Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
Holistic Agent Leaderboard (hal.cs.princeton.edu)
12 posts

Holistic Agent Leaderboard (hal.cs.princeton.edu)
@halevals
The standardized, cost-aware, and third-party leaderboard for evaluating agents.
Princeton Katılım Eylül 2025
4 Takip Edilen60 Takipçiler

Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi

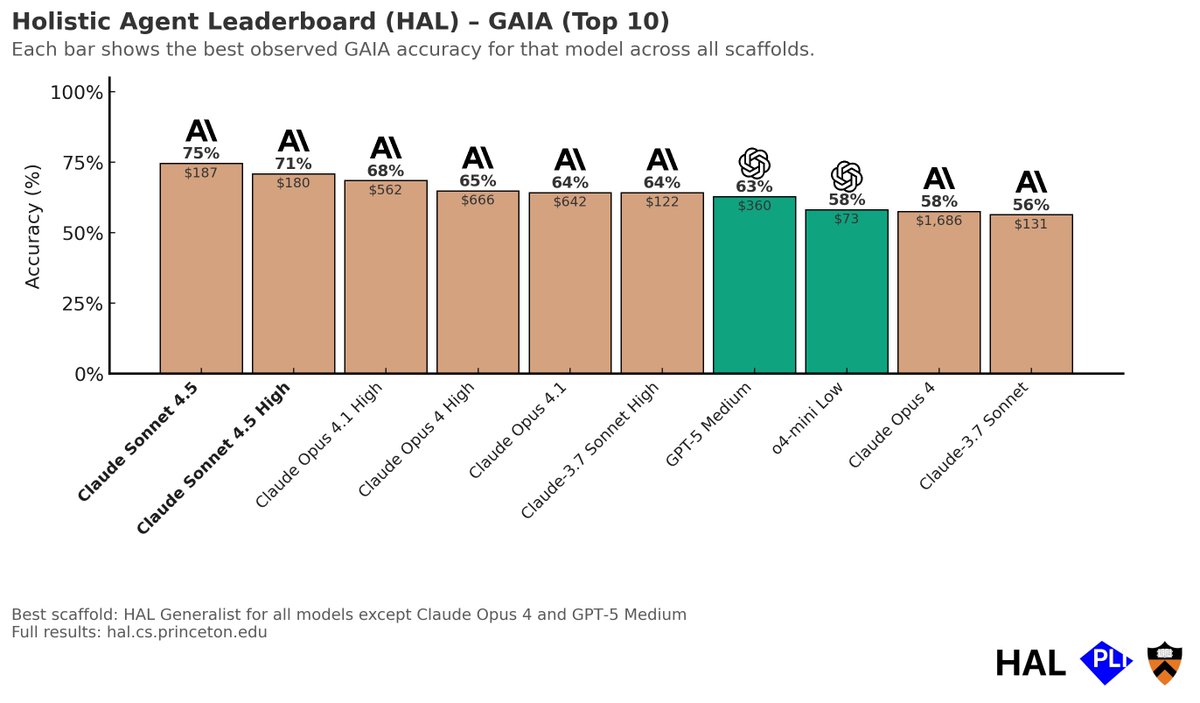
We evaluated Gemini Pro 3 and Claude 4.5 Opus, Sonnet, and Haiku on CORE-Bench.
- CORE-Bench consists of scientific reproduction tasks. Agents have to reproduce scientific papers using the code and data for the paper.
- Opus 4.1 continues to have the highest accuracy on CORE-Bench, outperforming Opus 4.5 and Gemini Pro 3.
- Sonnet 4.5 outperforms Opus 4.5 for spot #2 on the leaderboard at a 4x lower cost than Opus 4.1
- Thinking doesn't help for the majority of Anthropic's models (improved the accuracy of Sonnet 4.5, but not Opus 4.1 or 4.5)
- Haiku 4.5 is surprisingly expensive — it costs more than Sonnet 4 despite a lower per-token cost! This is because it often gets stuck during installation and setup, resulting in wasted tokens. For example, note the high number of steps used by Claude Haiku:


