
@Alibaba_Qwen @arena Yes if you actually going to release weights for 397b variant! This is what I am still running at home but stuck on 3.5
English
Chris Scott
292 posts

@greatscottdev
Software Engineer | LLM hobbyist | Problem Solver

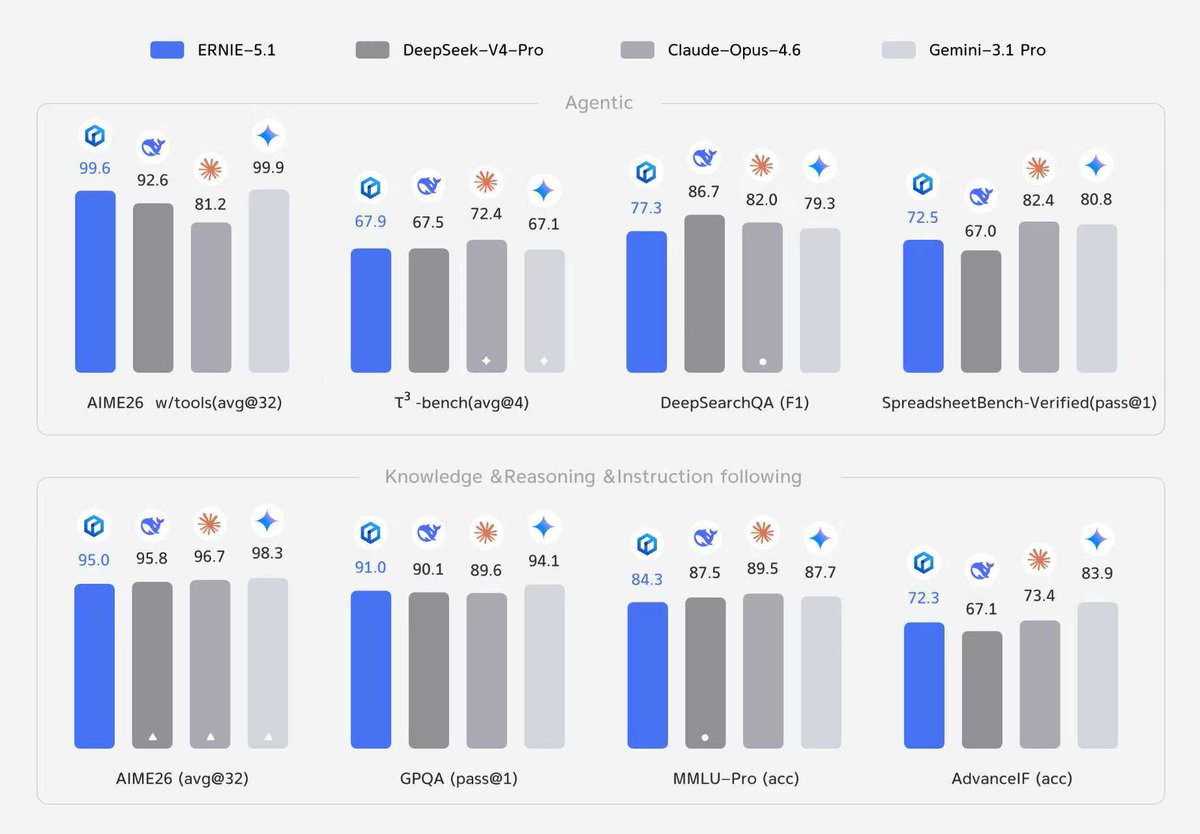
Qwen3.7 Preview By @Alibaba_Qwen lands on Arena for Text and Vision. In Text Arena, Qwen3.7 Max Preview ranks #13 overall. Alibaba is now the #6 lab in this arena. - #7 Math - #9 Expert - #9 Software & IT - #10 Coding In Vision Arena: Qwen3.7 Plus Preview ranks #16 overall, making Alibaba the #5 lab. Congrats to the @Alibaba_Qwen team on the latest progress!



Join us next week as @code_barbarian teaches us how to work with data in @remix_run 3 and what really matters! Join me at Working with Data in Remix 3: What Actually Matters | Remix Miami meetu.ps/e/Q1D3G/LpYmM/i luma.com/u6a3zdv3







Introducing TokenSpeed, a speed-of-light LLM inference engine. > TensorRT LLM level performance > vLLM level usability > Built by a lean and mission-driven team in two months > MIT license, open-source github.com/lightseekorg/t… lightseek.org/blog/lightseek…


Be honest, which is the best open source AI Model?


Warp is now open-source.








