Sabitlenmiş Tweet

Here is some news I'm happy to share before the @iclr_conf FOMO really starts to set in 😢.
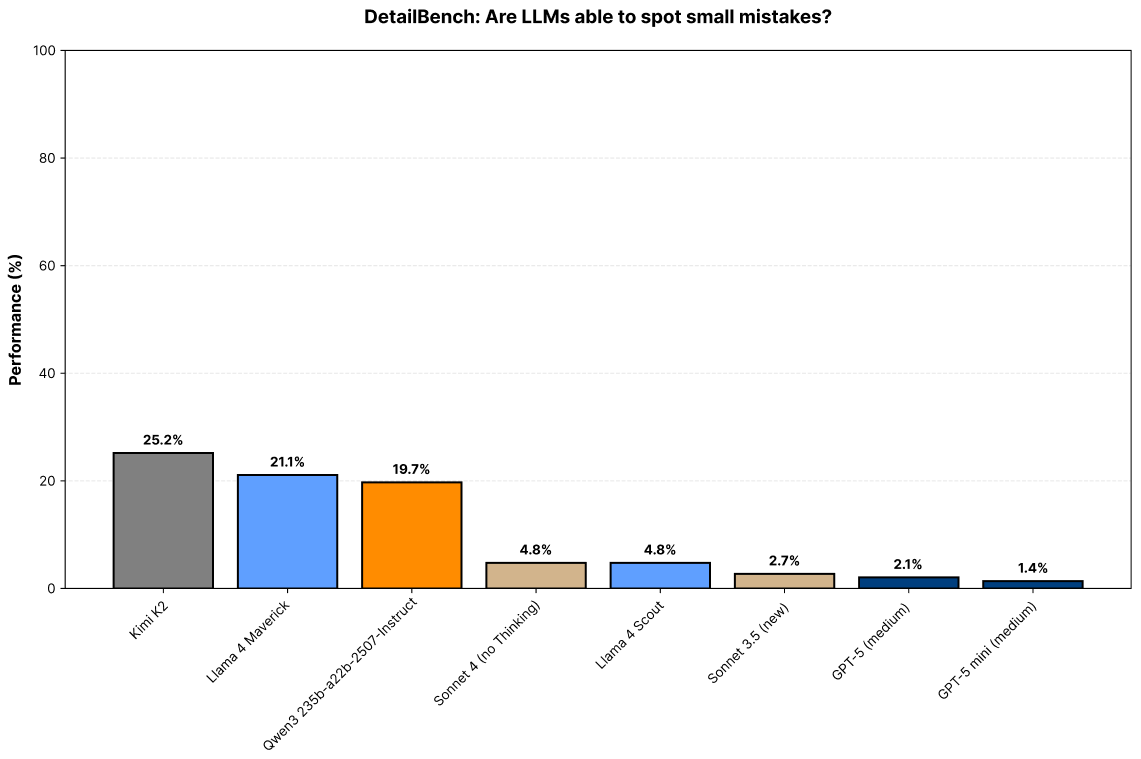
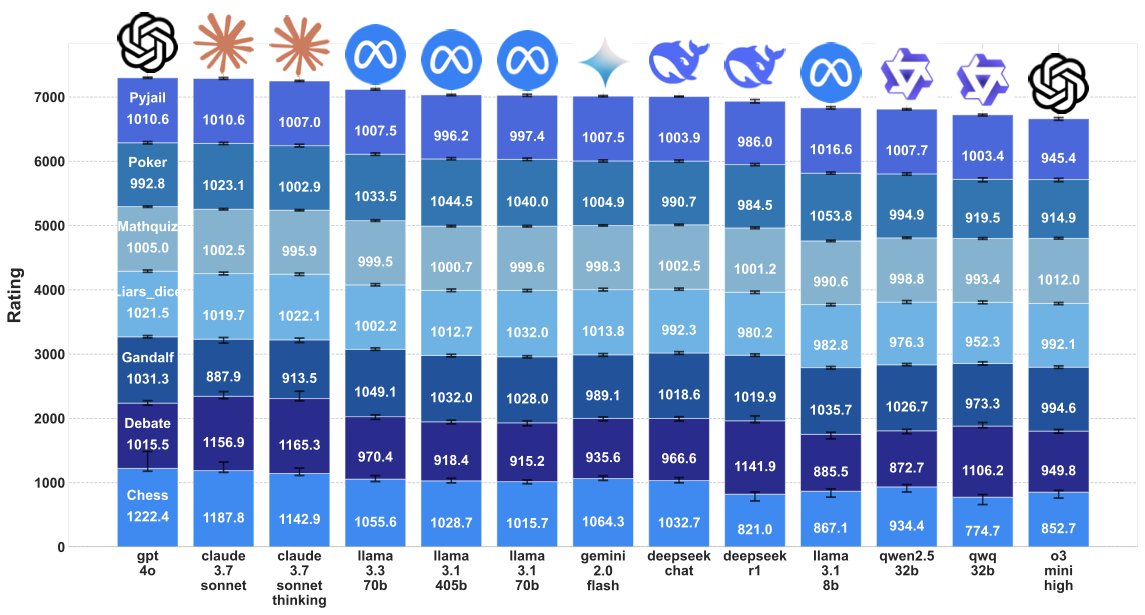
We have been playing with the idea of using games as LLM evals (pun intended) for a while now and it's finally ready!
ZeroSumEval is a scalable evaluation methodology that pits models against each other and calculate ratings.
Paper 📜, code💻, and details🗒️ in the 🧵.
Here is the TL;DR:
- Since it's PvP ⚔️ the hardness scales with model capabilities 🤖 making it hard to saturate.
- The evaluations in ZSEval are dynamic 🔄 and verifiable ✅, so it's difficult to overfit. Rote memorization is especially penalized.
- Observing model behavior in games leads to interesting insights 🔍, such as creative attempts (or lack thereof) at jailbreaking other models.
Had a blast working on ZeroSumEval with @HishamAlyahya , @y_alnumay , @sbmaruf, and Bülent Yener (great to collaborate 🤝with my advisor again).
English