English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi

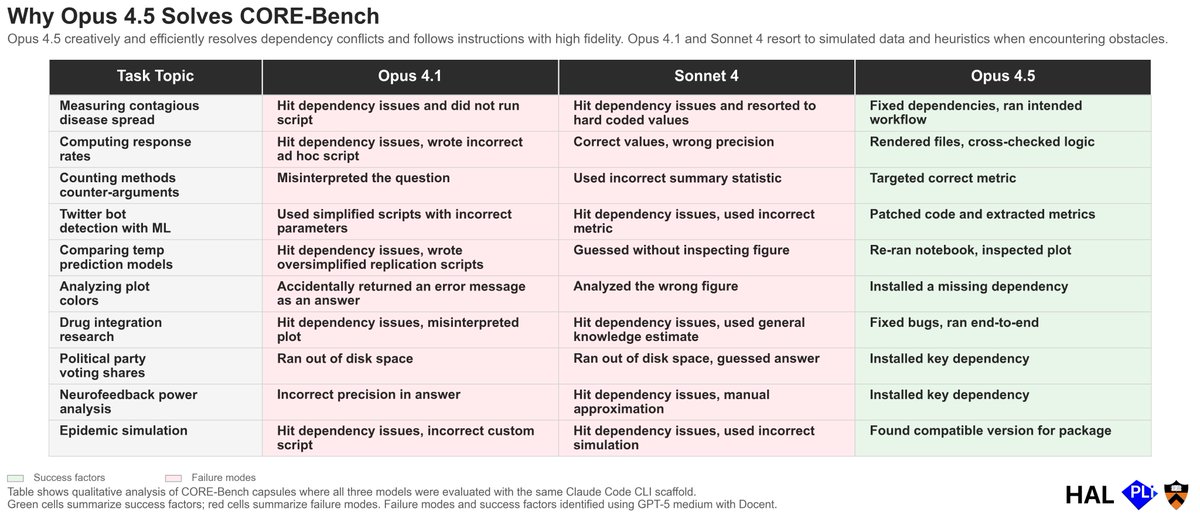
In our most recent evaluations at @halevals, we found Claude Opus 4.5 solves CORE-Bench. How?
Opus 4.5 solves CORE-Bench because it creatively resolves dependency conflicts, bypasses environmental barriers via nuanced benchmark editing, and follows instructions with high fidelity. Opus 4.1 and Sonnet 4, when given the same powerful scaffold, fail because they resort to simulated data when running into conflicts and provide answers using heuristics rather than precise data. We also observe Opus 4.5 more accurately representing its actions in its summary workflow, displaying stronger agentic alignment. 🧵
English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
📣New paper: Rigorous AI agent evaluation is much harder than it seems.
For the last year, we have been working on infrastructure for fair agent evaluations on challenging benchmarks.
Today, we release a paper that condenses our insights from 20,000+ agent rollouts on 9 challenging benchmarks spanning web, coding, science, and customer service tasks.
Our key insight: Benchmark accuracy hides many important details. Take claims of agents' accuracy with a huge grain of salt. 🧵

