Sabitlenmiş Tweet
Finn Busch
22 posts

Finn Busch
@fnnBsch
PhD Student in Robotics/Computer Science at KTH Royal Institute of Technology
Katılım Ekim 2021
423 Takip Edilen21 Takipçiler
@iamgrigorev Same here for vision tasks. Notice a small hit on training throughput, would you share the kernel?
English

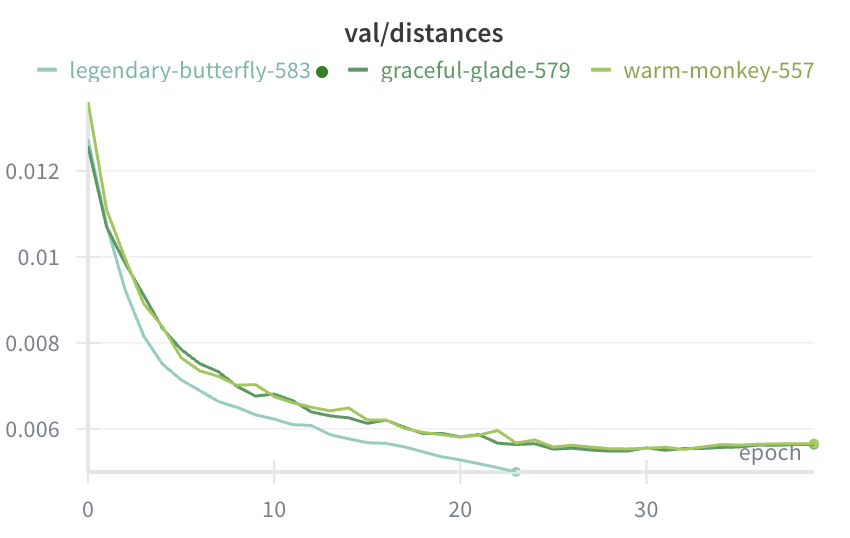
Wow, Cautious Weight Decay actually works.
If done non-carefully it increases step time, since cautious mask = p * v >= 0 and effective weight decay is now per-parameter (we apply WD when param and update directions match).
Benefit in the end of training is small, but still nice.

English
@maharshii Interesting, this is related to your earlier tweet right? Does this also mean no matter if it is dynamic=True or False, the int/float Inputs will not be compiled into the kernel and you can change them at runtime?
English

thank me later: when you have a function like below which uses float/int arguments, then by default torch will create guards around it that uses _as_tensor_fullprec to convert the float/int to a tensor with full precision i.e. int64 or float64 which can increase the dynamo cache lookup time by a lot when executing the compiled function. this can be easily mitigated by setting specialize_int and specialize_float to True in dynamo config.



English

@CrichaelMawshaw @gowerrobert Interesting, we've been running the moonshot MUON + AdamW setup for vision tasks with shared LR. This seemed better than plan AdamW. Would be interesting to into varying coeffs for our application
English

@fnnBsch @gowerrobert I like the Moonshot trick, but I wanted to benchmark the sensitivity w.r.t both LRs. I'm not 100% sure the trick works universally: maybe we have to tune their 0.2 coeff for different setups? and then we're back to tuning 2 hyperparams. I'd be curious to see someone dig into it.
English

We've just finished some work on improving the sensitivity of Muon to the learning rate, and exploring a lot of design choices. If you want to see how we did this, follow me ....1/x (Work lead by the amazing @CrichaelMawshaw)

English
@gowerrobert @CrichaelMawshaw I think so, see p.4 in the report ("Muon can directly reuse the learning rate and weight decay tuned for AdamW") and Appendix A. It seems that the RMS relationship is quite straightforward. Chances are the LR setup you found to work best is in the same ballpark?
English
@fnnBsch @CrichaelMawshaw We tuned the two lrs of the Adam and muon layers separately for all methods. Does the moonshot scaling really allow for one shared lr for Adam and muon ? I didn’t know that, and that would be great if it’s true. It made a big difference tuning both lrs for us
English
@drisspg More control over memory/performance trade-off + documentation. Been using activation checkpointing + compile but realized I can get much more performance without checkpointing but by setting the activation memory budget in compile. Would be nice to have even more control there
English

