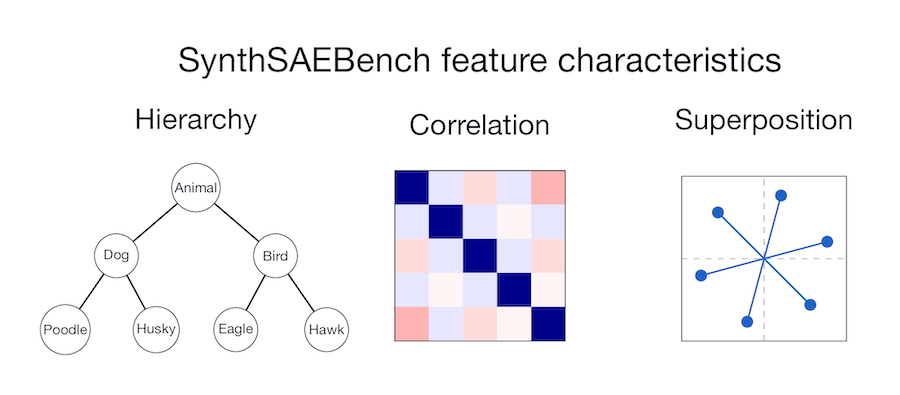
Sabitlenmiş Tweet

My data viz image was picked for a cover of the Jan 2024 issue of the Nat Comput Sci journal 😋
Nature Computational Science@NatComputSci
📢Our January issue is now live! Highlights include a model for predicting life outcomes, a Perspective on the advantages of language models for quantum simulation, and a protein language model for signal peptide prediction. 👉nature.com/natcomputsci/v…
English