Andrey Vasnetsov retweetledi

⚡ miniCOIL: a lightweight sparse neural retriever capable of generalization
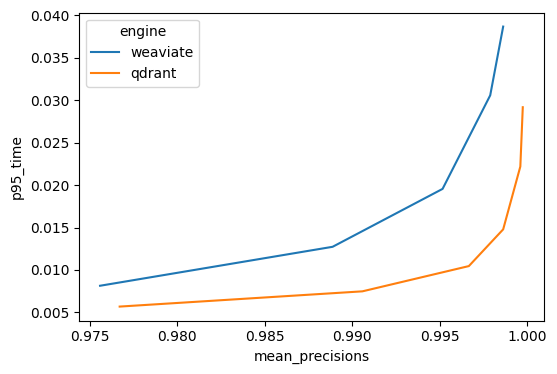
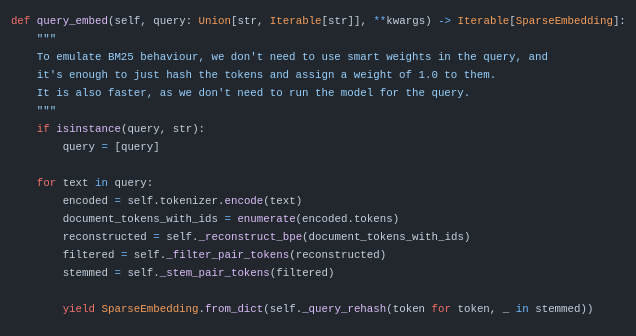
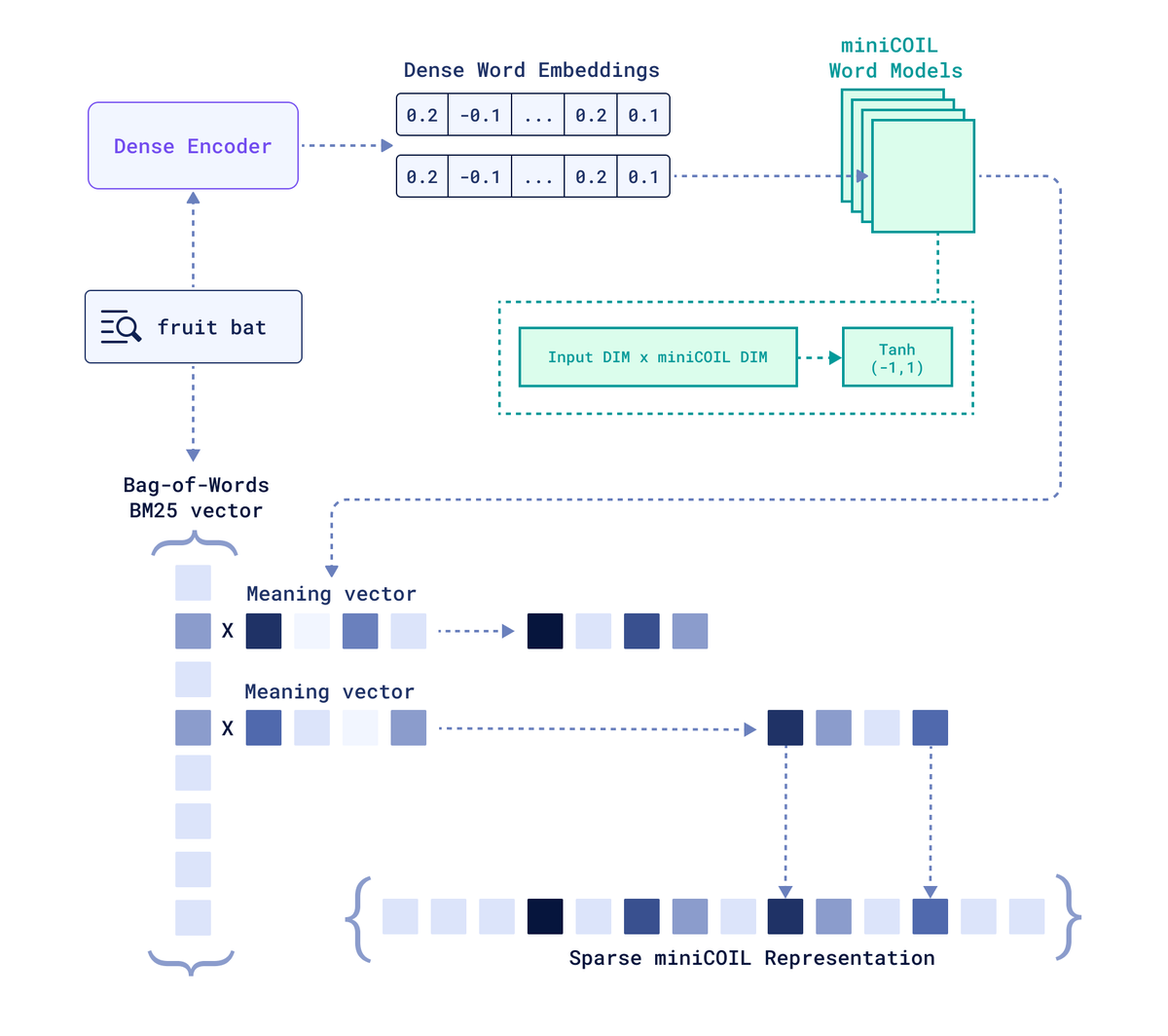
Sparse Neural Retrieval holds excellent potential, making term-based retrieval semantically aware.
The issue is that most modern sparse neural retrievers rely heavily on document expansion (making inference heavy) or perform poorly out of domain.
❗️🧵 We present our latest attempt to make sparse neural retrieval usable.
English