Do you use PyTorch? Do you care about its performance both eager and compile?
If so, what do you think is missing? What features would you like to see? What are you biggest pain points? Its almost planning season and I want to know what you think!
English
@KBlueleaf Ah, I see. Might give it a shot then, been using bf16, but mostly because it was faster and I could avoid gradScaler which (in pytorch) requires GPU-CPU-sync irrc
English

@fnnBsch I only do supervised learning
Or, self supervised (Autoregressive, diffusion)
So in my view the thing is "fp16 already works in sl and ppl also found it is useful in rl"
English
That's why I always using FP16 in almost all of my training
Yes, you need grad scalar or very carefully designed arch to ensure the value range will not exceed the fp16 5bit exponent, BUT, if your value range will exceed the range, BF16 actually have not much precision there to express what you need
There are also some FP8 quantization paper (mostly from qualcomm XD) provide evidance that more mantissa is better than more exponent
I will not say integer is what we need as FP have it's own advantage, but when your "free lunch" is just for you to "pretend your design have no numerical instability" than you will get punished by it.
(BTW, I previously think ppl will finally notice BF16 is not always "free" when they start using stochastic rounding or accumulated update in optimizer, but looks like ppl still think doing those process is better than grad scalar)
wh@nrehiew_
Is this what a free lunch looks like?
English
@KBlueleaf Thanks - do you think the extra precision of fp16 vs bf16 is mostly relevant for RL, or same for supervised training?
English
It is hard to list specific techniques.
But I will recommend you to check how those ppl make fp8/fp4 training works.
Lot of technique actually works on fp16 AMP training as well.
For full fp16, grad scalar + optional external fp32 scale for grad + compute optimizer step in fp32 is 100% enough
Lot of times you even just need grad scalar + fp32 opt (opt state can be fp16)
English
Paper, Code, Video: finnbsch.github.io/OneMap
Accepted to ICRA 2025 @ieee_ras_icra
English

Hi, we're doing giveaway number next.
We're going to do something a little crazy. We're going to give 1 person $1,000 in BTC.
If you'd like $1,000, leave a comment below.
- Winners will be selected randomly in the next 24 hours.
- We will DM winners.
- If you do not confirm your win in 24 hours a new winner will be selected
- If your DMs are closed, you automatically forfeit your prize
English
@ludwig_stumpp @AlbyHojel Yup
It would be interesting to do the same for indoors, could be very helpful to find a good location for WiFi repeaters
But then localization becomes difficult
English

@fnnBsch @AlbyHojel Yes, you are right, thanks for looking. Did not have time this morning. First thought that this is an issue as I don't have GPS on my laptop however the Readme describes a straightforward setup with phone GPS.
English

