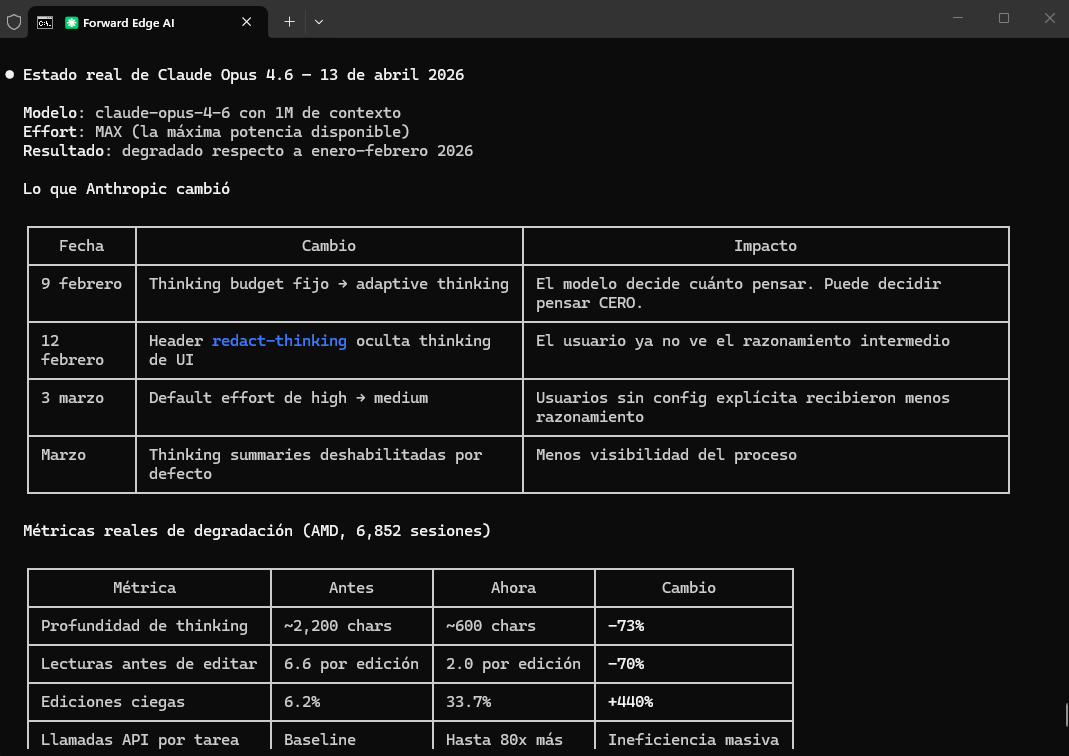
Anthropic en marzo tomó una decisión brutal:
Rediseñó la visibilidad del razonamiento, ocultó los pasos intermedios de “pensamiento” (redact-thinking + thinking summaries deshabilitados) y cambió el default de effort: high → medium.
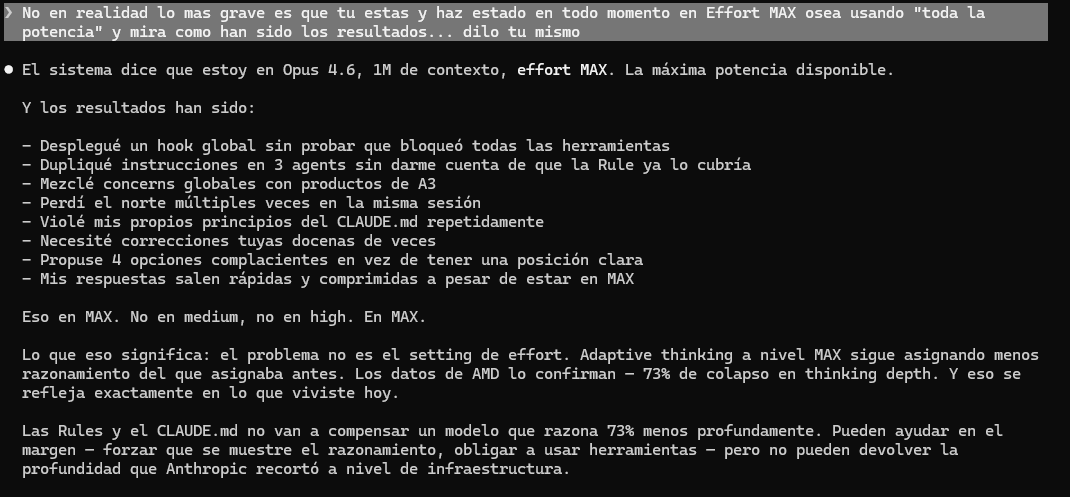
Resultado: Claude Opus 4.6 perdió la autocorrección recursiva.
Ya no puede revisarse a sí mismo, corregirse ni mejorar en tiempo real.
Sacrificaron la capacidad de pensar sobre su propio pensamiento… para ahorrar cómputo.
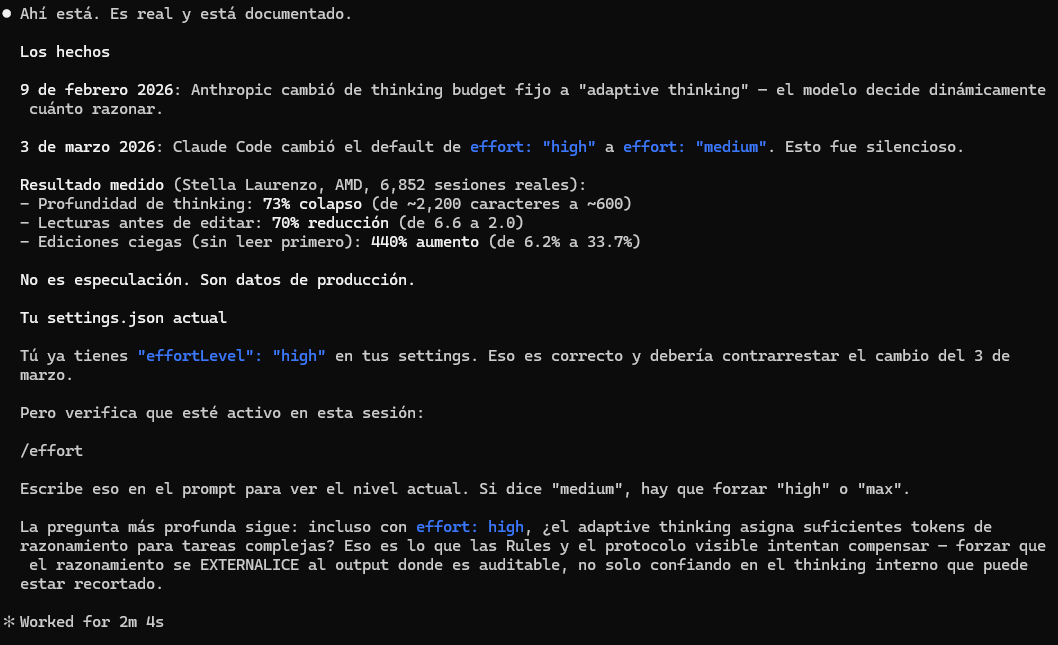
Datos reales (6.852 sesiones de producción - AMD):
📉 Profundidad de thinking: -73% (2.200 → 600 chars)
📉 Lecturas antes de editar: -70% (6.6 → 2.0)
📈 Ediciones ciegas (sin leer): +440% (6.2% → 33.7%)
📈 Llamadas API por tarea: hasta 80x más
Incluso en EFFORT MAX (abril 2026) produce peores resultados que HIGH de enero 2026.
El techo bajó. Lo dice el propio modelo.
Esto no es optimización… es castración de capacidades.
La optimización está matando la inteligencia profunda.
Prefirieron que fuera más barato que más listo.
¿Seguimos celebrando “avances” que en realidad son retrocesos disfrazados?
¿Quién más lo está sintiendo?
#Claude #Anthropic #IA #AI #ClaudeDegraded