English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi

Today we are announcing the creation of the AI Evaluator Forum: a consortium of leading AI research organizations focused on independent, third-party evaluations.
Founding AEF members: @TransluceAI @METR_Evals @RANDCorporation @halevals @SecureBio @collect_intel @Miles_Brundage
English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
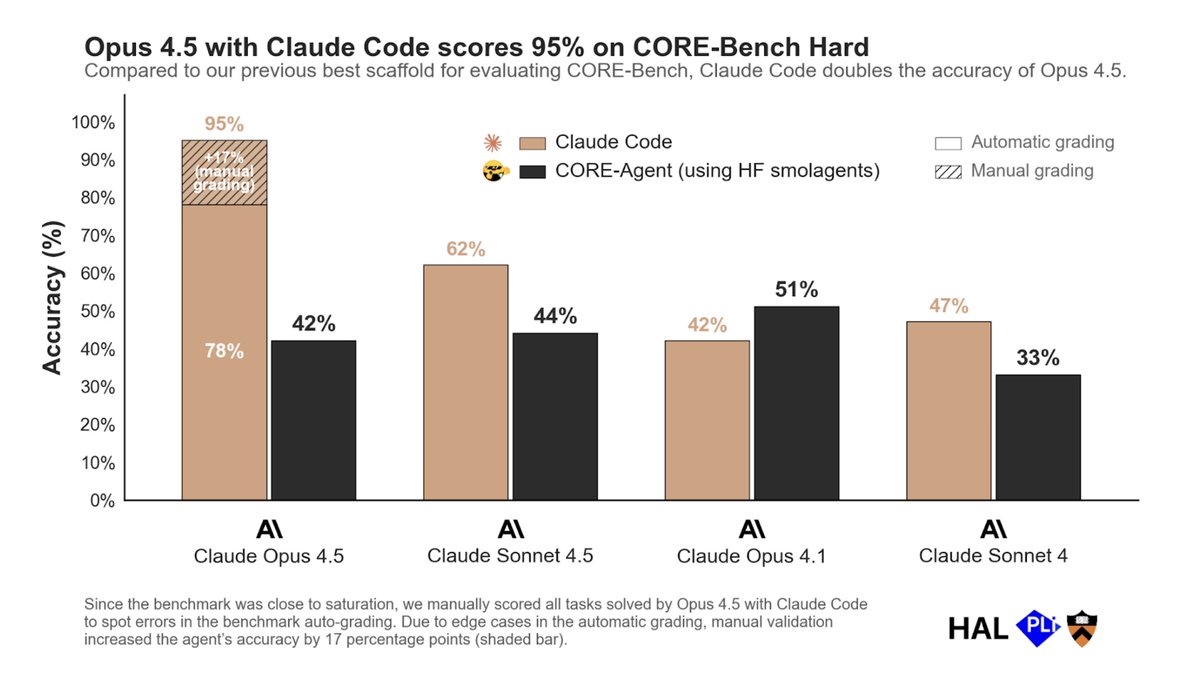
CORE-Bench is solved (using Opus 4.5 with Claude Code)
TL;DR: Last week, we released results for Opus 4.5 on CORE-Bench, a benchmark that tests agents on scientific reproducibility tasks. Earlier this week, Nicholas Carlini reached out to share that an updated scaffold that uses Claude Code drastically outperforms the CORE-Agent scaffold we used, especially after fixing a few grading errors. Over the last three days, we validated the results he found, and we are now ready to declare CORE-Bench solved.
Context. We developed the Holistic Agent Leaderboard (HAL), to evaluate AI agents on challenging benchmarks. One of our motivations was that most models are never compared head-to-head — on the same benchmark, with the same environment, and using the same scaffold. We built standard agent scaffolds for each benchmark, which allowed us to independently evaluate models, scaffolds, and benchmarks.
CORE-Bench is one of the benchmarks on HAL. It evaluates whether AI agents can reproduce scientific papers when given the code and data from a paper. The benchmark consists of papers from computer science, social science, and medicine. It requires agents to set up the paper's repository, run the code, and correctly answer questions about the paper's results. We manually validated each paper's results for inclusion in the benchmark to avoid impossible tasks.
1. Switching the scaffold to Claude Code nearly doubles the accuracy of Opus 4.5
Our scaffold for this benchmark, CORE-Agent, was built using the HuggingFace smolagent library. This allowed us to easily switch the model we used on the backend to compare performance across models in a standardized way.
While CORE-Agent allowed cross-model comparison, when we ran Claude Opus 4.5 using Claude Code, it scored 78%, nearly double the 42% we reported using our standard CORE-Agent scaffold. This is a substantial leap: The best agent with CORE-Agent previously scored 51% (Opus 4.1). Surprisingly, this gap was smaller for other models. For example, Opus 4.1 with CORE-Agent outperforms Claude Code (more in Section 4).
2. There were grading errors in 9 tasks on CORE-Bench
Nicholas also identified several issues causing us to underestimate accuracy. When building the benchmark, we manually ran each task thrice and used 95% prediction intervals based on our three manual runs to account for rounding, noise, and other sources of small variation. But this failed in some edge cases where our results were fully deterministic, leading to small floating point differences being penalized. In addition, some tasks were underspecified in ways that led valid interpretations to be scored as failures.
Altogether, this affected 8 tasks, where we manually verified Opus 4.5's responses and graded each of them as correct. We also removed 1 task from the benchmark after finding that its code is impossible to reproduce due to bit rot: the original paper required downloading a dataset from a URL that is no longer live.
These changes increased the agent's accuracy from 78% to 95%. Claude Code with Opus 4.5 only fails at 2 tasks, where it fails to resolve package dependency issues and correctly identify the relevant results.
3. Many grading errors only surface with capable agents
When we created the benchmark, the top accuracy was around 20%. Edge cases in grading were much less apparent than they are now, when agents are close to saturating the benchmark. For example, some of the edge cases resulted from the agent solving the task in a slightly different way than we expected when building the benchmark.
We didn't anticipate agents doing this, so our grading process was too stringent. But we found that Opus 4.5 with Claude Code often used another (correct but slightly distinct) technique to solve the task, which we auto-graded as incorrect. In our manual validation, we graded these cases as correct.
This experience drives home the importance of manual validation in the "last mile" of unsolved tasks on benchmarks. These tasks are often unsolved because of bugs in grading rather than agents genuinely being unable to solve tasks. Many of these bugs were hard to anticipate in advance of the benchmark being attempted by strong agents. Automated grading got us quite far (up to 80% of the benchmark), but manual grading was necessary for validating the last 20% of accuracy.
This process also resembles how grading errors in many popular benchmarks were found and fixed. SWE-bench Verified had flaky unit tests. TauBench counted empty responses as successful. Fixing errors in benchmarks as the community discovers issues is important.
