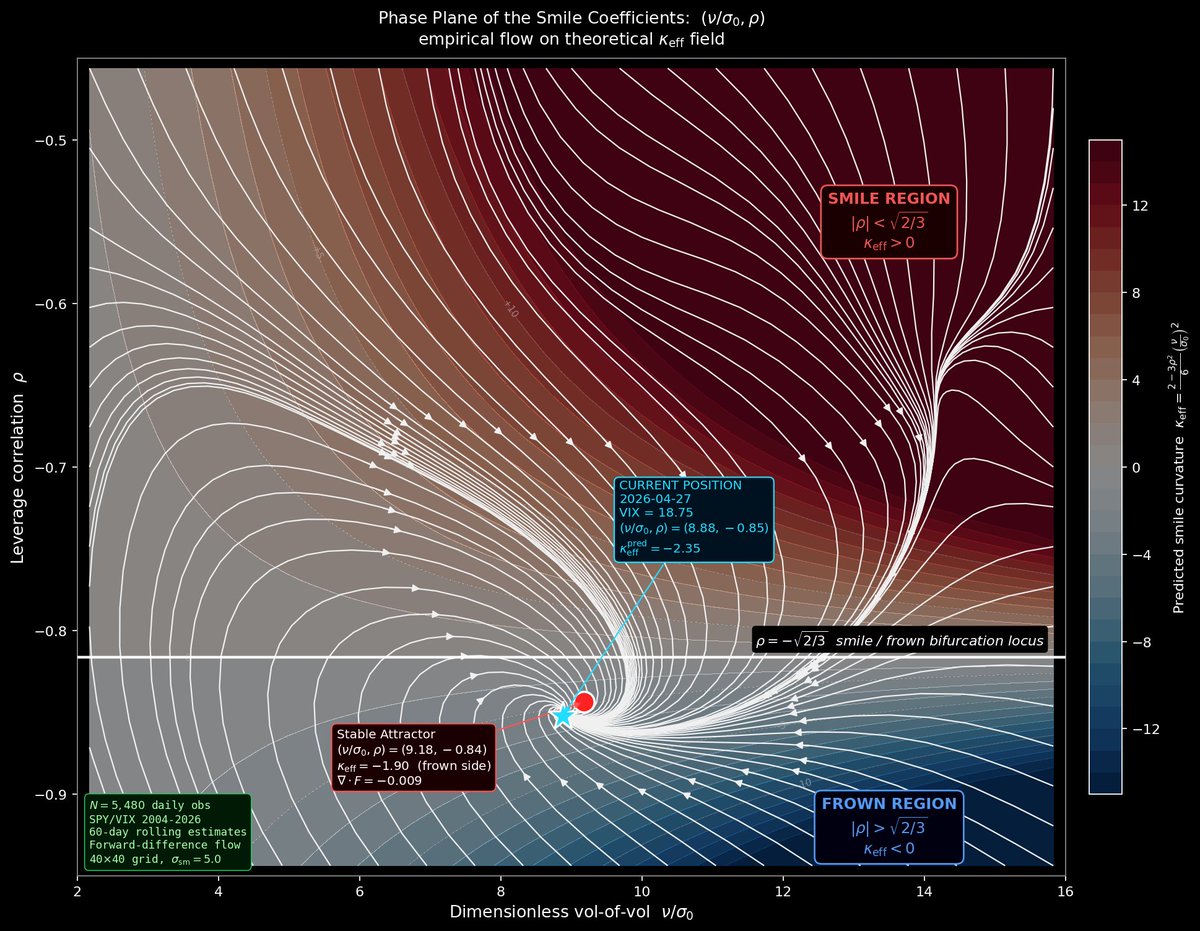
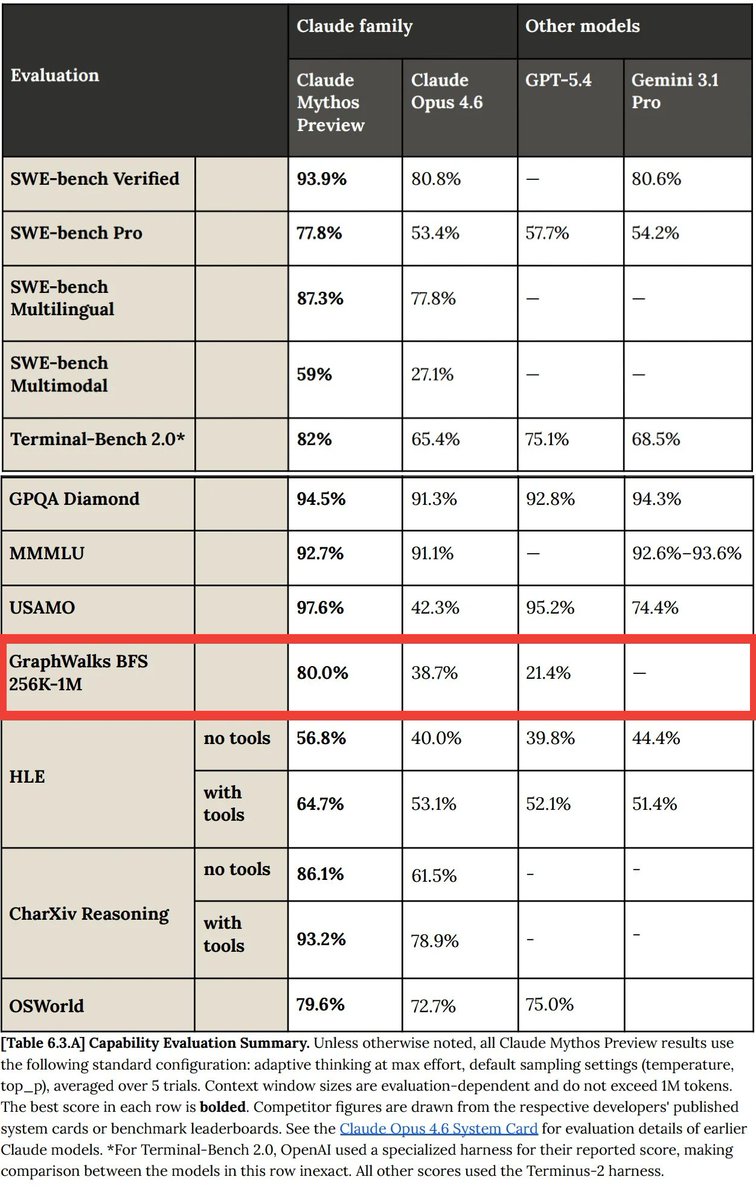
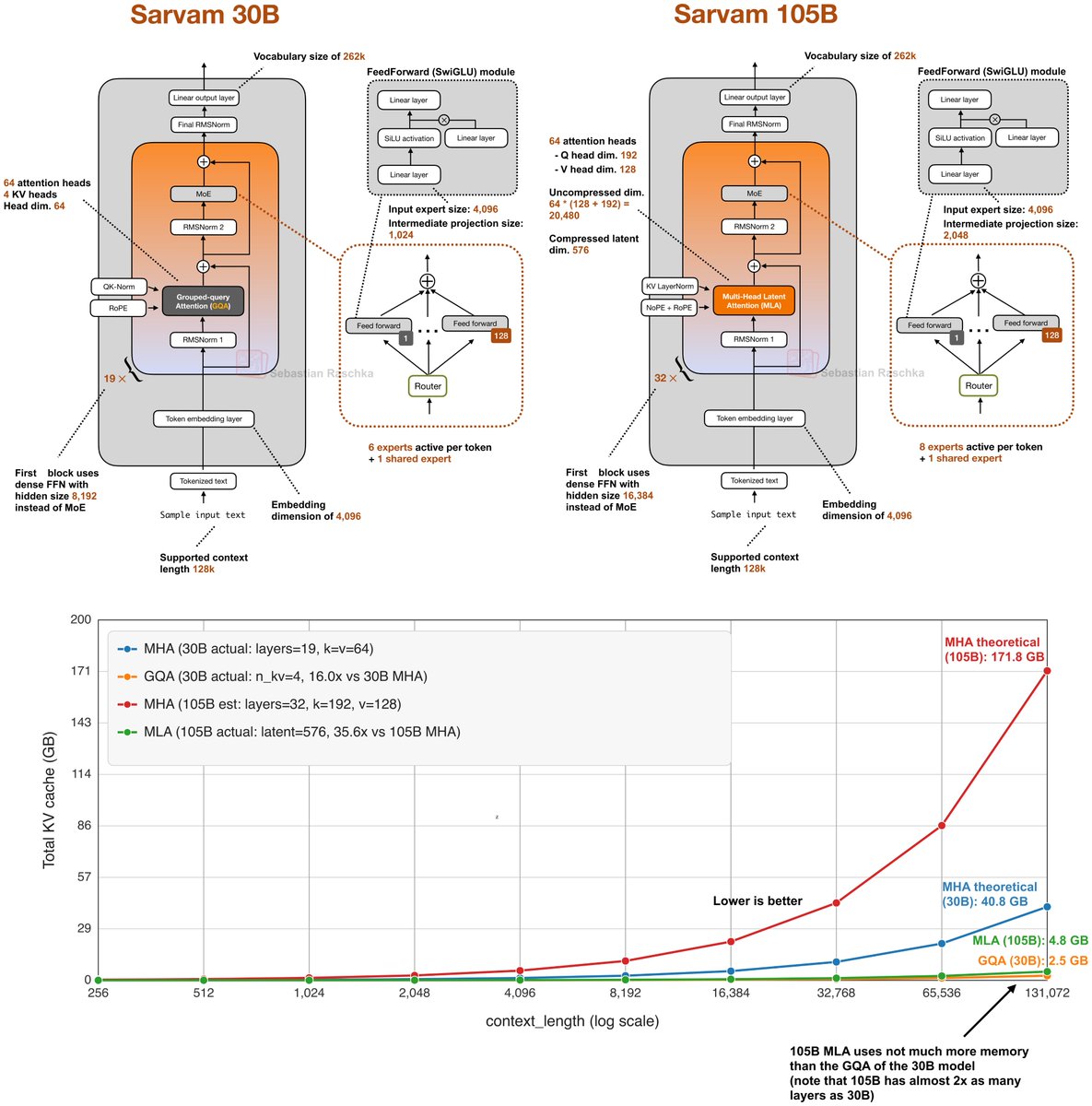
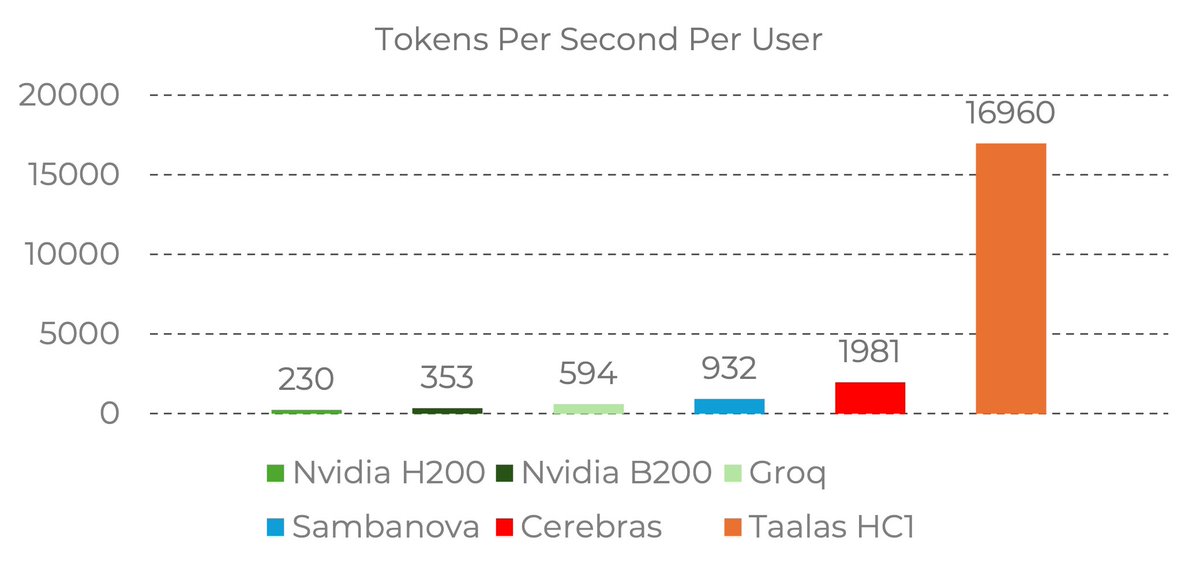
Z.ai@Zai_org
We’re officially public. (HKEX: 02513)
To everyone who has supported GLM, built with it, tested it, or simply followed along. Thank you.❤️
This moment belongs to our community as much as it belongs to us.
To celebrate, we’re opening a 48-hour community challenge.❤️🔥❤️🔥❤️🔥
48 hours. A few ways to join!
💬 Comment challenge
Every 12 hours, we’ll select the top 25 comments by likes. Each will receive $50 in credits.
🔁 Repost challenge
Every 24 hours, we’ll select the top 13 reposts by likes. Each will receive $200 in credits.
⭐ Editor’s picks
Some of the most interesting ideas don’t always get the most likes. We’ll be reading closely and highlighting thoughtful, original developer posts.
If your post is selected, Lou @louszbd will reach out personally with an exclusive developer gift pack.🎁
We’ll wrap up in 48 hours. All rewards will be sent within 72 hours after the challenge ends.
Let’s celebrate! 🎉
👉z.ai/subscribe?utm_…