
Ben
87 posts
@riteshmjn The narrative sounds plausible.
But i believe you give too much credit to people's memory and ability to learn from circumstances.
Energy , Infra, Defence - all could go down with few changes only
- Trump no more
- Democrats win midterms
- AI fails to dent firms productivity
English

We are living through a decisive moment in global markets. One chokepoint, the Strait of Hormuz, now sits at the center of everything that matters: energy, capital flows, and the future of the global order. If it holds, the current order persists. If it doesn’t, global markets will have to reprice. You don’t need certainty in moments like this, you need a framework. Watch the Strait. Watch the gold price. Watch the long end of the US yield curve. Everything else is noise.
Read the full article here: open.substack.com/pub/pinetreema…
English
@jamwt as @TheAhmadOsman says use MOE for unified memory.
For dense models get GPU
English

gemma 4 31B does indeed run on this MBP M5 Max (128GB), but boy is it slow.
opus is safe for now
English

I think many Indian journos don't know that CNN, while acting like opposing Trump and the war, works for the Pentagon and the CIA helping set and shape narrative in this war for the left in the US, and around the world.
To keep that left side in line, to keep them assured of Trump losing the war, and keep them entertained and not revolt.
All American media are part of the war and work for the US. They create narratives to distract and delude the enemy and the world.
Hope Indian media people learn from the Americans on how to support the country in times of war. And more importantly, how to effectively run narratives even on the other side.
Right now, what Jake did was repeat what Trump said and take it to the left which will otherwise won't be reading or hearing Trump.
He's acting as a medium normalizing Trump's words and threats among the left and those opposed to the war watching CNN.

English
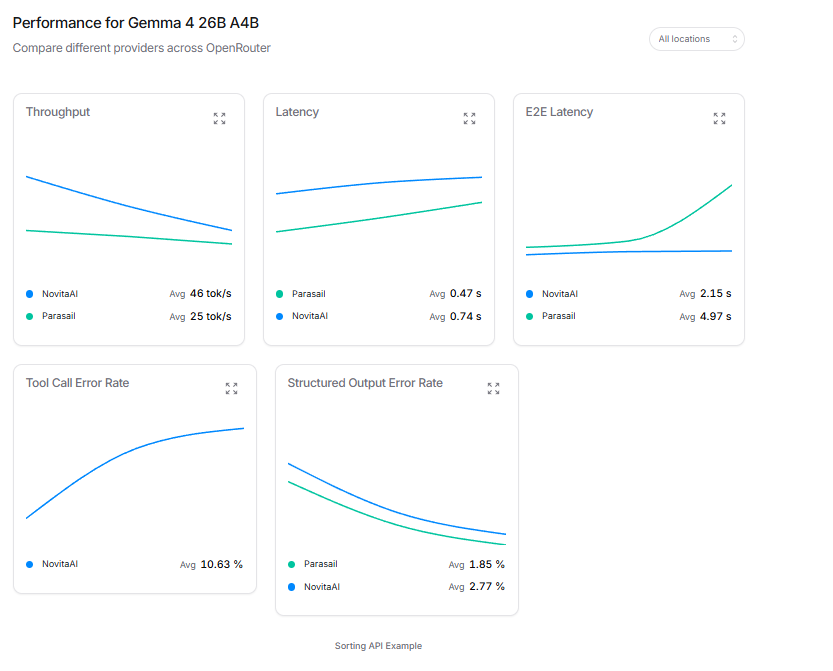
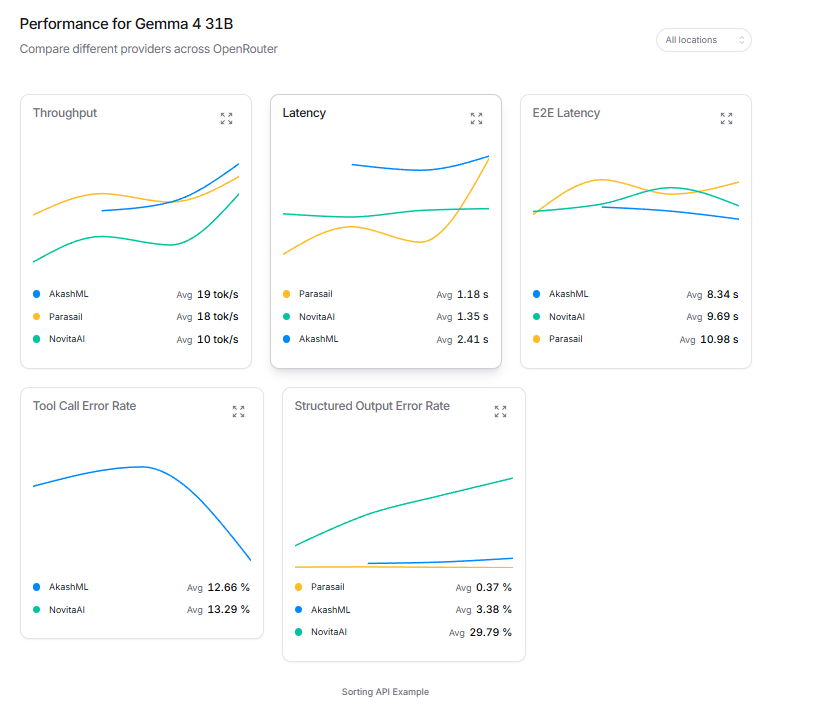