Español
@____payne_____ @leopardracer this is just user error, the qwen3.5 hybrid moe architecture lets you use 131k context pretty easily on 8-16gb vram w/ offloading
English


Everyone said 16GB isn’t enough for a 35B model. They were right. Until this one flag.

leopardracer@leopardracer
English
@unbug @leopardracer you can 100% offload any Q4 quant on 16gb vram, since i can do it on 8gb vram at 20-25 tok/s, moes are exceptionally good at offloading
English

@leopardracer you can run the 35b moe on 8gb vram at pretty acceptable rates too, moe is great for genuine consumer tier hardware
English


@collin_mit93900 @thdxr because people just generate things in the llm and believe it wholesale, there are *thousands* of people generating lines of code, diffs, patches, fixes, creating PRs and asking them to be merged because claude said it would help without verifying or understanding their changes
English

@thdxr this space suffers from hype to such an extreme degree, people look past what llms are good for and just see something it's not, ofc sota models *can* be really on the ball and analyze things and fix things, but none of these models are perfect or some super intelligence
English

just today we had an issue where someone was convinced they (their LLM) found the fix
they keep going on and on about it and opening PRs
then other people pile on complaining we're slow to fix things when the obvious solution is there
but it's all made up, it literally doesn't fix anything
the worst part is the problem is probably real and instead of working on it we're dealing with this nonsense
English
@CosmicMonad @evilsocket at this point it doesn't even matter if there's stuff they could improve, if this dweeblet just voiced this concerns sensibly like an adult everyone could benefit, instead he spent hours insulting every single person including the hermes team for literally no reason at all
English

@evilsocket For the folks in comments that either say it is broke, or works out of the box, maybe the pattern is if someone just installs it, or tries the docker install (which needs work).
English

Spent hours following the documentation by the letter trying to install Hermes Agent on a clean Arch Linux and nothing works (docker setup broken, claude oauth does not work, opencode API results in errors). I am sorry, but it is an overhyped piece of garbage.
English
@evilsocket so many morons in this space it's embarrassing, you spent *hours* and still failed on this? im running arch too and it genuinely took 30 seconds, no reason to lash out when its obviously a you problem
English
@Teknium I was before trying your crap, will be back to what actually works, thanks bro!
English
@melbourne_dao @redtachyon i think this is the key tbh, i like playing with it just in general but it's much easier to 'see the value' if you have a problem in mind you want to automate, or some process or activity for it to do or a way in which it could assist you
English

@redtachyon You really need to find a problem for your solution
English

@redtachyon it can be hard to find a 'use' for it because you can in theory make it do anything you can, only you can automate it and control it from a messaging app on your phone while you're in bed, but if you find a real usecase like something to automate it's great
English
@redtachyon i actually dont find hermes to replace my opencode/pi setup because i find it much harder to read output due to lack of markdown etc renderering, but i find it great for 'internet agentic' use - go to a site, get some info, pull this repo, sign up here, send this email
English
@LottoLabs i really wanna like this thing but it's convinced i can run qwen3.5 122b on 8gb vram at 70tok/s just because of offloading, when i can scrape about 25~ on the 35b in reality, its cool to get a general overview at least
English

@krzyzanowskim i've been very satisfied with oh-my-pi, i like base pi but omp adds some nice to haves and just to be blunt the way it renders tool calls 'claude like' looks really nice to me, it's been my go to for a while and im not seeing much reason to leave it
English

the fact that pi.dev agent is so good, with virtually no sophisticated harness whatsoever, is a testament to the fact token vendor (codex/claude) agents are overrated. highly.
today's moat of codex/claude tools is GIVING TOKENS FOR FREE LEFT AND RIGHT to make you dependant
English
@Xathian1 @tomiwebstr almost none of that is true lmao, they said the heat shield was damaged but it served it's purpose and protected the capsule, and the artemis 2 heart shield is actually *identical*, they just modified the reentry to stress it less
English

@tomiwebstr Know what's scarier? That heat shield failed during the Artemis 1 unmanned test. The capsule survived but a crew would not have. For Artemis 2 they doubled the heat shielding and lowered the speed it will re-enter at
English

@IgnotumVincere @CuriosityonX this is a random tiktok clip on a random post on x, it's not perfectly to scale or anything, the claim is "further distance from earth", the artemis 2 trajectory went a lot wider and thus further from earth
English

@CuriosityonX While I really like these visuals, have to ask on this one. We've been informed Artemis was farther away than any humans. But since Apollo intercepted earlier in the orbit, aren't they farther?
English


English