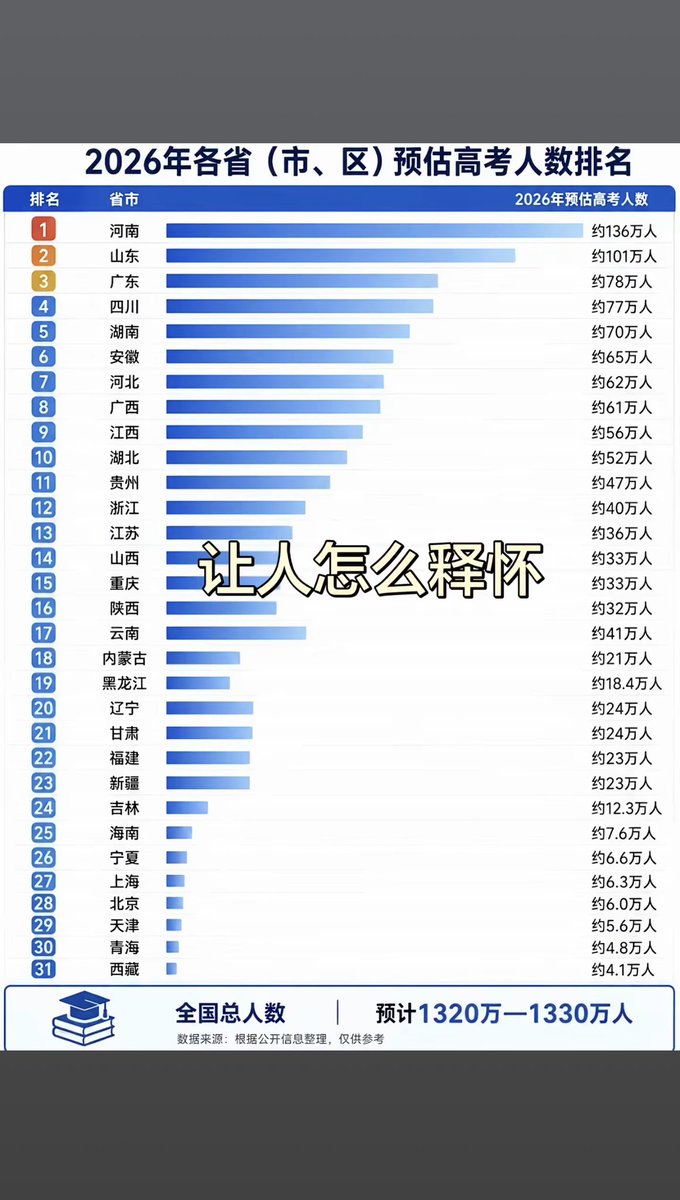
Sabitlenmiş Tweet

人的时间和注意力都是有限的,关注 AI 不能平均用力。
我觉得更好的方式是:重点关注真正产生一手变化的人和组织。
一类是 OpenAI、Anthropic、Google DeepMind/Gemini 这类前沿公司,它们往往决定模型能力、产品形态和行业议题的方向。
一类是 DeepSeek、Qwen、Llama、Mistral 这类开源或更开放的阵营,它们分享更充分,也更容易让人理解技术路径和真实可用性。
同时也要关注一线研究员、工程师、开发者社区,而不是只看媒体解读和KOL情绪。
AI 信息太多,真正重要的不是每天刷新闻,而是建立自己的过滤系统:少看噪音,多看一手材料;少追热点,多追能力如何迁移到真实工作流。
中文