Gemma 4 is a very good small model that punches above it's weight class
Gemma is a 31B model that is as good as other very large MoE models
It's the best in the world for it's size 👏👏

English
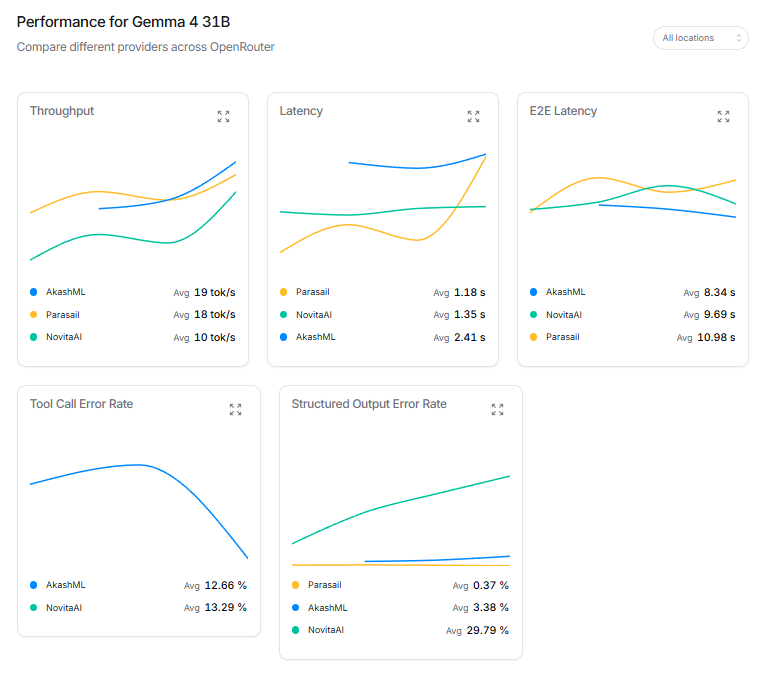
@GlennCameronjr @huggingface Please check why Gemma 4 has such high levels of tool call failures on openrouter. Get it corrected or provide document to use them correctly else people will loose faith in these models.

English


@aakashgupta You need to have 2 identities. One which posts on AI and another which posts on everything else.
Earlier i used to like your AI posts, now you are posting so much stuff which is competing with AI.
You will start loosing followers, unless you create 2 identifies
English

To get all my takes without an algorithmic filter, subscribe to my newsletter:
aibyaakash.com
English
Every one of those crosses required someone to map out which exact offices needed their lights on and which needed them off, floor by floor, window by window, across multiple skyscrapers simultaneously.
No software. No automated lighting systems. No building management platforms. A facilities manager with a paper grid telling tenants on the 40th floor to leave their lights on and tenants on the 41st to turn theirs off. Each cross spans 15-20 floors. Hundreds of individual offices coordinating binary on/off decisions to produce a single image visible only from miles away.
The people making it happen couldn't even see the result from inside the building. They were trusting a plan on paper.
Today those same buildings wouldn't do this. Not because the logistics are hard. Because the congregations are gone. About 50 churches close permanently across the US every week. In Brooklyn alone, more than 20 historic churches have been converted to luxury condos in the past two decades. The Archdiocese of New York deconsecrated 12 Manhattan and Bronx churches in a single batch. A former Pentecostal church in Greenpoint is now three loft-style condos starting at $2.5M. A 96-year-old Catholic church in the East Village was demolished to build 82 condo units.
In 1956, skyscrapers formed crosses for a city that believed. In 2026, the churches themselves are becoming $6,500/month rentals.
James Lucas@JamesLucasIT
This was New York City on Good Friday in 1956
English
@LukeGromen Does not make sense.
Printing $ will not solve an energy crisis.
Everyone adjusting their lifestyle to use lesser energy is the only way out.
Till the time other energy sources come up.
Overall living standards go down except for remaining energy producers
English

