Franck Mercado retweetledi

Franck Mercado
4.1K posts


@franckmercado
Passionate about Software Architecture & Design, DDD, Ports & Adapters, API Dev, Testing and now EDA (;

Computer use with any model Hermes Agent × @trycua




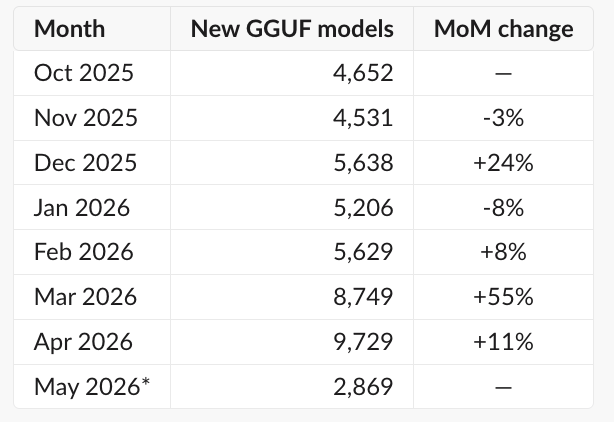
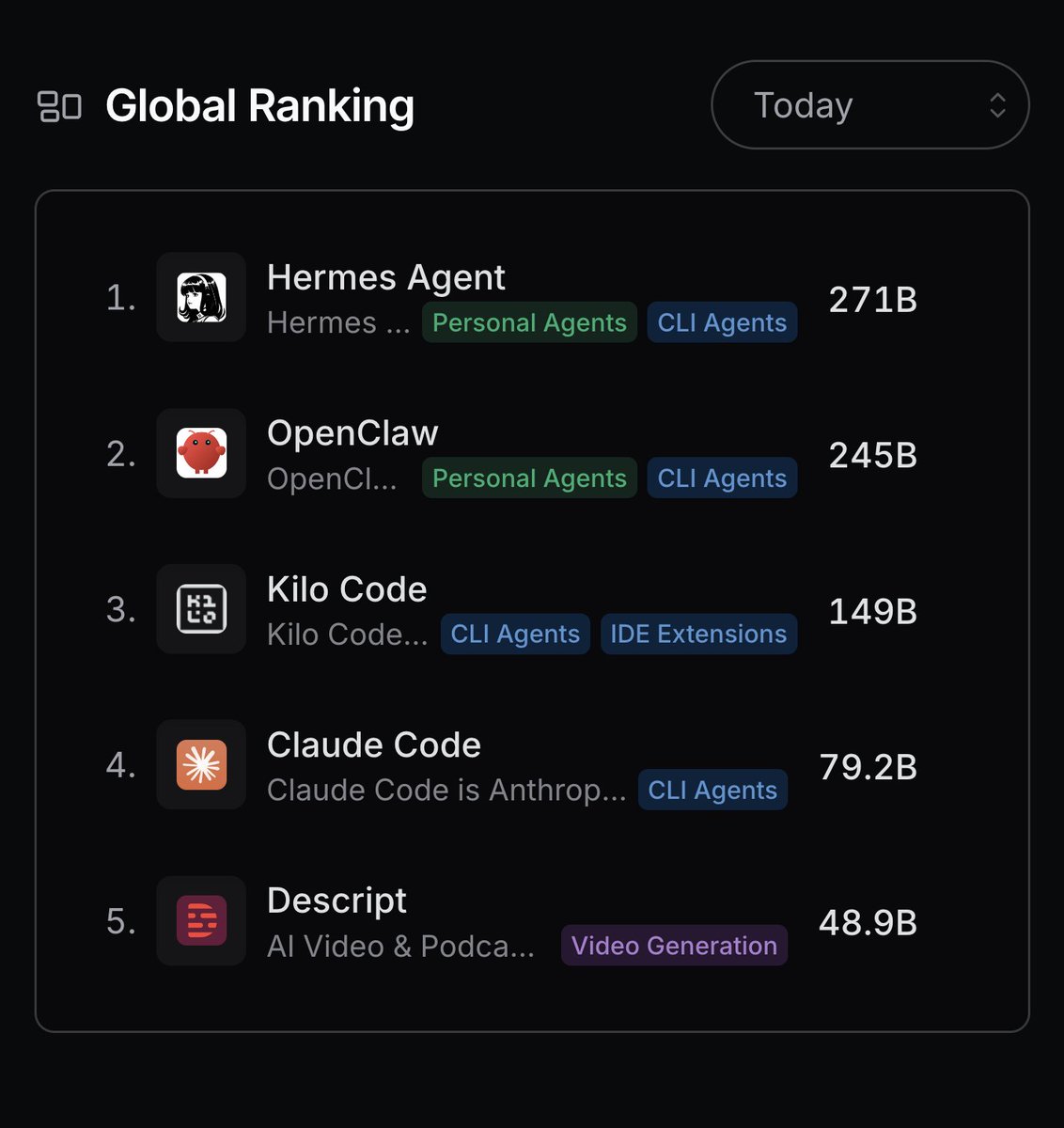


Counting down to 100,000 stars… Hermes Agent FTW






@TheAhmadOsman What is your opinion of OpenClaw on a Mac Mini (‘I can unplug it’) versus on a server instance?