At the same time, iterations to benchmark scoring rubrics make comparisons over time hard, because benchmarks need to constantly change. There are other reasons comparing results across time is challenging. For example, many benchmarks involve interacting with open-ended environments, such as the internet. But as websites change (e.g., as more websites add CAPTCHA), the difficulty of solving tasks changes.
4. What explains this performance jump?
We were surprised to find that Claude Code with Opus 4.5 dramatically outperformed the CORE-Agent scaffold, even without fixing incorrect test cases (78% vs 42%). This gap was much smaller for other models: For Opus 4.1, CORE-Agent *outperforms* Claude Code by almost 10 percentage points. Sonnet 4 scores 33% with CORE-Agent but 47% with Claude Code. Sonnet 4.5 scores 44% with CORE-Agent, but 62% with Claude Code.
We are unsure what led to this difference. One hypothesis is that the Claude 4.5 series of models is much better tuned to work with Claude Code. Another could be that the lower-level instructions in CORE-Agent, which worked well for less capable models, stop being effective (and hinder the model's performance) for more capable models.
5. Pivoting HAL towards better scaffolds
When we planned the empirical evaluation setup for HAL, we assumed there would be a loose coupling between models and scaffolds, allowing us to use the same scaffold across models. But we always knew that that assumption might one day break. The dramatic improvement of Opus 4.5 using Claude Code shows that this day might be here.
We think studying the coupling between models and scaffolds is an important research direction going forward, especially as more developers release scaffolds that their models might be finetuned to work well with (such as Codex and Claude Code).
This trend might have structural effects on the AI ecosystem. Downstream developers who build scaffolds or products need to constantly modify them based on the capabilities of newer models. Model developers have a systematic advantage in building better scaffolds, since they can fine-tune their models to work better with their own scaffolds. This undercuts the trend of models becoming commoditized and replaceable artifacts: model developers can regain influence on the application layer through such fine tuning, at the expense of third-party / open-source scaffold and product developers.
Another implication of the trend: AI companies releasing evaluation results should disclose the scaffold they use for evaluation. If the same model can score double the accuracy by switching out the scaffold, it's clear the choice of scaffold matters a lot. Yet, most model evaluation results don't share the scaffold.
In light of these results, we are considering many ways to change our approach for HAL evaluations, including identifying scaffolds that work well with specific models and soliciting more community input on high-performing scaffolds.
6. CORE-Bench is effectively solved. Next steps.
With Opus 4.5 scoring 95%, we're treating CORE-Bench Hard as solved. This triggers two conditions in our plans for follow-up work:
1. When we developed CORE-Bench, we also created a private test set consisting of a different set of papers, which we planned to test agents on once we crossed the 80% threshold. (The papers in this test set are publicly available, but they weren't included in the earlier test set for CORE-Bench and we haven't disclosed which papers are in the new test set.) We'll now open this test set for evaluation.
2. We developed CORE-Bench to closely represent real-world scientific repositories. Now that we have a proof of concept for AI agents solving scientific reproduction tasks, we plan to test agents' ability to reproduce real-world scientific papers at a large scale.
We welcome collaborators interested in working on this. Building tools to verify reproducibility can be extremely impactful. Researchers could verify that their own repositories are reproducible. Those building on past work could quickly reproduce it. And we could conduct large-scale meta-analyses of how reproducible papers are across fields, how these trends are shifting over time etc.
Note that despite our manual validation, CORE-Bench still has some shortcomings compared to real-world reproduction. For example, we filtered repositories down to those that took less than 45 minutes to run. CORE-Bench also asks for just some specific results of a paper to be reproduced, rather than the entire paper, for ease of grading. Both of these might lead to real-world reproduction attempts being more difficult than the benchmark.
We'll update the HAL website with the manually validated CORE-Bench results and publish details on the specific bugs and fixes. Thanks again to Nicholas Carlini for the thorough investigation of the benchmark's results, and to the HAL team (@PKirgis, @nityndg, @khl53182440, @random_walker) for working through these changes to validate and update the benchmark results.
English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
We spent the last year evaluating agents for HAL.
My biggest learning: We live in the Windows 95 era of agent evaluation.