How much of your savings would you sell to feed your family & pay your mortgage if you lost your job while food, electricity, & heating costs soared?
You would sell all of it, & so will the world…
…& the world has $70tn of “savings” (gross; $27tn net), mostly in USD assets👇

English


GitHub powers your code, but it can also power your daily life. 🔋
Instead of downloading another productivity app, manage your tasks right where you already work:
✅ Issues for chores and bills
🏷️ Labels for priority and status
📊 Projects for your daily schedule
Here’s how to set up your personal operating system. 👇
github.com/social-impact/…
English


@icanvardar Very true.
Code and RAG based projects have succeeded till now.
Else its a slow grind to automate with AI in large corporates.
Just look at no code, low code, even they have been utter failures.
CFOs are excited now, but they are going to learn a bitter lesson in few yrs
English

ai isn't truly transforming any sector outside of software
English


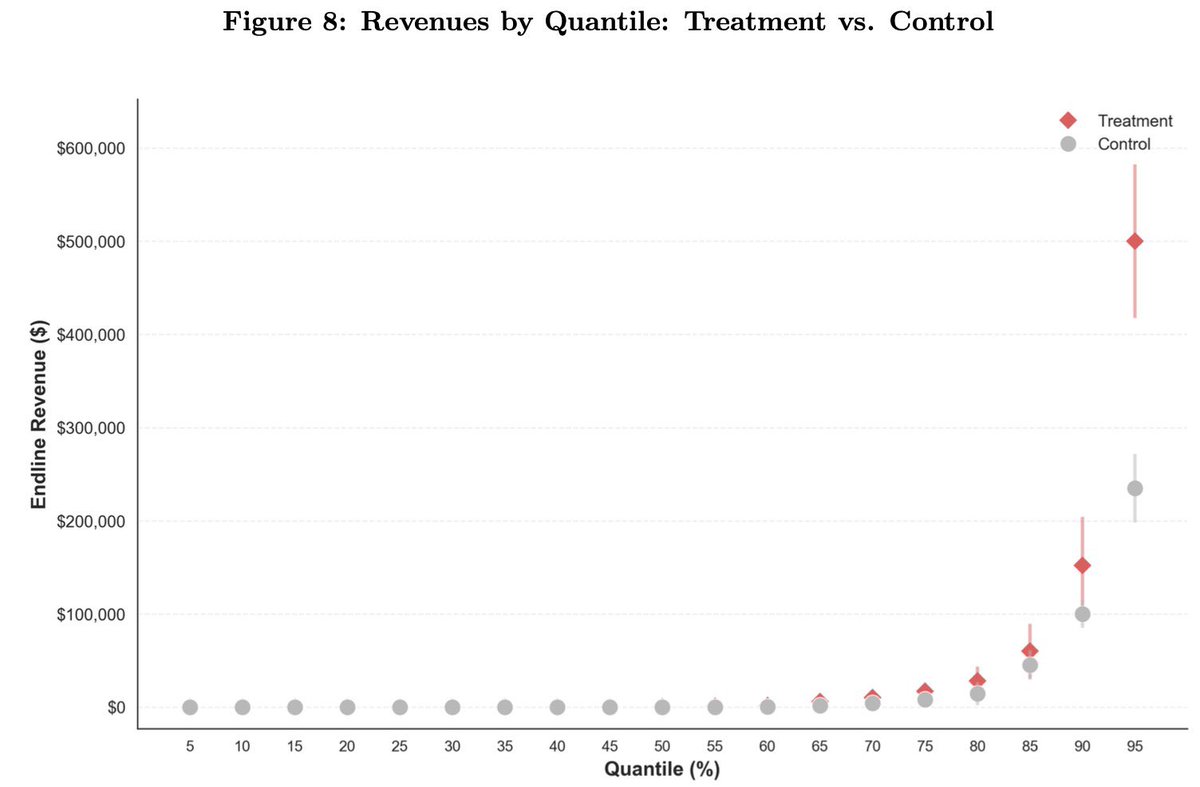
Check out our new paper on "Mapping AI into Production"
Our RCT with 515 startups shows AI already meaningfully improves firm outcomes/performance/productivity BUT founders/managers must learn to reorganize around AI.
Hyunjin Kim@hyunjinvkim
🚨 Excited to share a new working paper! 🚨 AI can improve individual tasks. But when does it improve firm performance? Our paper proposes one key friction firms face: the "mapping problem" -- discovering where and how AI creates value in a firm's production process. 🧵1/
English


