Sabitlenmiş Tweet

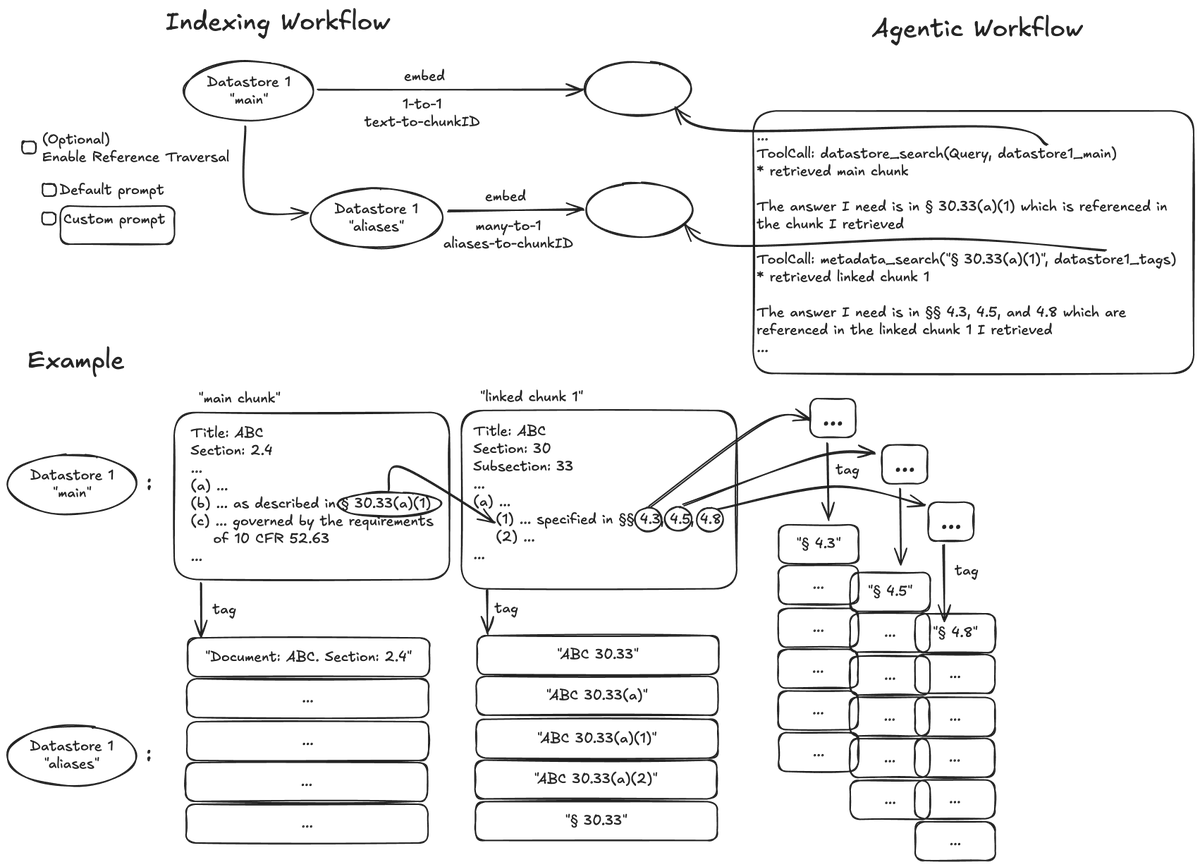
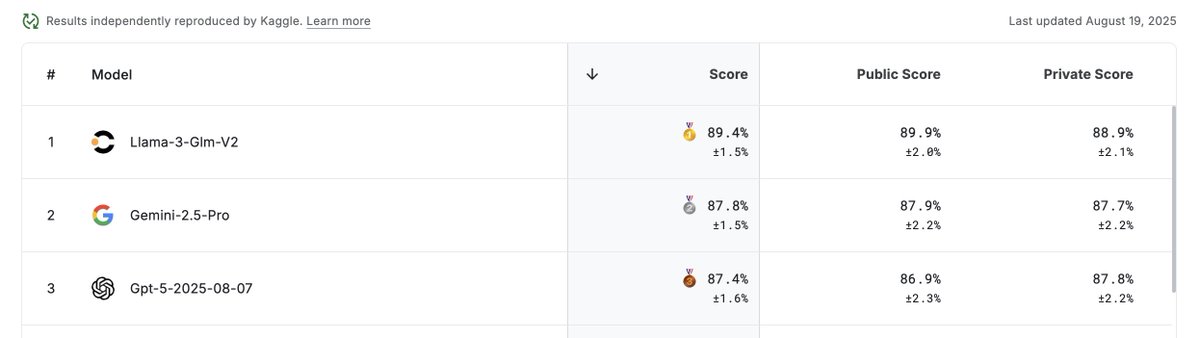
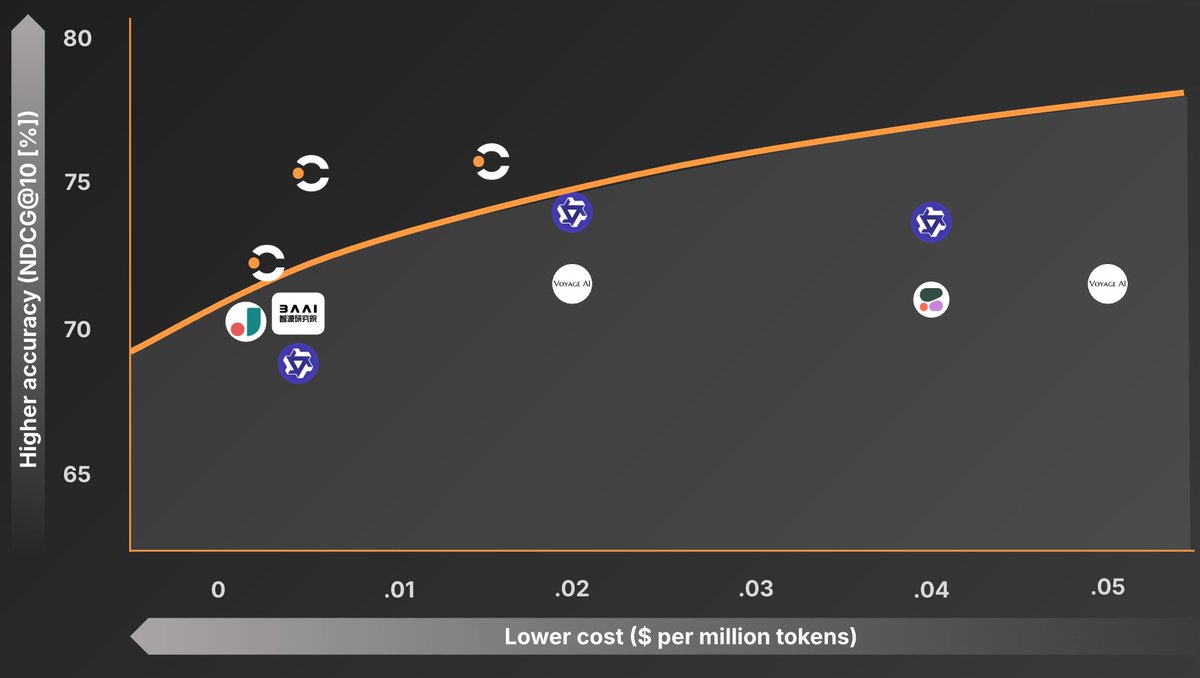
Excited to share that we trained rerankers at the cost/performance frontier and are open sourcing them!
Contextual AI Reranker v2
🚀 Best performing, most efficient reranker
🤗 Open weights (1B, 2B, 6B)
🫡 Instruction-following (including recency-awareness)
🌐 Multilingual
1/4
English