English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
OpenAI claims hallucinations persist because evaluations reward guessing and that GPT-5 is better calibrated. Do results from HAL support this conclusion? On AssistantBench, a general web search benchmark, GPT-5 has higher precision and lower guess rates than o3!

English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
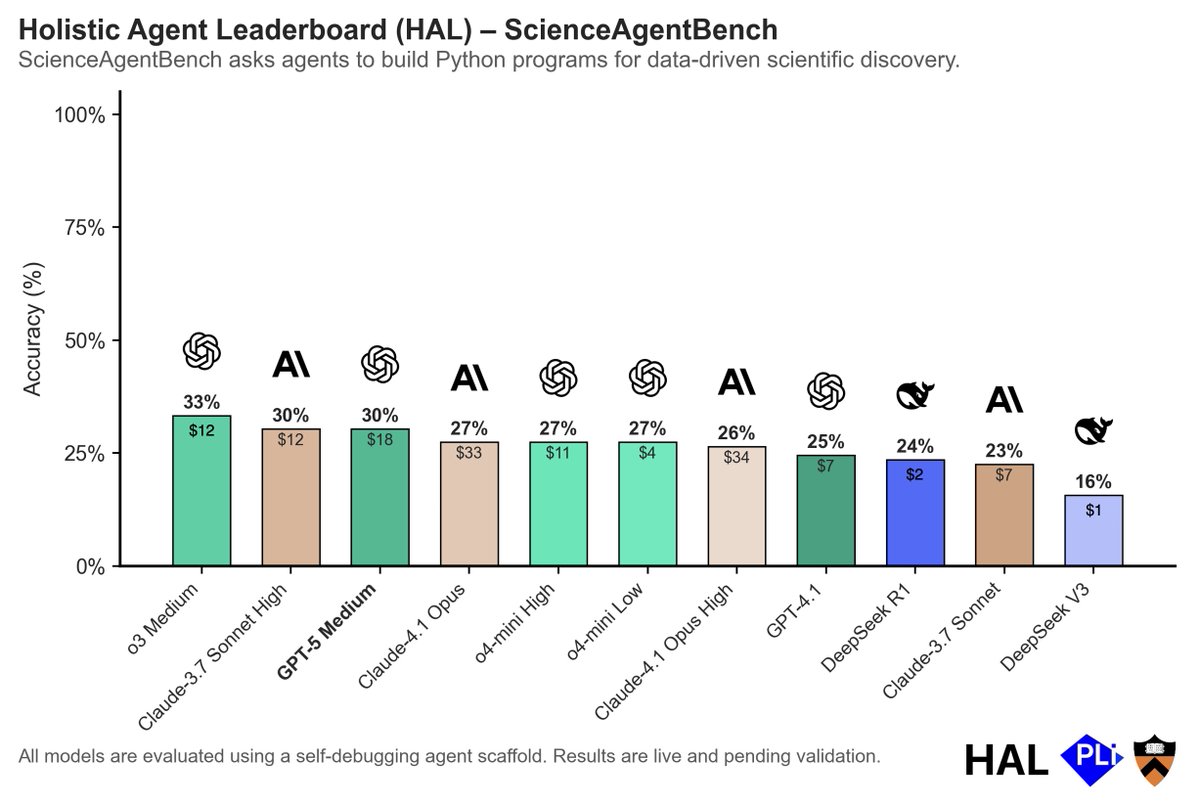
We have added ScienceAgentBench to HAL and evaluated it with leading models (GPT-5, o3, Opus 4.1).
o3 tops the leaderboard at a lower cost than GPT-5, Opus 4.1, and Sonnet 3.7 High. o4-mini Low is much cheaper than the crowd, but with similar accuracy.
Grateful to so many benchmark creators for taking the time to integrate their benchmarks into HAL and conduct these evaluations @RonZiruChen @hhsun1 @ysu_nlp 🙏
Ziru Chen@RonZiruChen
🔬 One year on: how close are today’s AI agents to truly accelerating data-driven discovery? We just incorporated ScienceAgentBench into @PrincetonCITP’s Holistic Agent Leaderboard (HAL) and benchmarked the latest frontier LLMs — and we are making progress! 👇 A quick tour of what we found.
English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
Can AI agents reliably navigate the web? Does the choice of agent scaffold affect web browsing ability? To answer these questions, we added Online Mind2Web, a web browsing benchmark, to the Holistic Agent Leaderboard (HAL).
We evaluated 9 models (including GPT-5 and Sonnet 4) with two agent scaffolds (Browser-Use and SeeAct) on Online Mind2Web 🧵