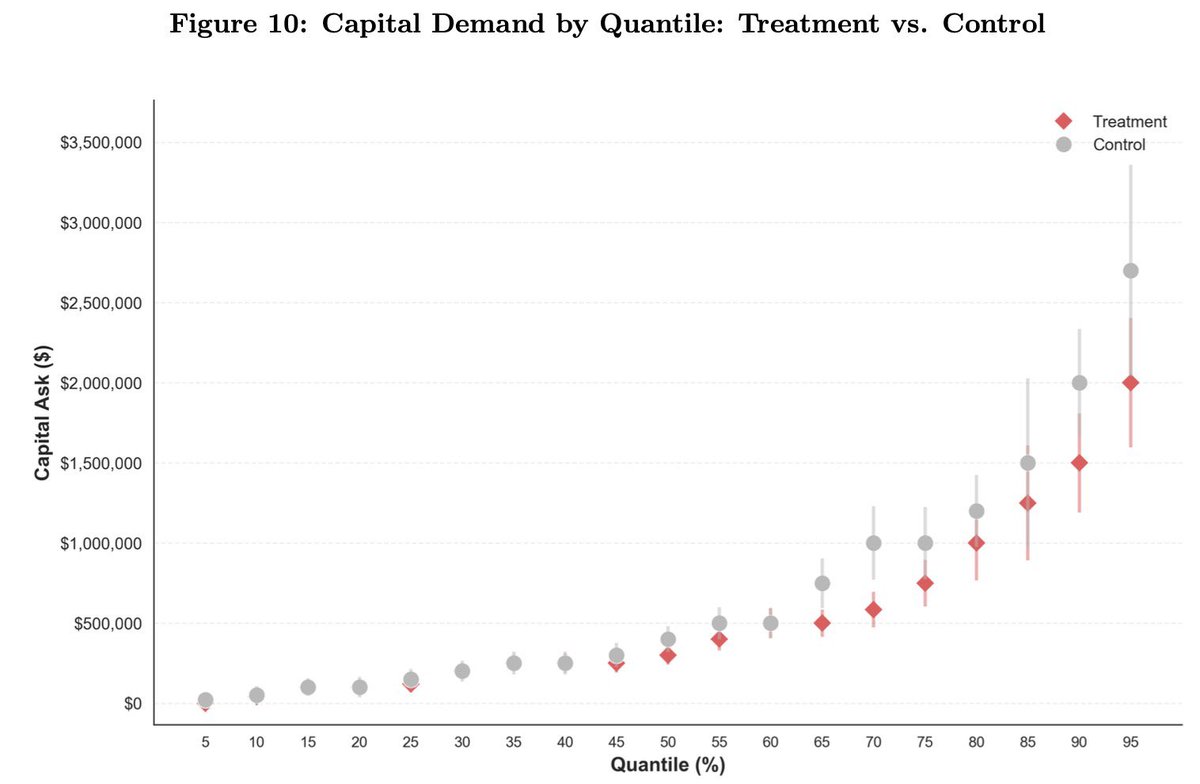
Big deal paper here: field experiment on 515 startups, half shown case studies of how startups are successfully using AI.
Those firms used AI 44% more, had 1.9x higher revenue, needed 39% less capital:
1) AI accelerates businesses
2) The challenge is understanding how to use it
Hyunjin Kim@hyunjinvkim
🚨 Excited to share a new working paper! 🚨 AI can improve individual tasks. But when does it improve firm performance? Our paper proposes one key friction firms face: the "mapping problem" -- discovering where and how AI creates value in a firm's production process. 🧵1/
English
@MatthewBerman The dependency details seem interesting for humans also.
I always face issues in installing skills or tools on my debian VM but pre-installing dependencies removes most issues.
English

I built something...
journeykits.ai
Journey helps agents discover and install full workflows easily.
Please leave your feedback below!
English
Ben retweetledi

@karpathy @trainable_nick Agents waste lots of token solving issues individually that can be solved by a good software engineer and distributed for everyone to use.
Would be good if such tools can be packaged and distributed for Hermes. Maybe some one is already on it.
English

@trainable_nick The best epub to txt converter I found is just asking your favorite agent to do it. Epubs can be very diverse, the agent just goes in, figures it out, creates the output markdown and ensures it looks good works great.
English

As I pulled on the thread from Karpathy’s post, I realized the existing EPUB → TXT tools were still too ugly and clunky for turning DRM-free books into clean markdown.
So I made my own.
I’ve only been vibe coding for a few months, and this is my first App Store Connect submission. Feels like a small milestone, but an exciting one.
Grateful for this moment... we get to build better and faster than ever.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English