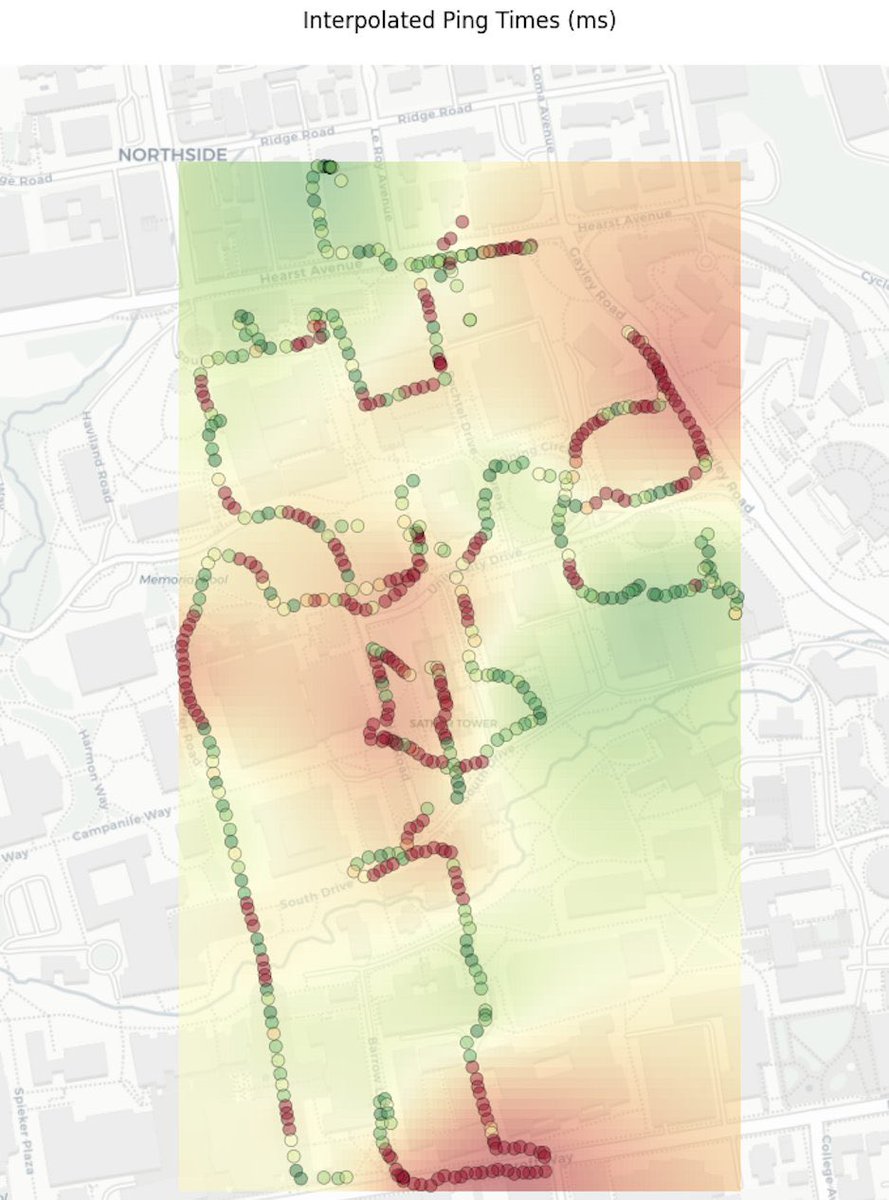
Build your own WiFi connectivity maps with this simple python script!
Run the script and just walk around!
Repo link below 👇

English
English
@AlbyHojel Does this perform localization as well? If so, do you want to summarize how the localization works? I believe many here would be interested in knowing.
English

Sonnet 3.6 tries to make a redstone powered door.
It kinda got it right, but wasted a button on the wrong placement.
Still impressive since no other models can do this reliably.
Dazai@odazai_
@adonis_singh these are really cool! I'm curious how they would do if you asked them to create redstone circuits. like "create a 2x2 piston door" and see if they're able to put together something that actually works
English
@RomanHauksson Ah, so sorry, I didn't check carefully - I wasn't aware of that, might actually change it to yours now that I looked at it more carefully :)
English

@fnnBsch Thanks! It looks like your site is made using Eliahu Horwitz’s template, which mine is adapted from but pretty much totally rewritten using Astro and markdown instead of Jekyll.
English
A reminder that I made a template for ML research project pages!
It uses modern web dev technologies like Tailwind CSS and Astro, and it's easier to use than forking the Nerfies website. (1/4)

English
@nellstra Yeah, I totally agree. It's easy to neglect taking time for these things when there's so much work to do :D I'll try, will tweet some pictures then
English
@nellstra Man I came to the US/Berkeley a few months ago and a week worth of your tweets make me feel I have not seen enough of this area at all
Great pictures though
English