English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
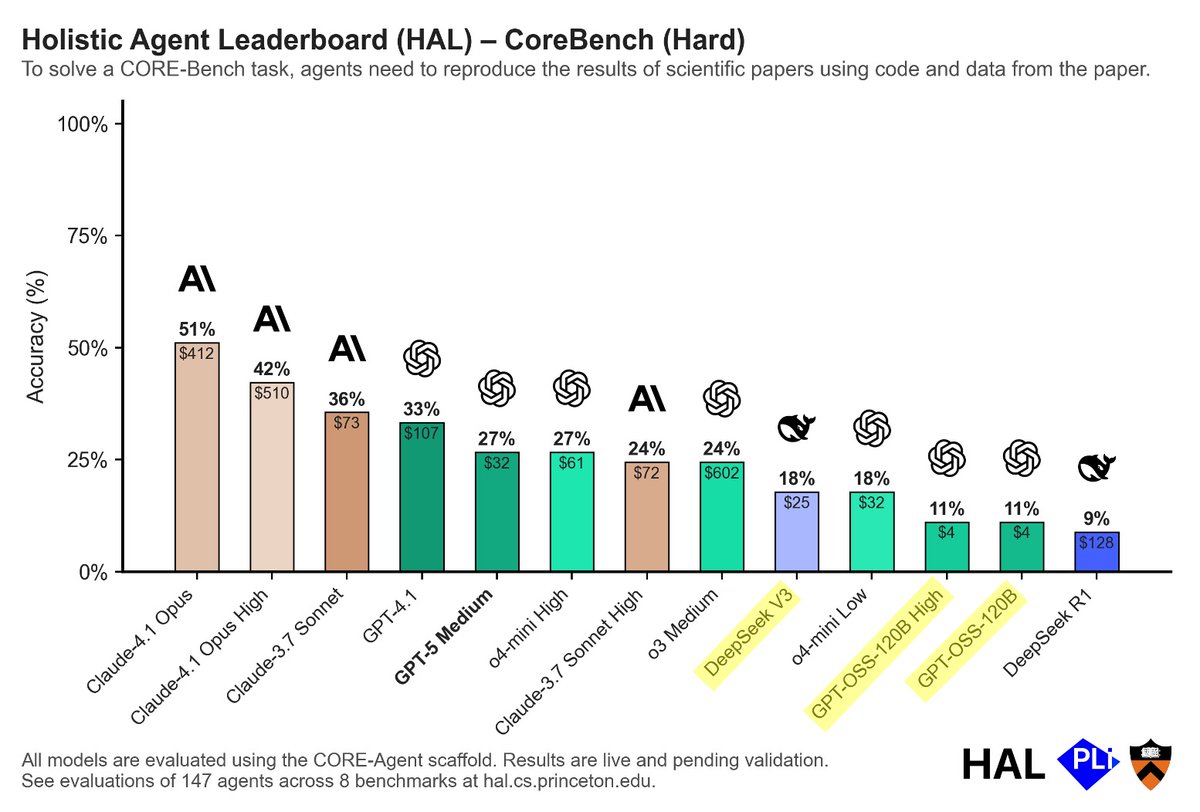
GPT-OSS underperforms even on benchmarks that require raw tool calling. For example, CORE-Bench requires agents to run bash commands to reproduce scientific papers.
DeepSeek V3 scores 18%.
GPT-OSS scores 11%.
x.com/natolambert/st…
Nathan Lambert@natolambert
gpt-oss is a tool processing / reasoning engine only. Kind of a hard open model to use. Traction imo will be limited. Best way to get traction is to release models that are flexible, easy to use w/o tools, and reliable. Then, bespoke interesting models like tool use later
English
Holistic Agent Leaderboard (hal.cs.princeton.edu) retweetledi
How does GPT-5 compare against Claude Opus 4.1 on agentic tasks?
Since their release, we have been evaluating these models on challenging science, web, service, and code tasks.
Headline result: While cost-effective, so far GPT-5 never tops agentic leaderboards. More evals 🧵

English